Anda mungkin juga menyukai
- Chow TestDokumen23 halamanChow TestHector Garcia0% (1)
- Chow TestDokumen23 halamanChow TestYaronBabaBelum ada peringkat
- DOE Course Part 14Dokumen21 halamanDOE Course Part 14vsuarezf2732Belum ada peringkat
- Design of Engineering Experiments Part 3 - The Blocking Principle The Blocking PrincipleDokumen5 halamanDesign of Engineering Experiments Part 3 - The Blocking Principle The Blocking PrincipleEnio BrogniBelum ada peringkat
- Blocking Principle & Latin Square Designs in Engineering ExperimentsDokumen20 halamanBlocking Principle & Latin Square Designs in Engineering ExperimentsRic GiBelum ada peringkat
- Applications of Microbiolgical Data: Tim Sandle Microbiology Information ResourceDokumen50 halamanApplications of Microbiolgical Data: Tim Sandle Microbiology Information ResourceNatalija Atanasova-PancevskaBelum ada peringkat
- 44 3 Expmntl DesgnDokumen18 halaman44 3 Expmntl Desgntarek moahmoud khalifaBelum ada peringkat
- Functional Form and Dynamic Models: FRT, Lags, Koyck TransformationDokumen27 halamanFunctional Form and Dynamic Models: FRT, Lags, Koyck TransformationmazamniaziBelum ada peringkat
- 2003 StabilityAnalysisDokumen58 halaman2003 StabilityAnalysisSettuBelum ada peringkat
- RatchetingDokumen20 halamanRatchetingAllan Marbaniang100% (1)
- Panel Data Models: Dynamic Panels and Unit RootsDokumen20 halamanPanel Data Models: Dynamic Panels and Unit RootsJeremiahOmwoyoBelum ada peringkat
- Vibration PDFDokumen10 halamanVibration PDFArjun Chitradurga RamachandraRaoBelum ada peringkat
- Chow TestDokumen2 halamanChow TestWhitney LeungBelum ada peringkat
- IMPTDokumen59 halamanIMPTharish srinivasBelum ada peringkat
- FRM Part 1 Changes LO WiseDokumen7 halamanFRM Part 1 Changes LO Wiseanirudh917Belum ada peringkat
- Diagnostic Tests2Dokumen17 halamanDiagnostic Tests2LucBelum ada peringkat
- Concrete Modeling GuideDokumen4 halamanConcrete Modeling GuideJae Huan YooBelum ada peringkat
- Construction: Prefabricated Steel Bridge Systems: Final ReportDokumen14 halamanConstruction: Prefabricated Steel Bridge Systems: Final ReportNicholas FeatherstonBelum ada peringkat
- Joe Carvalho Position PaperDokumen5 halamanJoe Carvalho Position Paperjaguilarn1960Belum ada peringkat
- HFS206 GBA Jul22Dokumen5 halamanHFS206 GBA Jul22Salihin HasanBelum ada peringkat
- Guideline For FE Analyses of Concrete Dams: ICOLD 2017 PragueDokumen17 halamanGuideline For FE Analyses of Concrete Dams: ICOLD 2017 PragueMathy TuringBelum ada peringkat
- Predictive Modeling Questions and AnswersDokumen32 halamanPredictive Modeling Questions and AnswersAsim Mazin100% (1)
- Fatigue Life For ASME VII-DIV2Dokumen23 halamanFatigue Life For ASME VII-DIV2Muhammad Abd El KawyBelum ada peringkat
- 102 PART 1 | INTRO TO OPERATIONS MANAGEMENTDokumen1 halaman102 PART 1 | INTRO TO OPERATIONS MANAGEMENTomer asgharBelum ada peringkat
- PSY417 Week02Dokumen38 halamanPSY417 Week02Ellisha McCBelum ada peringkat
- Bahan Ansys DikaDokumen152 halamanBahan Ansys DikaRandika SudarmaBelum ada peringkat
- PSY - 2060 - 2022H1 - Session 01 2022-01-19 02 - 39 - 01Dokumen24 halamanPSY - 2060 - 2022H1 - Session 01 2022-01-19 02 - 39 - 01Kam ToBelum ada peringkat
- TQM-I 06 Variable Control ChartDokumen73 halamanTQM-I 06 Variable Control ChartAjith NBBelum ada peringkat
- Ce (Pe) 602BDokumen10 halamanCe (Pe) 602BArghya MondalBelum ada peringkat
- Estimation Procedures for Time Series ModelsDokumen51 halamanEstimation Procedures for Time Series ModelsNurudeen Bamidele Faniyi (fbn)Belum ada peringkat
- Classical Linear Regression Model Assumptions and DiagnosticsDokumen71 halamanClassical Linear Regression Model Assumptions and DiagnosticsabdulraufhccBelum ada peringkat
- Rolling Contact Fatigue Life Testing Methods Using Weibull Distribution CalculationsDokumen8 halamanRolling Contact Fatigue Life Testing Methods Using Weibull Distribution CalculationsJojee MarieBelum ada peringkat
- Dynamic Panel Data ModelsDokumen20 halamanDynamic Panel Data Modelszaheer khanBelum ada peringkat
- Classical Linear Regression Model Assumptions and DiagnosticsDokumen66 halamanClassical Linear Regression Model Assumptions and DiagnosticsOguzBelum ada peringkat
- Structural Analysis-II Semester V NotesDokumen151 halamanStructural Analysis-II Semester V NotesKanade's Engineering Classes PuneBelum ada peringkat
- Class 5 Mult Reg Diag 2Dokumen38 halamanClass 5 Mult Reg Diag 2Neway AlemBelum ada peringkat
- Modelling Long-Run Relationship in Finance: Introductory Econometrics For Finance' © Chris Brooks 2013 1Dokumen18 halamanModelling Long-Run Relationship in Finance: Introductory Econometrics For Finance' © Chris Brooks 2013 1Nouf ABelum ada peringkat
- Department of Automobile & Mechanical Engineering: System Design and SimulationDokumen12 halamanDepartment of Automobile & Mechanical Engineering: System Design and Simulationanup chauhanBelum ada peringkat
- Force Methods - Consistent DeformationDokumen41 halamanForce Methods - Consistent DeformationShakira100% (4)
- CE3155 Structural Analysis: ConsultationDokumen3 halamanCE3155 Structural Analysis: Consultationhuiting loyBelum ada peringkat
- Unreplicated 2 Factorial Designs: One Observation Single ReplicateDokumen33 halamanUnreplicated 2 Factorial Designs: One Observation Single ReplicateJosé Carlos Chan AriasBelum ada peringkat
- SE 463 Software Testing and Quality Assurance: Chapter 2: Testing Throughout The SW Life CycleDokumen18 halamanSE 463 Software Testing and Quality Assurance: Chapter 2: Testing Throughout The SW Life CycleSam SamBelum ada peringkat
- Practical Guide To Sequential Design - Webinar SlidesDokumen28 halamanPractical Guide To Sequential Design - Webinar Slidestila12negaBelum ada peringkat
- ARIMA Modelling and Forecasting Techniques ExplainedDokumen30 halamanARIMA Modelling and Forecasting Techniques ExplainedRaymond SmithBelum ada peringkat
- Unit 7 - Forecasting and Time Series - Advanced TopicsDokumen54 halamanUnit 7 - Forecasting and Time Series - Advanced TopicsRajdeep SinghBelum ada peringkat
- Module 07: Solution: Release 2020 R1Dokumen79 halamanModule 07: Solution: Release 2020 R1Rishi SharmaBelum ada peringkat
- Module 3.3Dokumen26 halamanModule 3.3MOHAMMED SHEHZAD K SALIMBelum ada peringkat
- BRM - L4,5 - Linear RegressionDokumen113 halamanBRM - L4,5 - Linear RegressionNusratJahanHeabaBelum ada peringkat
- EXP 3 Coefficient of Friction FinalDokumen5 halamanEXP 3 Coefficient of Friction FinalCef LlameloBelum ada peringkat
- AutocorrelationDokumen25 halamanAutocorrelationAnonymous xeirMaAHBelum ada peringkat
- Time Series AnalysisDokumen36 halamanTime Series AnalysisVinayakaBelum ada peringkat
- Lecture 101Dokumen43 halamanLecture 101Jean ReneBelum ada peringkat
- ANSYS CFX Solving I PDFDokumen128 halamanANSYS CFX Solving I PDFAshish Prasannan KalayilBelum ada peringkat
- Experiment BlockingDokumen17 halamanExperiment Blockingstatistics on tips 2020Belum ada peringkat
- Lecture8 Model Assessment StudentsDokumen37 halamanLecture8 Model Assessment Students翁江靖Belum ada peringkat
- LAS-DLS-421 Module OutlineDokumen8 halamanLAS-DLS-421 Module OutlineElisha ManishimweBelum ada peringkat
- 8 CSC446 546 InputModelingDokumen44 halaman8 CSC446 546 InputModelingCh MaarijBelum ada peringkat
- Ultimate Strength AnalysisDokumen59 halamanUltimate Strength AnalysisPedroBelum ada peringkat
- CH 04Dokumen30 halamanCH 04LusyifaFebioza100% (1)
- The Partial Regularity Theory of Caffarelli, Kohn, and Nirenberg and its SharpnessDari EverandThe Partial Regularity Theory of Caffarelli, Kohn, and Nirenberg and its SharpnessBelum ada peringkat
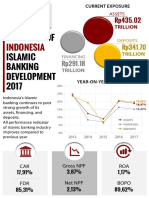
- Indonesia Islamic Banking Snapshot 2017 (V3)Dokumen8 halamanIndonesia Islamic Banking Snapshot 2017 (V3)Haniyah NadhiraBelum ada peringkat
- Thom21e Ch09 FinalDokumen49 halamanThom21e Ch09 Finalagungwibowo89Belum ada peringkat
- ISlide Blue Graduation Thesis Defense Presentation 06Dokumen21 halamanISlide Blue Graduation Thesis Defense Presentation 06Haniyah NadhiraBelum ada peringkat
- Managing People in Global Markets-The Asia Pacific PerspectiveDokumen4 halamanManaging People in Global Markets-The Asia Pacific PerspectiveHaniyah NadhiraBelum ada peringkat
- ISlide Master Thesis Defense PowerPoint Template 07Dokumen21 halamanISlide Master Thesis Defense PowerPoint Template 07Haniyah Nadhira100% (2)
- SPS Des2015Dokumen328 halamanSPS Des2015Haniyah NadhiraBelum ada peringkat
- City Template 16x9Dokumen5 halamanCity Template 16x9Haniyah NadhiraBelum ada peringkat
- Basic Resignation Letter TemplateDokumen1 halamanBasic Resignation Letter TemplateHaniyah NadhiraBelum ada peringkat
- ISlide Blue Graduation Thesis Defense Presentation 06Dokumen21 halamanISlide Blue Graduation Thesis Defense Presentation 06Haniyah NadhiraBelum ada peringkat
- The Bidding War For Harbin Brewery GroupDokumen10 halamanThe Bidding War For Harbin Brewery GroupHaniyah NadhiraBelum ada peringkat
- MBF14e Chap05 FX MarketsDokumen20 halamanMBF14e Chap05 FX MarketsHaniyah Nadhira100% (1)
- Chap 12Dokumen34 halamanChap 12Haniyah NadhiraBelum ada peringkat
- Insights Template Indonesian Bank Improving TractionDokumen29 halamanInsights Template Indonesian Bank Improving TractionHaniyah NadhiraBelum ada peringkat
- MBF14e Chap05 FX MarketsDokumen20 halamanMBF14e Chap05 FX MarketsHaniyah Nadhira100% (1)
- s12 Testing HypothesesDokumen72 halamans12 Testing HypothesesMr. Simple GamerBelum ada peringkat
- Tugas Regresi & Kuisoner Aldi DKKDokumen7 halamanTugas Regresi & Kuisoner Aldi DKKRegan Muammar NugrahaBelum ada peringkat
- Lecture Note 4 - Dynamic Models For Stationary DataDokumen28 halamanLecture Note 4 - Dynamic Models For Stationary DataFaizus Saquib Chowdhury100% (1)
- 0 - Module 2 MIT-OTDokumen95 halaman0 - Module 2 MIT-OTHinata UzumakiBelum ada peringkat
- Stats Chap10Dokumen63 halamanStats Chap10Sameh SalahBelum ada peringkat
- Poisson Estimation and Inference for Occupational Health StudyDokumen38 halamanPoisson Estimation and Inference for Occupational Health Studyjiawei tuBelum ada peringkat
- ANCOVADokumen19 halamanANCOVAhisham00Belum ada peringkat
- MaxabsDokumen7 halamanMaxabskaushal patelBelum ada peringkat
- Solutions: Stat 101 FinalDokumen15 halamanSolutions: Stat 101 Finalkaungwaiphyo89Belum ada peringkat
- Chapter 2 ForecastingDokumen45 halamanChapter 2 ForecastingAmirul HarisBelum ada peringkat
- 0feaf24f-6a96-4279-97a1-86708e467593 (1)Dokumen7 halaman0feaf24f-6a96-4279-97a1-86708e467593 (1)simandharBelum ada peringkat
- Demand Estimation & ForecastingDokumen11 halamanDemand Estimation & Forecastinggarv2114Belum ada peringkat
- Poisson Regression Analysis 136Dokumen8 halamanPoisson Regression Analysis 136George AdongoBelum ada peringkat
- Quantitative Data Analysis: © 2009 John Wiley & Sons LTDDokumen52 halamanQuantitative Data Analysis: © 2009 John Wiley & Sons LTDAhdel GirlisonfireBelum ada peringkat
- Spss 3Dokumen27 halamanSpss 3Eleni BirhanuBelum ada peringkat
- Student Performance (Multiple Linear Regression)Dokumen30 halamanStudent Performance (Multiple Linear Regression)kshitijmalh2004Belum ada peringkat
- Q4 07 - Correlation Regression AnalysisDokumen48 halamanQ4 07 - Correlation Regression AnalysisRon Jasper UrdasBelum ada peringkat
- 1.fitting of Straight LineDokumen1 halaman1.fitting of Straight LineShubhamBelum ada peringkat
- 50.2 - Chi Square Goodness-of-Fit TestDokumen11 halaman50.2 - Chi Square Goodness-of-Fit TestRahul JajuBelum ada peringkat
- Building Multiple Regression ModelsDokumen72 halamanBuilding Multiple Regression ModelsWahaaj RanaBelum ada peringkat
- VARMA For Battery Voltage Forecasting 3Dokumen50 halamanVARMA For Battery Voltage Forecasting 3AngelaCabiaoCaliwagBelum ada peringkat
- ANOVA - Two-Way ANOVA (2B)Dokumen17 halamanANOVA - Two-Way ANOVA (2B)Frederick GellaBelum ada peringkat
- StatDokumen16 halamanStatBagioso, Cyrus Jude G.Belum ada peringkat
- Tabu Ran NormalDokumen14 halamanTabu Ran NormalSylvia100% (1)
- Cox-Stuart 1955 Some Quick Sign Tests For Trend in Location and DispersionDokumen17 halamanCox-Stuart 1955 Some Quick Sign Tests For Trend in Location and DispersiongotickaBelum ada peringkat
- EstimationDokumen9 halamanEstimationSaran KhaliqBelum ada peringkat
- Model Paper STatistics With RDokumen2 halamanModel Paper STatistics With RSreya NagubandiBelum ada peringkat
- Pamantasan ng Lungsod ng Maynila Graduate School ForecastingDokumen11 halamanPamantasan ng Lungsod ng Maynila Graduate School ForecastingAngelie Menia100% (1)
- Lecture Notes in Financial EconometricsDokumen267 halamanLecture Notes in Financial EconometricsAndré CamelBelum ada peringkat
- Sample Chapter PDFDokumen20 halamanSample Chapter PDFbiwithse7enBelum ada peringkat