Anda mungkin juga menyukai
- Cheat Sheet FinalDokumen2 halamanCheat Sheet FinalFrancis TanBelum ada peringkat
- MH3511 Data Analysis With Computer: Lab 5 (Solution) AY2019/20 Semester 2Dokumen5 halamanMH3511 Data Analysis With Computer: Lab 5 (Solution) AY2019/20 Semester 2Raudhah Abdul AzizBelum ada peringkat
- Multivariate Analysis of Variance (MANOVA) PDFDokumen20 halamanMultivariate Analysis of Variance (MANOVA) PDFscjofyWFawlroa2r06YFVabfbajBelum ada peringkat
- Solutions To ExercisesDokumen61 halamanSolutions To Exercisesvic1234059Belum ada peringkat
- Background For Lesson 5: 1 Cumulative Distribution FunctionDokumen5 halamanBackground For Lesson 5: 1 Cumulative Distribution FunctionNguyễn ĐứcBelum ada peringkat
- Midterm CodesDokumen8 halamanMidterm CodesMaroBelum ada peringkat
- Minimax: 1 The Parks-Mcclellan Filter Design MethodDokumen11 halamanMinimax: 1 The Parks-Mcclellan Filter Design MethodCristóbal Eduardo Carreño MosqueiraBelum ada peringkat
- Machine Learning ProbDokumen15 halamanMachine Learning ProbJenny VarelaBelum ada peringkat
- Formula SheetDokumen7 halamanFormula SheetMohit RakyanBelum ada peringkat
- Bayesian Workshop1 SolutionDokumen3 halamanBayesian Workshop1 SolutionzeliawillscumbergBelum ada peringkat
- Week 12 Exercises SolutionsDokumen4 halamanWeek 12 Exercises SolutionsAbdul MBelum ada peringkat
- : µ = 0 vs H: µ 6= 0. Previous work shows that σ = 2. A change in BMI of 1.5 is considered important to detect (if the true effect size is 1.5 or higherDokumen5 halaman: µ = 0 vs H: µ 6= 0. Previous work shows that σ = 2. A change in BMI of 1.5 is considered important to detect (if the true effect size is 1.5 or higherShreyas SatardekarBelum ada peringkat
- Study Guide - Biostatistics: 35% of Prevmed Exam (With Epi)Dokumen14 halamanStudy Guide - Biostatistics: 35% of Prevmed Exam (With Epi)OEMBoardReviewBelum ada peringkat
- Chebyshev's Rule: Definitions: Sas Puts Out 2-Sided P-Values Rule/definitions ApplicationsDokumen6 halamanChebyshev's Rule: Definitions: Sas Puts Out 2-Sided P-Values Rule/definitions ApplicationspetecadmusBelum ada peringkat
- Hypothesis Testing IDokumen7 halamanHypothesis Testing Irsgtd dhdfjdBelum ada peringkat
- Homework 1: Statistics 109 Due February 17, 2019 at 11:59pm ESTDokumen23 halamanHomework 1: Statistics 109 Due February 17, 2019 at 11:59pm ESTBrianLeBelum ada peringkat
- Reliability Theory and Survival Analysis FinalDokumen12 halamanReliability Theory and Survival Analysis FinalAyushi jainBelum ada peringkat
- Common Probability Distributionsi Math 217/218 Probability and StatisticsDokumen10 halamanCommon Probability Distributionsi Math 217/218 Probability and StatisticsGrace nyangasiBelum ada peringkat
- DeepayanSarkar BayesianDokumen152 halamanDeepayanSarkar BayesianPhat NguyenBelum ada peringkat
- A Bayesian Perspective On Generalization and Stochastic Gradient DescentDokumen4 halamanA Bayesian Perspective On Generalization and Stochastic Gradient DescentRahul MishraBelum ada peringkat
- 5 Describing Populations: in This Chapter We Describe Populations and Samples Using The Language of ProbabilityDokumen9 halaman5 Describing Populations: in This Chapter We Describe Populations and Samples Using The Language of ProbabilityDaniel WuBelum ada peringkat
- Inference in Regression: Brian Caffo, Jeff Leek and Roger Peng Johns Hopkins Bloomberg School of Public HealthDokumen14 halamanInference in Regression: Brian Caffo, Jeff Leek and Roger Peng Johns Hopkins Bloomberg School of Public HealthAlex BoncuBelum ada peringkat
- Sample SizeDokumen34 halamanSample SizeIgor IgoroshkaBelum ada peringkat
- C Inference Statistic With RDokumen11 halamanC Inference Statistic With RLinh NguyễnBelum ada peringkat
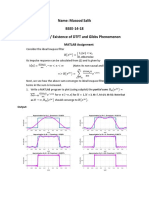
- Name: Masood Salik BSEE-14-18 Convergence / Existence of DTFT and Gibbs PhenomenonDokumen5 halamanName: Masood Salik BSEE-14-18 Convergence / Existence of DTFT and Gibbs PhenomenonAmina TabassumBelum ada peringkat
- 111123-Artikkelin Teksti-237361-1-10-20220527Dokumen13 halaman111123-Artikkelin Teksti-237361-1-10-20220527Rohan BihloveBelum ada peringkat
- Rakhi SinghDokumen7 halamanRakhi SinghRakhi SinghBelum ada peringkat
- Math10282 Ex05 - An R SessionDokumen6 halamanMath10282 Ex05 - An R SessiondeimanteBelum ada peringkat
- Tamas Hardness DaDokumen19 halamanTamas Hardness DaDreBelum ada peringkat
- Constraint Logic Programming SlidesDokumen10 halamanConstraint Logic Programming SlidesFrankBelum ada peringkat
- 2-State EstimationDokumen31 halaman2-State EstimationShahriyar Kabir RistaBelum ada peringkat
- Exercises Lecture 5 Including SolutionsDokumen3 halamanExercises Lecture 5 Including SolutionsAsad ShahbazBelum ada peringkat
- H2 Model ReductionDokumen7 halamanH2 Model ReductionmtichyBelum ada peringkat
- CH 9 SolDokumen6 halamanCH 9 SolFinnigan O'FlahertyBelum ada peringkat
- RegularizationDokumen25 halamanRegularizationPaulBelum ada peringkat
- Shannon 61 79 11 19Dokumen9 halamanShannon 61 79 11 19nazzif10Belum ada peringkat
- JB Test: Test For NormalityDokumen9 halamanJB Test: Test For NormalitytheonlypaulBelum ada peringkat
- Harrell's Concordance Index RDokumen13 halamanHarrell's Concordance Index REMANUELA DI GREGORIOBelum ada peringkat
- Package Gnfit': R Topics DocumentedDokumen6 halamanPackage Gnfit': R Topics DocumentedyaudasBelum ada peringkat
- CET Vol69Dokumen6 halamanCET Vol69minh leBelum ada peringkat
- MultivariableRegression SummaryDokumen15 halamanMultivariableRegression SummaryAlada manaBelum ada peringkat
- Data Analysis and Statistics For Geography Environmental Science and Engineering 1st Acevedo Solution ManualDokumen11 halamanData Analysis and Statistics For Geography Environmental Science and Engineering 1st Acevedo Solution Manualannthompsondmrtjywzsg100% (47)
- Hi Ra PukaDokumen26 halamanHi Ra PukaSpam KingBelum ada peringkat
- Bayesian Workshops20 21Dokumen3 halamanBayesian Workshops20 21zeliawillscumbergBelum ada peringkat
- Ca Array 9 16Dokumen8 halamanCa Array 9 16Manjunath RamachandraBelum ada peringkat
- CMPUT 466/551 - Assignment 1: Paradox?Dokumen6 halamanCMPUT 466/551 - Assignment 1: Paradox?findingfelicityBelum ada peringkat
- 04 BasicAnalysesDokumen44 halaman04 BasicAnalysesCotta LeeBelum ada peringkat
- Introduction To Model Parameter EstimationDokumen37 halamanIntroduction To Model Parameter EstimationKutha ArdanaBelum ada peringkat
- BES - R LabDokumen5 halamanBES - R LabViem AnhBelum ada peringkat
- Adjusting For Covariate Effects On Classification Accuracy Using The Covariate-Adjusted Receiver Operating Characteristic CurveDokumen12 halamanAdjusting For Covariate Effects On Classification Accuracy Using The Covariate-Adjusted Receiver Operating Characteristic CurveChristos GrigoroglouBelum ada peringkat
- Computation of The H - Norm: An Efficient Method: Madhu N. Belur and Cornelis PraagmanDokumen10 halamanComputation of The H - Norm: An Efficient Method: Madhu N. Belur and Cornelis PraagmanarviandyBelum ada peringkat
- A Marginalisation Paradox ExampleDokumen27 halamanA Marginalisation Paradox Exampledpra23Belum ada peringkat
- Comparison of ResultsDokumen6 halamanComparison of Resultsodubade opeyemiBelum ada peringkat
- CS1 R Summary SheetsDokumen26 halamanCS1 R Summary SheetsPranav SharmaBelum ada peringkat
- Introductory Statistics Formulas and TablesDokumen10 halamanIntroductory Statistics Formulas and TablesP KaurBelum ada peringkat
- Mathematical Tripos: Complete Answers Are Preferred To FragmentsDokumen21 halamanMathematical Tripos: Complete Answers Are Preferred To FragmentsKrishna OochitBelum ada peringkat
- SAA For JCCDokumen18 halamanSAA For JCCShu-Bo YangBelum ada peringkat
- R T Test Lab UpdatedDokumen2 halamanR T Test Lab UpdatedceskeimBelum ada peringkat
- A-level Maths Revision: Cheeky Revision ShortcutsDari EverandA-level Maths Revision: Cheeky Revision ShortcutsPenilaian: 3.5 dari 5 bintang3.5/5 (8)
- STAT 462 FinalsolDokumen4 halamanSTAT 462 FinalsolFrancis TanBelum ada peringkat
- Solu 03Dokumen6 halamanSolu 03Francis TanBelum ada peringkat
- MH 3511 Midterm 2018 So LNDokumen5 halamanMH 3511 Midterm 2018 So LNFrancis TanBelum ada peringkat
- MH3511 Midterm 2017 QDokumen4 halamanMH3511 Midterm 2017 QFrancis TanBelum ada peringkat
- Cheat SheetDokumen2 halamanCheat SheetFrancis TanBelum ada peringkat
- Ex 091 SLDokumen2 halamanEx 091 SLSean BonagacciBelum ada peringkat
- MH3511 Midterm 2017 QDokumen4 halamanMH3511 Midterm 2017 QFrancis TanBelum ada peringkat
- 1001 2906Dokumen87 halaman1001 2906Francis TanBelum ada peringkat
- Cheat SheetDokumen1 halamanCheat SheetFrancis TanBelum ada peringkat
- Hypothesis Testing in Machine Learning Using Python - by Yogesh Agrawal - 151413Dokumen15 halamanHypothesis Testing in Machine Learning Using Python - by Yogesh Agrawal - 151413airplaneunderwaterBelum ada peringkat
- Logic For Legal ReasoningDokumen28 halamanLogic For Legal ReasoningOjing De GuzmanBelum ada peringkat
- Chapter IVDokumen37 halamanChapter IVJohn Carlo NacinoBelum ada peringkat
- Study Guide: Enhanced VersionDokumen47 halamanStudy Guide: Enhanced Versiontd00200% (1)
- Indian LogicDokumen174 halamanIndian LogicAnil Kumar100% (1)
- Bird (2018) The Metaphysics of Natural KindsDokumen30 halamanBird (2018) The Metaphysics of Natural KindsChrissy van HulstBelum ada peringkat
- TUTORIAL - Court House - Courtroom - Indian ContextDokumen14 halamanTUTORIAL - Court House - Courtroom - Indian ContextPrathamesh MamidwarBelum ada peringkat
- Reichenbach 1938 The Pragmatic Justification of InductionDokumen3 halamanReichenbach 1938 The Pragmatic Justification of Inductionaayshaahmad743Belum ada peringkat
- Reasoning UncertaintyDokumen39 halamanReasoning UncertaintySoleilBelum ada peringkat
- Critical Thinking and ReasoningDokumen19 halamanCritical Thinking and Reasoningakhilyerawar7013Belum ada peringkat
- Term Paper FormatDokumen12 halamanTerm Paper Formattulsi kawayBelum ada peringkat
- Advanced Topics in Analysis of Economic and Financial Data Using RDokumen148 halamanAdvanced Topics in Analysis of Economic and Financial Data Using RwuxuefeiBelum ada peringkat
- Vladimir Propp (1976-2009), On The Comic and LaughterDokumen192 halamanVladimir Propp (1976-2009), On The Comic and LaughterMaija NahtmaneBelum ada peringkat
- SEC 01 Block 03Dokumen73 halamanSEC 01 Block 03Sayed KutbuddinBelum ada peringkat
- DID PrincetonDokumen38 halamanDID PrincetoningBelum ada peringkat
- CH 14 HandoutDokumen6 halamanCH 14 HandoutJntBelum ada peringkat
- Testing of Hypothesis For in Case of Simple Linear Regression LineDokumen7 halamanTesting of Hypothesis For in Case of Simple Linear Regression LineAsif gillBelum ada peringkat
- Chapter 12 Informing PersuadingDokumen24 halamanChapter 12 Informing PersuadingTaimur ShahidBelum ada peringkat
- Wilcoxon Rank Sum TestDokumen11 halamanWilcoxon Rank Sum TestveniBelum ada peringkat
- Course: Research Methods in Education (8604) Semester: Autumn, 2022Dokumen17 halamanCourse: Research Methods in Education (8604) Semester: Autumn, 2022عابد حسینBelum ada peringkat
- Moore 1994 - Making The Transition To Formal ProofDokumen18 halamanMoore 1994 - Making The Transition To Formal ProofHermantoBelum ada peringkat
- Linear Regression 102: Stability Shelf Life Estimation Using Analysis of CovarianceDokumen22 halamanLinear Regression 102: Stability Shelf Life Estimation Using Analysis of CovariancetvvsagarBelum ada peringkat
- Heteroscedasticity IssueDokumen3 halamanHeteroscedasticity IssueShadman Sakib100% (2)
- Signed Learning Material No. 3 Problem Solving and Reasoning TemplateDokumen11 halamanSigned Learning Material No. 3 Problem Solving and Reasoning TemplateAira Mae Quinones OrendainBelum ada peringkat
- 4th Quarter Exam StatDokumen1 halaman4th Quarter Exam StatNancy OliverioBelum ada peringkat
- Dafiq Julika Iqsyam ExcelDokumen3 halamanDafiq Julika Iqsyam ExcelDafiq Julika Iqsyam IIBelum ada peringkat
- SPSSDokumen9 halamanSPSSIqbaale KurniawanBelum ada peringkat
- Large Sample TestDokumen7 halamanLarge Sample Testrahul khunti100% (1)
- Etica Si Integritate AcademicaDokumen242 halamanEtica Si Integritate AcademicaArhanghelul777Belum ada peringkat
- Key Performance Indicators (Kpis)Dokumen71 halamanKey Performance Indicators (Kpis)Bayu MurtiBelum ada peringkat