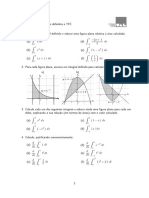
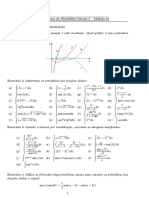
Anda mungkin juga menyukai
- Aula-5 Integrais ComplexasDokumen21 halamanAula-5 Integrais ComplexasSérgio Reis FernandesBelum ada peringkat
- Cap2 TransformadazDokumen15 halamanCap2 TransformadazwilsonBelum ada peringkat
- Variaveis Complexas Integral Complexa - PDF CdeKey CLNJUUILUUT6ZKDCGZFJPSKCIIPTTNJDDokumen25 halamanVariaveis Complexas Integral Complexa - PDF CdeKey CLNJUUILUUT6ZKDCGZFJPSKCIIPTTNJDMarlosBelum ada peringkat
- Tabela de Transformada Z LaplaceDokumen1 halamanTabela de Transformada Z LaplaceVinny Tuk0% (1)
- Trabalho TFVC (JQCumbe)Dokumen5 halamanTrabalho TFVC (JQCumbe)Denny RichBelum ada peringkat
- Introducao Ao Controle DigitalDokumen29 halamanIntroducao Ao Controle DigitaltecnicowagnerBelum ada peringkat
- Exercise 2 Jeemain - GuruDokumen1 halamanExercise 2 Jeemain - GuruYannick KassiaBelum ada peringkat
- Exp2 PIDDokumen11 halamanExp2 PIDJoseilton SouzaBelum ada peringkat
- Aula8 (07) 1Dokumen14 halamanAula8 (07) 1marcela_portelaBelum ada peringkat
- Transformada Z ListaDokumen5 halamanTransformada Z ListaCesarSoeiroBelum ada peringkat
- Reducibles A Variable Separable - SolucionarioDokumen3 halamanReducibles A Variable Separable - SolucionarioF AGBelum ada peringkat
- Alíneas Do Exercício 50 Resolvidas Ou Começadas A 03/04 de Janeiro de 2022Dokumen4 halamanAlíneas Do Exercício 50 Resolvidas Ou Começadas A 03/04 de Janeiro de 2022Camila CarvalhoBelum ada peringkat
- Transformada ZDokumen3 halamanTransformada Zgh.gabriel2009Belum ada peringkat
- Lista Cálculo E (3A) - Integrais de Contorno (Linha)Dokumen3 halamanLista Cálculo E (3A) - Integrais de Contorno (Linha)Lucas PereiraBelum ada peringkat
- Crunk NicolsonDokumen7 halamanCrunk NicolsonMatheus Castro SilvaBelum ada peringkat
- Lista1 FisMat1Dokumen2 halamanLista1 FisMat1marcella4idalyneBelum ada peringkat
- Modelos MatemáticosDokumen5 halamanModelos MatemáticosRafaela NunesBelum ada peringkat
- Pro Inte DeriDokumen3 halamanPro Inte DeriGuilherme OzanskiBelum ada peringkat
- EEL 7052 - Prova 1Dokumen4 halamanEEL 7052 - Prova 1Gabriel GoulartBelum ada peringkat
- Seção 14.3Dokumen2 halamanSeção 14.3Angelina LopesBelum ada peringkat
- Listona de IntegraisDokumen5 halamanListona de IntegraisEmerson BatistaBelum ada peringkat
- 1°lista Emerson LimaDokumen4 halaman1°lista Emerson LimaHugo NascimentoBelum ada peringkat
- Lista 3 Variáveis Complexas - 2023.2Dokumen3 halamanLista 3 Variáveis Complexas - 2023.2Joaquim GregórioBelum ada peringkat
- EP1 GabaritoDokumen14 halamanEP1 GabaritoErika Santos RibeiroBelum ada peringkat
- Lista 211004 162928Dokumen16 halamanLista 211004 162928Gabriel Silva SantosBelum ada peringkat
- Lista 3Dokumen2 halamanLista 3Jose Augusto Gomes FurlaniBelum ada peringkat
- Analise HarminicaDokumen4 halamanAnalise HarminicaJoaquim Mateus ZamboBelum ada peringkat
- IntegralDokumen19 halamanIntegralAbdi ShukuruBelum ada peringkat
- Engenharia de Controle II 2a Avaliacao IncompletoDokumen13 halamanEngenharia de Controle II 2a Avaliacao IncompletoMarcos RibeiroBelum ada peringkat
- 3 TabelaDokumen2 halaman3 TabelaLucas SouzaBelum ada peringkat
- ALista20 - Integrais TrigonometricasDokumen2 halamanALista20 - Integrais Trigonometricasana luisaBelum ada peringkat
- Lista 5Dokumen1 halamanLista 5Lucas SilveiraBelum ada peringkat
- GabaritoDokumen16 halamanGabaritoCirilo SantosBelum ada peringkat
- Solution Cap 2 Mecanica Analitica Nivaldo LemosDokumen12 halamanSolution Cap 2 Mecanica Analitica Nivaldo LemosJoao JúniorBelum ada peringkat
- 16 01 2023 - CorreccaoDokumen2 halaman16 01 2023 - CorreccaoCamila CarvalhoBelum ada peringkat
- Lista 1Dokumen2 halamanLista 1Jose Augusto Gomes FurlaniBelum ada peringkat
- Psub GabDokumen4 halamanPsub Gabroberto.palmaBelum ada peringkat
- Cb0642 Varriáveis ComplexasDokumen2 halamanCb0642 Varriáveis ComplexasDuda MendesBelum ada peringkat
- Complex 3Dokumen32 halamanComplex 3mecketreffi3268Belum ada peringkat
- Apostila Controle Digital PDFDokumen32 halamanApostila Controle Digital PDFFabio AmorimBelum ada peringkat
- FTII - Difusão de Electrólitos e em SólidosDokumen30 halamanFTII - Difusão de Electrólitos e em Sólidosrui.azevedo2003Belum ada peringkat
- 8 IntegraisDokumen1 halaman8 IntegraisBeatriz LuísBelum ada peringkat
- Com Var&Lin AlgebraDokumen17 halamanCom Var&Lin AlgebraPawan PatroBelum ada peringkat
- AD2 CIII 2019 2 GabaritoDokumen2 halamanAD2 CIII 2019 2 GabaritosusanaBelum ada peringkat
- Prova 1 de Cálculo 3Dokumen1 halamanProva 1 de Cálculo 3MATHEUS FORTUNATO DARIOBelum ada peringkat
- An Alise Complexa: Universidade Do Minho Departamento de Matem AticaDokumen1 halamanAn Alise Complexa: Universidade Do Minho Departamento de Matem AticaCamila CarvalhoBelum ada peringkat
- Lista 93214Dokumen29 halamanLista 93214samuellmillioleBelum ada peringkat
- Lista - 3 - Metodos MatematicosDokumen4 halamanLista - 3 - Metodos MatematicosCarlos augusto LeaoBelum ada peringkat
- Lista 5 Integral Calculo - ElétricaDokumen12 halamanLista 5 Integral Calculo - ElétricaAdreX OfcBelum ada peringkat
- List6 2023 UspDokumen8 halamanList6 2023 UspAnderson AquilesBelum ada peringkat
- 3° Prova Modelagem 2023 - 1Dokumen3 halaman3° Prova Modelagem 2023 - 1Prof. Eduardo NunesBelum ada peringkat
- Slides 01 Sist Tempo Discreto Parte1Dokumen32 halamanSlides 01 Sist Tempo Discreto Parte1Cecília de Freitas MoraisBelum ada peringkat
- Cad C4 Tarefa 37-38Dokumen32 halamanCad C4 Tarefa 37-38Amon Lemes Dos SantosBelum ada peringkat
- EXECAULA20191106Dokumen3 halamanEXECAULA20191106LorenaBelum ada peringkat
- Numeros ComplexosDokumen8 halamanNumeros ComplexosFR4UD3Belum ada peringkat
- SSL Formulario Geral 2019 PDFDokumen3 halamanSSL Formulario Geral 2019 PDFpaula_prata6316Belum ada peringkat
- Números ComplexosDokumen3 halamanNúmeros ComplexosAna Margarida Ribeiro Da Silva AlunoBelum ada peringkat
- Lista1 (Coordenada)Dokumen3 halamanLista1 (Coordenada)Rafael AbbudBelum ada peringkat
- Aula2 SCII2010Dokumen21 halamanAula2 SCII2010Alexandre PaesBelum ada peringkat
- 1059-Article Text-3769-1-10-20201217Dokumen8 halaman1059-Article Text-3769-1-10-20201217Marcelo Flavio GuepfrihBelum ada peringkat
- Cap 4 PDFDokumen93 halamanCap 4 PDFGilson JuniorBelum ada peringkat
- Cap 4 PDFDokumen93 halamanCap 4 PDFGilson JuniorBelum ada peringkat
- Cap 4 PDFDokumen93 halamanCap 4 PDFGilson JuniorBelum ada peringkat
- Cap 4 PDFDokumen93 halamanCap 4 PDFGilson JuniorBelum ada peringkat
- Eletr Pot1 12Dokumen22 halamanEletr Pot1 12Eduardo MirandaBelum ada peringkat
- Prof. Ivo - Tarefa220101Dokumen5 halamanProf. Ivo - Tarefa220101Marcelo Flavio GuepfrihBelum ada peringkat
- Lagrangeano - 42965Dokumen7 halamanLagrangeano - 42965Marcelo Flavio GuepfrihBelum ada peringkat
- Rvol 18 No 3 P 22Dokumen8 halamanRvol 18 No 3 P 22Marcelo Flavio GuepfrihBelum ada peringkat
- Historia de Nikola TeslaDokumen113 halamanHistoria de Nikola TeslaMarcelo Flavio GuepfrihBelum ada peringkat
- Ionização e Dissociação Iónica. Autoionização Da ÁguaDokumen24 halamanIonização e Dissociação Iónica. Autoionização Da ÁguaAna Celia MendesBelum ada peringkat
- Lista de Integrais Resolvidas PDFDokumen5 halamanLista de Integrais Resolvidas PDFWedson OliveiraBelum ada peringkat
- Lista Analise 5Dokumen7 halamanLista Analise 5Victor NascimentoBelum ada peringkat
- Q11 - Titulacao Acido-BaseDokumen9 halamanQ11 - Titulacao Acido-BaseOlá AdeusBelum ada peringkat
- 07 Radiciação PDFDokumen5 halaman07 Radiciação PDFJuan VictorBelum ada peringkat
- NBR 5428 (Jan 1985) - Procedimentos Estatísticos para Determinação Da Validade de Inspeção Por Atributos Feita Pelos FornecedoresDokumen23 halamanNBR 5428 (Jan 1985) - Procedimentos Estatísticos para Determinação Da Validade de Inspeção Por Atributos Feita Pelos FornecedoresYuri Bahia de Vasconcelos100% (3)
- Problema de Dirichet No Circulo e em Regiões Circulares PDFDokumen8 halamanProblema de Dirichet No Circulo e em Regiões Circulares PDFMauricio Henrique da SilvaBelum ada peringkat
- Aula 06 - Radier PDFDokumen34 halamanAula 06 - Radier PDFAnonymous iIACZpcRgwBelum ada peringkat
- DerivadaDokumen76 halamanDerivadaGabriel MathiasBelum ada peringkat
- VolumetrianeutralizaDokumen62 halamanVolumetrianeutralizaRobinsonPereiraBelum ada peringkat
- Apostila - UFF Metodos NumericosDokumen160 halamanApostila - UFF Metodos NumericoswendelciprianoBelum ada peringkat
- PolinómiosvvvvDokumen11 halamanPolinómiosvvvvdedoBelum ada peringkat
- Cronograma - Teoria Psicanal+åticaDokumen3 halamanCronograma - Teoria Psicanal+åticaDankpsikoBelum ada peringkat
- Estatística ModaDokumen2 halamanEstatística ModamsnyesBelum ada peringkat
- Geometria Simplectica PDFDokumen95 halamanGeometria Simplectica PDFDoug BuzziBelum ada peringkat
- 11 - CapabilidadeDokumen30 halaman11 - CapabilidadeJose Guimaraes100% (1)
- Fundamentos de Analise IIDokumen110 halamanFundamentos de Analise IIRicardinhorick100% (2)
- PesquisaDokumen10 halamanPesquisaGabrielle GomesBelum ada peringkat
- Aula 3 - Testes de Hipoteses.Dokumen7 halamanAula 3 - Testes de Hipoteses.Nilto MassangoBelum ada peringkat
- Calculo IntegralDokumen3 halamanCalculo Integralkratos uzumakiBelum ada peringkat
- Função - Parte 1 (Definição e Notação) - Prof. Silvano ReisDokumen6 halamanFunção - Parte 1 (Definição e Notação) - Prof. Silvano ReisSilvano Reis50% (2)
- Problemas Com o Formato Dos Picos em Cromatografi A LíquidaDokumen7 halamanProblemas Com o Formato Dos Picos em Cromatografi A LíquidaHevertonJonnysBelum ada peringkat
- Lista 2 SériesDokumen3 halamanLista 2 SériesMarcos EduardoBelum ada peringkat
- UD VI - Derivadas Parciais e Integrais DuplasDokumen28 halamanUD VI - Derivadas Parciais e Integrais DuplasValter ClaroBelum ada peringkat
- Taboas, Calculo Diferencial e Integral Na Reta, Notas de AulaDokumen120 halamanTaboas, Calculo Diferencial e Integral Na Reta, Notas de AulaPTC manBelum ada peringkat
- Simulado Estastistica e ProbabilidadeDokumen1 halamanSimulado Estastistica e ProbabilidadeRonaldo CarvalhoBelum ada peringkat
- Plano de Ensino - Métodos e Ferramentas Da QualidadeDokumen3 halamanPlano de Ensino - Métodos e Ferramentas Da QualidadeDouglas MelmanBelum ada peringkat
- PE 2011 Métodos QuantitativosDokumen4 halamanPE 2011 Métodos QuantitativosAdriano BelucoBelum ada peringkat