Anda mungkin juga menyukai
- Chapter 2-Lexical AnalysisDokumen31 halamanChapter 2-Lexical Analysismishamoamanuel574Belum ada peringkat
- ExpressionDokumen9 halamanExpressionSBRKA0% (1)
- Unit 3.-Finite Automatic: 3.1 Concepts: Definition and Classification of Finite Automata (AF) - Definition 1Dokumen22 halamanUnit 3.-Finite Automatic: 3.1 Concepts: Definition and Classification of Finite Automata (AF) - Definition 1jairo alonso parraBelum ada peringkat
- VTU 21CS51 ATC Module 1 Automata PartDokumen35 halamanVTU 21CS51 ATC Module 1 Automata PartAditya PaulBelum ada peringkat
- Toa Ass3 FinalDokumen5 halamanToa Ass3 FinalMaria ImranBelum ada peringkat
- Toc Unit-IiDokumen23 halamanToc Unit-IiSamridhi ShreeBelum ada peringkat
- States, Transitions and Finite-State Transition SystemDokumen30 halamanStates, Transitions and Finite-State Transition SystemJoshua KurianBelum ada peringkat
- Toc PDFDokumen30 halamanToc PDFSmit ThakkarBelum ada peringkat
- Introduction of Theory of ComputationDokumen6 halamanIntroduction of Theory of Computationammaoo7Belum ada peringkat
- Regular AnguageDokumen38 halamanRegular AnguageMohammedBelum ada peringkat
- Automata and Complexity TheoryDokumen18 halamanAutomata and Complexity Theoryfadil Yusuf100% (1)
- Chapter One Introduction To AutomataDokumen28 halamanChapter One Introduction To Automatadejenehundaol91Belum ada peringkat
- Unit - I (Fa)Dokumen20 halamanUnit - I (Fa)kumarBelum ada peringkat
- Handout 9Dokumen9 halamanHandout 9manoBelum ada peringkat
- Toc Unit IDokumen20 halamanToc Unit IanilostaBelum ada peringkat
- Compiler Construction Lecture NotesDokumen27 halamanCompiler Construction Lecture NotesFidelis GodwinBelum ada peringkat
- Flat KJRDokumen19 halamanFlat KJRReenuBelum ada peringkat
- Summary - Intro To The Theory of Computation by Michael SipserDokumen13 halamanSummary - Intro To The Theory of Computation by Michael SipserDaniela NatalBelum ada peringkat
- Transition DiagramDokumen13 halamanTransition Diagramanon_880680691Belum ada peringkat
- Compiler Construction NotesDokumen21 halamanCompiler Construction NotesvinayBelum ada peringkat
- Lesson 11Dokumen38 halamanLesson 11sdfgedr4tBelum ada peringkat
- Finite State Machine: A Finite Automata Consists of FollowingDokumen7 halamanFinite State Machine: A Finite Automata Consists of FollowingRamna SatarBelum ada peringkat
- Compiler Construction Lecture Notes: Why Study Compilers?Dokumen16 halamanCompiler Construction Lecture Notes: Why Study Compilers?jaseregBelum ada peringkat
- Formal Languages CHAPTER-IDokumen11 halamanFormal Languages CHAPTER-IDafuq MaloneBelum ada peringkat
- Finite AutomataDokumen81 halamanFinite Automatakaysayalunana3030Belum ada peringkat
- Unit 1 - Theory of Computation - WWW - Rgpvnotes.inDokumen16 halamanUnit 1 - Theory of Computation - WWW - Rgpvnotes.inAmit TiwariBelum ada peringkat
- FA Transition GraphsDokumen9 halamanFA Transition Graphsadeelmurtaza5730Belum ada peringkat
- The Branch of Computer Science That Deals With How Efficiently The Problem Can Be Solved On A Model of Computation, Using An AlgorithmDokumen9 halamanThe Branch of Computer Science That Deals With How Efficiently The Problem Can Be Solved On A Model of Computation, Using An AlgorithmMohammad saheemBelum ada peringkat
- 2marks For Pondicherry UniversityDokumen45 halaman2marks For Pondicherry UniversityJean ClaudeBelum ada peringkat
- Automata & Complexity Theory Cosc3025: Chapter OneDokumen27 halamanAutomata & Complexity Theory Cosc3025: Chapter Oneabebaw ataleleBelum ada peringkat
- Unit 1Dokumen17 halamanUnit 1hejoj76652Belum ada peringkat
- Unit-2 Introduction To Finite Automata PDFDokumen68 halamanUnit-2 Introduction To Finite Automata PDFnikhillamsal1Belum ada peringkat
- Informal Description: Symbols AlphabetDokumen4 halamanInformal Description: Symbols Alphabetgauravdwivedi2010Belum ada peringkat
- 2 LexicalDokumen7 halaman2 Lexicalyas123100% (1)
- Unit 1Dokumen36 halamanUnit 133 ABHISHEK WAGHBelum ada peringkat
- Automata TheoryDokumen9 halamanAutomata TheoryChristopherLimBelum ada peringkat
- Unit IDokumen21 halamanUnit IK.Jyothi SwaroopBelum ada peringkat
- Study Notes-Theory of ComputationDokumen47 halamanStudy Notes-Theory of ComputationSwarnavo MondalBelum ada peringkat
- Deterministic Finite AcceptorsDokumen4 halamanDeterministic Finite Acceptorssomu6402Belum ada peringkat
- AutomataDokumen5 halamanAutomataRup MBelum ada peringkat
- Toc NOTES - 2Dokumen0 halamanToc NOTES - 2Shefali TomarBelum ada peringkat
- Theory - ComputationDokumen97 halamanTheory - ComputationUmamaheswar PutrevuBelum ada peringkat
- TCS Theory QuestionsDokumen7 halamanTCS Theory QuestionsURVI BALEKUNDRIBelum ada peringkat
- Nondeterministic Finite Automata (NFA) : Multiple Next StateDokumen4 halamanNondeterministic Finite Automata (NFA) : Multiple Next StateSoumodip ChakrabortyBelum ada peringkat
- Chapter 2 DFA and NFADokumen41 halamanChapter 2 DFA and NFAJěhøvāh ŠhāĺømBelum ada peringkat
- Unit 1 - Theory of ComputationDokumen13 halamanUnit 1 - Theory of Computationshivam singhBelum ada peringkat
- CS8501 2marks Q ADokumen19 halamanCS8501 2marks Q AjayashreeBelum ada peringkat
- ALC AnswersDokumen8 halamanALC AnswersAbdul Azeez 312Belum ada peringkat
- CS402 Grand Quiz Mega File Made by Ans Mughal - Files Preparation GroupDokumen71 halamanCS402 Grand Quiz Mega File Made by Ans Mughal - Files Preparation GroupZee50% (2)
- Automata Theory and Formal LangaugeDokumen70 halamanAutomata Theory and Formal LangaugeT VinassaurBelum ada peringkat
- Automata: Theoretical Computer Science Abstract MachinesDokumen7 halamanAutomata: Theoretical Computer Science Abstract MachinesPranjil JosephBelum ada peringkat
- AtoumataDokumen9 halamanAtoumataberiBelum ada peringkat
- CS402 Midterm MCQs 2020 With ReferenceDokumen65 halamanCS402 Midterm MCQs 2020 With ReferenceZeeBelum ada peringkat
- Deterministic Finite AutomataDokumen7 halamanDeterministic Finite Automataاسيا عكاب يوسف زغير صباحيBelum ada peringkat
- Finite Automata: A Simple Computing ModelDokumen53 halamanFinite Automata: A Simple Computing ModelSaima-Amen CommandoBelum ada peringkat
- Affine Transformation: Unlocking Visual Perspectives: Exploring Affine Transformation in Computer VisionDari EverandAffine Transformation: Unlocking Visual Perspectives: Exploring Affine Transformation in Computer VisionBelum ada peringkat
- OOSE Course OutlineDokumen2 halamanOOSE Course OutlinemadhunathBelum ada peringkat
- OOSE Course OutlineDokumen2 halamanOOSE Course OutlinemadhunathBelum ada peringkat
- OOSE Course OutlineDokumen2 halamanOOSE Course OutlinemadhunathBelum ada peringkat
- Software Reuse: CSC 532 Term PaperDokumen11 halamanSoftware Reuse: CSC 532 Term PapermadhunathBelum ada peringkat
- A-Z Windows CMD Commands ListDokumen18 halamanA-Z Windows CMD Commands ListmadhunathBelum ada peringkat
- Software Reuse: CSC 532 Term PaperDokumen11 halamanSoftware Reuse: CSC 532 Term PapermadhunathBelum ada peringkat
- Telecom TechnologyDokumen6 halamanTelecom TechnologymadhunathBelum ada peringkat
- Chapter 9: Concurrency ControlDokumen34 halamanChapter 9: Concurrency Controllogu_thalirBelum ada peringkat
- Mid-Term: Practicable in Their Own WordsDokumen2 halamanMid-Term: Practicable in Their Own WordsmadhunathBelum ada peringkat
- Version Control:: Else If (I%2 1) Write (" ..Red!") Else If (I%2 2) Write (" Blue!") End AnsDokumen3 halamanVersion Control:: Else If (I%2 1) Write (" ..Red!") Else If (I%2 2) Write (" Blue!") End AnsmadhunathBelum ada peringkat
- Syllabus of MECEDokumen22 halamanSyllabus of MECEmadhunathBelum ada peringkat
- Modern English Vocabulary: Acquire To Get Ownership, To Gain Through EffortDokumen22 halamanModern English Vocabulary: Acquire To Get Ownership, To Gain Through EffortmadhunathBelum ada peringkat
- Finite State Machines: Chapter 11 - Sequential CircuitsDokumen12 halamanFinite State Machines: Chapter 11 - Sequential CircuitsmadhunathBelum ada peringkat
- Netework Architecture of 5G Mobile TechnologyDokumen21 halamanNetework Architecture of 5G Mobile Technologymadhunath0% (1)
- Modern English Vocabulary: Acquire To Get Ownership, To Gain Through EffortDokumen49 halamanModern English Vocabulary: Acquire To Get Ownership, To Gain Through EffortmadhunathBelum ada peringkat
- To Collect SFP Information: StepsDokumen2 halamanTo Collect SFP Information: StepsmadhunathBelum ada peringkat
- NotesDokumen458 halamanNotesmadhunathBelum ada peringkat
- Question CGDokumen6 halamanQuestion CGmadhunathBelum ada peringkat
- Chapter 9: Concurrency ControlDokumen34 halamanChapter 9: Concurrency Controllogu_thalirBelum ada peringkat
- 04 TransformDokumen46 halaman04 TransformHarsh SharmaBelum ada peringkat
- Mid-Term Mid-Term: Practicable in Their Own Words. Practicable in Their Own WordsDokumen1 halamanMid-Term Mid-Term: Practicable in Their Own Words. Practicable in Their Own WordsmadhunathBelum ada peringkat
- Ip ConfigDokumen2 halamanIp ConfigmadhunathBelum ada peringkat
- OpenGL SlidesDokumen32 halamanOpenGL SlidesmadhunathBelum ada peringkat
- LTE TutorialDokumen59 halamanLTE TutorialmadhunathBelum ada peringkat
- PGPDokumen21 halamanPGPmadhunathBelum ada peringkat
- Bézier Surface (In 3D) : Paul BourkeDokumen12 halamanBézier Surface (In 3D) : Paul BourkemadhunathBelum ada peringkat
- Question TOCDokumen6 halamanQuestion TOCmadhunathBelum ada peringkat
- 2 Cellular SystemsDokumen17 halaman2 Cellular SystemsmadhunathBelum ada peringkat
- PM Card-20170731 - New LatestDokumen4 halamanPM Card-20170731 - New LatestmadhunathBelum ada peringkat
- Tractor Engine and Drawbar PerformanceDokumen3 halamanTractor Engine and Drawbar PerformancemaureenBelum ada peringkat
- SM 89Dokumen36 halamanSM 89Camilo RamosBelum ada peringkat
- Craig Pirrong-Commodity Price Dynamics - A Structural Approach-Cambridge University Press (2011) PDFDokumen239 halamanCraig Pirrong-Commodity Price Dynamics - A Structural Approach-Cambridge University Press (2011) PDFchengadBelum ada peringkat
- Teacher PPT - Scientific RevolutionDokumen13 halamanTeacher PPT - Scientific Revolutionapi-441776741Belum ada peringkat
- Math10 - Q1 - Mod3 - DeterminingArithmetic - V3 1Dokumen28 halamanMath10 - Q1 - Mod3 - DeterminingArithmetic - V3 1Cristina Amantiad100% (5)
- Yuzuru Hanyu - ThesisDokumen6 halamanYuzuru Hanyu - ThesisFatima Esperanza Ortiz Ortiz100% (4)
- A) I) Define The Term Variable Costs Variable Costs Are Costs That Change With The Quantity of Products SoldDokumen2 halamanA) I) Define The Term Variable Costs Variable Costs Are Costs That Change With The Quantity of Products SoldAleksandra LukanovskaBelum ada peringkat
- 2011 Sample Final ExamDokumen25 halaman2011 Sample Final Examapi-114939020Belum ada peringkat
- Winter Intership SyllabusDokumen14 halamanWinter Intership SyllabusAjayBelum ada peringkat
- Cross-Cultural Validation of The Scales For Outcomes in Parkinson's Disease-Psychosocial Questionnaire (SCOPA-PS) in Four Latin American CountriesDokumen7 halamanCross-Cultural Validation of The Scales For Outcomes in Parkinson's Disease-Psychosocial Questionnaire (SCOPA-PS) in Four Latin American Countriesfozia hayyatBelum ada peringkat
- Transformation To An Agile and Virtualized World: Operations Center of The FutureDokumen1 halamanTransformation To An Agile and Virtualized World: Operations Center of The FuturepinardoBelum ada peringkat
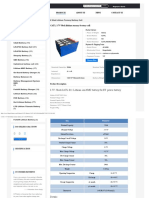
- CATL 37V 50ah Lithium Ternary Battery Cell - LiFePO4 BatteryDokumen4 halamanCATL 37V 50ah Lithium Ternary Battery Cell - LiFePO4 BatterymlutfimaBelum ada peringkat
- Chap. 1 Part 1 Physical PropertiesDokumen15 halamanChap. 1 Part 1 Physical PropertiesAishwarrya NarayananBelum ada peringkat
- Tài Liệu CAT Pallet Truck NPP20NDokumen9 halamanTài Liệu CAT Pallet Truck NPP20NJONHHY NGUYEN DANGBelum ada peringkat
- Investment Model QuestionsDokumen12 halamanInvestment Model Questionssamuel debebe0% (1)
- Harnack and Mean Value Inequalities On Graphs: 1 Introduction and Main ResultsDokumen8 halamanHarnack and Mean Value Inequalities On Graphs: 1 Introduction and Main ResultsNo FaceBelum ada peringkat
- Astar - 23b.trace - XZ Bimodal Next - Line Next - Line Next - Line Next - Line Drrip 1coreDokumen4 halamanAstar - 23b.trace - XZ Bimodal Next - Line Next - Line Next - Line Next - Line Drrip 1corevaibhav sonewaneBelum ada peringkat
- NEW Handbook UG 160818 PDFDokumen118 halamanNEW Handbook UG 160818 PDFHidayah MutalibBelum ada peringkat
- Discovering Vanishing Objects in POSS I Red Images Using The Virtual Observatory - Beatrice - V - Stac1552Dokumen12 halamanDiscovering Vanishing Objects in POSS I Red Images Using The Virtual Observatory - Beatrice - V - Stac1552Bozidar KemicBelum ada peringkat
- TUC5+ Modbus ID Details PDFDokumen10 halamanTUC5+ Modbus ID Details PDFvijikeshBelum ada peringkat
- Design of Inner Lid of Pressure Cooker With Circular Shape Having Straight EdgesDokumen5 halamanDesign of Inner Lid of Pressure Cooker With Circular Shape Having Straight EdgesSecret SecretBelum ada peringkat
- Computer Science Admissions Test: Avengers CollegeDokumen4 halamanComputer Science Admissions Test: Avengers CollegeSaad Bin AzimBelum ada peringkat
- Proact II WoodwardDokumen67 halamanProact II WoodwardGabriel Paco LunaBelum ada peringkat
- Ordinal Logistic Regression: 13.1 BackgroundDokumen15 halamanOrdinal Logistic Regression: 13.1 BackgroundShan BasnayakeBelum ada peringkat
- OSHA Module 3Dokumen17 halamanOSHA Module 3Varsha GBelum ada peringkat
- 671 - BP Well Control Tool Kit 2002Dokumen20 halaman671 - BP Well Control Tool Kit 2002Uok Ritchie100% (1)
- QuesTeksFerriumC61C64andC6 PDFDokumen23 halamanQuesTeksFerriumC61C64andC6 PDFEmily MillerBelum ada peringkat
- Andrew KC Chan (2003) - Observations From Excavations - A ReflectionDokumen19 halamanAndrew KC Chan (2003) - Observations From Excavations - A ReflectionMan Ho LamBelum ada peringkat
- Catamaran AnalysisDokumen83 halamanCatamaran AnalysisbhukthaBelum ada peringkat