Anda mungkin juga menyukai
- Architecture From The Outside - Essays On Virtual and Real SpaceDokumen243 halamanArchitecture From The Outside - Essays On Virtual and Real SpaceClaudio Delica100% (2)
- Duchamp: CageDokumen8 halamanDuchamp: CageAlexandra S. ȚăranuBelum ada peringkat
- Architecture From The Outside - Essays On Virtual and Real SpaceDokumen243 halamanArchitecture From The Outside - Essays On Virtual and Real SpaceClaudio Delica100% (2)
- First Seminar Nida Lacan Reading GroupDokumen9 halamanFirst Seminar Nida Lacan Reading GroupAlexandra S. ȚăranuBelum ada peringkat
- Atlas of World ArchitectureDokumen257 halamanAtlas of World Architecturelordshade90Belum ada peringkat
- Pastoralism in IndiaDokumen63 halamanPastoralism in IndiaAlexandra S. ȚăranuBelum ada peringkat
- Pastoralism in IndiaDokumen63 halamanPastoralism in IndiaAlexandra S. ȚăranuBelum ada peringkat
- The Seminar of Jacques Lacan XDokumen313 halamanThe Seminar of Jacques Lacan XhmmmicBelum ada peringkat
- Pastoralism in IndiaDokumen63 halamanPastoralism in IndiaAlexandra S. ȚăranuBelum ada peringkat
- Libro de Diseño Grafico y Creación de Logos y LogotiposDokumen191 halamanLibro de Diseño Grafico y Creación de Logos y Logotiposco-k100% (12)
- Australian GeographerDokumen18 halamanAustralian GeographerAlexandra S. ȚăranuBelum ada peringkat
- Is Citizen Participation in Government Decision Making Worth the EffortDokumen11 halamanIs Citizen Participation in Government Decision Making Worth the EffortAlexandra S. ȚăranuBelum ada peringkat
- Design GuidelinesDokumen273 halamanDesign GuidelinesAlexandra S. Țăranu100% (1)
- The Desire Called Architecture - HaysDokumen5 halamanThe Desire Called Architecture - HaysAlexandra S. ȚăranuBelum ada peringkat
- Building the Evidence on Urban Green SpacesDokumen56 halamanBuilding the Evidence on Urban Green SpacesAlexandra S. ȚăranuBelum ada peringkat
- Urban Micro ClimateDokumen3 halamanUrban Micro ClimateAlexandra S. ȚăranuBelum ada peringkat
- Shoe Dog: A Memoir by the Creator of NikeDari EverandShoe Dog: A Memoir by the Creator of NikePenilaian: 4.5 dari 5 bintang4.5/5 (537)
- Never Split the Difference: Negotiating As If Your Life Depended On ItDari EverandNever Split the Difference: Negotiating As If Your Life Depended On ItPenilaian: 4.5 dari 5 bintang4.5/5 (838)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureDari EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FuturePenilaian: 4.5 dari 5 bintang4.5/5 (474)
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeDari EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifePenilaian: 4 dari 5 bintang4/5 (5783)
- Grit: The Power of Passion and PerseveranceDari EverandGrit: The Power of Passion and PerseverancePenilaian: 4 dari 5 bintang4/5 (587)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceDari EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RacePenilaian: 4 dari 5 bintang4/5 (890)
- The Yellow House: A Memoir (2019 National Book Award Winner)Dari EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Penilaian: 4 dari 5 bintang4/5 (98)
- On Fire: The (Burning) Case for a Green New DealDari EverandOn Fire: The (Burning) Case for a Green New DealPenilaian: 4 dari 5 bintang4/5 (72)
- The Little Book of Hygge: Danish Secrets to Happy LivingDari EverandThe Little Book of Hygge: Danish Secrets to Happy LivingPenilaian: 3.5 dari 5 bintang3.5/5 (399)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryDari EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryPenilaian: 3.5 dari 5 bintang3.5/5 (231)
- Team of Rivals: The Political Genius of Abraham LincolnDari EverandTeam of Rivals: The Political Genius of Abraham LincolnPenilaian: 4.5 dari 5 bintang4.5/5 (234)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaDari EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaPenilaian: 4.5 dari 5 bintang4.5/5 (265)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersDari EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersPenilaian: 4.5 dari 5 bintang4.5/5 (344)
- The Emperor of All Maladies: A Biography of CancerDari EverandThe Emperor of All Maladies: A Biography of CancerPenilaian: 4.5 dari 5 bintang4.5/5 (271)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyDari EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyPenilaian: 3.5 dari 5 bintang3.5/5 (2219)
- The Unwinding: An Inner History of the New AmericaDari EverandThe Unwinding: An Inner History of the New AmericaPenilaian: 4 dari 5 bintang4/5 (45)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreDari EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You ArePenilaian: 4 dari 5 bintang4/5 (1090)
- Rise of ISIS: A Threat We Can't IgnoreDari EverandRise of ISIS: A Threat We Can't IgnorePenilaian: 3.5 dari 5 bintang3.5/5 (137)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)Dari EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Penilaian: 4.5 dari 5 bintang4.5/5 (119)
- Her Body and Other Parties: StoriesDari EverandHer Body and Other Parties: StoriesPenilaian: 4 dari 5 bintang4/5 (821)
- D. Marriot - The Development of High-Performance Post-Tensioned Rocking Systems For The Seismic Design of StructuresDokumen556 halamanD. Marriot - The Development of High-Performance Post-Tensioned Rocking Systems For The Seismic Design of Structuresedicson1aBelum ada peringkat
- eFI Fuel Systems: Draft OnlyDokumen18 halamaneFI Fuel Systems: Draft OnlyAmal TharakaBelum ada peringkat
- Fuji FCR 5000 Service ManualDokumen892 halamanFuji FCR 5000 Service Manualmasroork_270% (10)
- B752 eDokumen24 halamanB752 eRoberto Villegas83% (6)
- Dokumen - Pub The City Amp Guilds Textbookbook 2 Electrical Installations For The Level 3 Apprenticeship 5357 Level 3 Advanced Technical Diploma 8202 Amp Level 3 Diploma 2365 1510432256 9781510432253Dokumen610 halamanDokumen - Pub The City Amp Guilds Textbookbook 2 Electrical Installations For The Level 3 Apprenticeship 5357 Level 3 Advanced Technical Diploma 8202 Amp Level 3 Diploma 2365 1510432256 9781510432253Abdulrahim Abdulhasiz100% (1)
- Perfect Gas Law Lab ReportDokumen9 halamanPerfect Gas Law Lab ReportTan Zu Kuan50% (2)
- Elasticity PDFDokumen8 halamanElasticity PDFrachna chhabraBelum ada peringkat
- Low Pass Filter ActiveDokumen8 halamanLow Pass Filter ActiveTioRamadhanBelum ada peringkat
- Performa EngineDokumen26 halamanPerforma EngineAndri SetiyawanBelum ada peringkat
- Purchasing and Supply ManagementDokumen78 halamanPurchasing and Supply Managementbilm100% (2)
- The Future of De-Icing: Safeaero 220Dokumen8 halamanThe Future of De-Icing: Safeaero 220焦中华Belum ada peringkat
- CATIA V5R17 Chain & Sprocket Simulation ExplainedDokumen35 halamanCATIA V5R17 Chain & Sprocket Simulation ExplainedBill Harbin50% (2)
- DS0000087 - Programmer's Manual - of X-LIB Software LibraryDokumen175 halamanDS0000087 - Programmer's Manual - of X-LIB Software LibraryAmir Nazem zadeh100% (1)
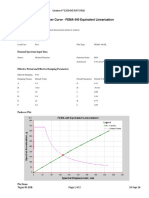
- FEMA 440 equivalent linearization pushover analysisDokumen2 halamanFEMA 440 equivalent linearization pushover analysisAdam JrBelum ada peringkat
- Communications201509 DLDokumen132 halamanCommunications201509 DLleecomBelum ada peringkat
- Pump KnowledgeDokumen17 halamanPump Knowledgesmupy_122Belum ada peringkat
- Case StudyDokumen4 halamanCase StudyAamirBelum ada peringkat
- Homework 5Dokumen3 halamanHomework 5Engr Ghulam MustafaBelum ada peringkat
- Series Circuit Ohm's LawDokumen18 halamanSeries Circuit Ohm's Lawapi-3842326Belum ada peringkat
- Keywords.: To Study About SnortDokumen12 halamanKeywords.: To Study About SnortReshma Hemant PatelBelum ada peringkat
- SMK BUKIT SENTOSA TINGKATAN 4 PEPERIKSAAN AKHIR TAHUN 2014 MARKING SCHEMEDokumen7 halamanSMK BUKIT SENTOSA TINGKATAN 4 PEPERIKSAAN AKHIR TAHUN 2014 MARKING SCHEMEMohd Hairul Akmal Ab. AzizBelum ada peringkat
- 2012-Tcot-008-S.o.w-001 Rev.2Dokumen150 halaman2012-Tcot-008-S.o.w-001 Rev.2denyBelum ada peringkat
- Mixers Towable Concrete Essick EC42S Rev 8 Manual DataId 18822 Version 1Dokumen84 halamanMixers Towable Concrete Essick EC42S Rev 8 Manual DataId 18822 Version 1Masayu MYusoffBelum ada peringkat
- Chapter 1 Balancing of Rotating Masses: Sr. No. QuestionsDokumen20 halamanChapter 1 Balancing of Rotating Masses: Sr. No. QuestionsKashyap ChauhanBelum ada peringkat
- Catálogo Anderson Greenwood 400sDokumen32 halamanCatálogo Anderson Greenwood 400sDaniela BeltranBelum ada peringkat
- Bhartia Infra Projects LTD.: Guwahati, Assam Test ReportDokumen13 halamanBhartia Infra Projects LTD.: Guwahati, Assam Test Reportsuresh kumarBelum ada peringkat
- MeasurementDokumen4 halamanMeasurementmuh_akbar2451Belum ada peringkat
- List Inventaris PPPDokumen7 halamanList Inventaris PPPasep nathanBelum ada peringkat
- Tablas Weldolets, ThredoletsDokumen44 halamanTablas Weldolets, ThredoletsIng TelloBelum ada peringkat
- Vernacular HungarianDokumen51 halamanVernacular HungariandeltagBelum ada peringkat