Anda mungkin juga menyukai
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceDari EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RacePenilaian: 4 dari 5 bintang4/5 (895)
- Never Split the Difference: Negotiating As If Your Life Depended On ItDari EverandNever Split the Difference: Negotiating As If Your Life Depended On ItPenilaian: 4.5 dari 5 bintang4.5/5 (838)
- The Yellow House: A Memoir (2019 National Book Award Winner)Dari EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Penilaian: 4 dari 5 bintang4/5 (98)
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeDari EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifePenilaian: 4 dari 5 bintang4/5 (5794)
- Shoe Dog: A Memoir by the Creator of NikeDari EverandShoe Dog: A Memoir by the Creator of NikePenilaian: 4.5 dari 5 bintang4.5/5 (537)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaDari EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaPenilaian: 4.5 dari 5 bintang4.5/5 (266)
- The Little Book of Hygge: Danish Secrets to Happy LivingDari EverandThe Little Book of Hygge: Danish Secrets to Happy LivingPenilaian: 3.5 dari 5 bintang3.5/5 (400)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureDari EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FuturePenilaian: 4.5 dari 5 bintang4.5/5 (474)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryDari EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryPenilaian: 3.5 dari 5 bintang3.5/5 (231)
- Grit: The Power of Passion and PerseveranceDari EverandGrit: The Power of Passion and PerseverancePenilaian: 4 dari 5 bintang4/5 (588)
- The Emperor of All Maladies: A Biography of CancerDari EverandThe Emperor of All Maladies: A Biography of CancerPenilaian: 4.5 dari 5 bintang4.5/5 (271)
- The Unwinding: An Inner History of the New AmericaDari EverandThe Unwinding: An Inner History of the New AmericaPenilaian: 4 dari 5 bintang4/5 (45)
- On Fire: The (Burning) Case for a Green New DealDari EverandOn Fire: The (Burning) Case for a Green New DealPenilaian: 4 dari 5 bintang4/5 (74)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersDari EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersPenilaian: 4.5 dari 5 bintang4.5/5 (345)
- Team of Rivals: The Political Genius of Abraham LincolnDari EverandTeam of Rivals: The Political Genius of Abraham LincolnPenilaian: 4.5 dari 5 bintang4.5/5 (234)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreDari EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You ArePenilaian: 4 dari 5 bintang4/5 (1090)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyDari EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyPenilaian: 3.5 dari 5 bintang3.5/5 (2259)
- Rise of ISIS: A Threat We Can't IgnoreDari EverandRise of ISIS: A Threat We Can't IgnorePenilaian: 3.5 dari 5 bintang3.5/5 (137)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)Dari EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Penilaian: 4.5 dari 5 bintang4.5/5 (121)
- Her Body and Other Parties: StoriesDari EverandHer Body and Other Parties: StoriesPenilaian: 4 dari 5 bintang4/5 (821)
- The Dream Mill (Companies House) DirectorsDokumen2 halamanThe Dream Mill (Companies House) DirectorsCazzac111Belum ada peringkat
- Microsoft Word - Method of Statement For Voltage Dip SimulationDokumen3 halamanMicrosoft Word - Method of Statement For Voltage Dip SimulationNatthawat WatcharaprakaiBelum ada peringkat
- Python Programming Dated 16-07-2021Dokumen6 halamanPython Programming Dated 16-07-2021Raghav AgarwalBelum ada peringkat
- Sce 041 101 Wincc Basic ktp700 s7 1200 r1709 enDokumen133 halamanSce 041 101 Wincc Basic ktp700 s7 1200 r1709 enMd. Mahbubur RahmanBelum ada peringkat
- Slide PowerPoint Dep So 25 - PhamlocblogDokumen28 halamanSlide PowerPoint Dep So 25 - PhamlocblogNg Thanh TungBelum ada peringkat
- Systems Analysis and Design: Alan Dennis, Barbara Haley Wixom, and Roberta Roth John Wiley & Sons, IncDokumen42 halamanSystems Analysis and Design: Alan Dennis, Barbara Haley Wixom, and Roberta Roth John Wiley & Sons, IncCCIE CCIEBelum ada peringkat
- FAQ - Rockwell Automation and Microsoft Product CompatibilityDokumen4 halamanFAQ - Rockwell Automation and Microsoft Product CompatibilityjaysonlkhBelum ada peringkat
- BUMC MEDLINE Plus/OVID Fact Sheet: Alumni Medical Library Boston University Medical CenterDokumen2 halamanBUMC MEDLINE Plus/OVID Fact Sheet: Alumni Medical Library Boston University Medical CenterRay PermanaBelum ada peringkat
- Brochure Gen SetDokumen15 halamanBrochure Gen SetfitrahjahimBelum ada peringkat
- Oracle Parameters and Their DescriptionsDokumen9 halamanOracle Parameters and Their DescriptionsPILLINAGARAJUBelum ada peringkat
- Pa 8000Dokumen138 halamanPa 8000MilabBelum ada peringkat
- NMON Analyser User Guide v34Dokumen29 halamanNMON Analyser User Guide v34Siva KumarBelum ada peringkat
- S7-1200 DataLogging DOC v2d0d1 enDokumen53 halamanS7-1200 DataLogging DOC v2d0d1 enJuan Martin Gutierrez OchoaBelum ada peringkat
- Tensor Flow 101Dokumen58 halamanTensor Flow 101Narasimhaiah Narahari100% (7)
- Transition Delay Fault Brad Hill ELEC 7250 April 13, 2006Dokumen6 halamanTransition Delay Fault Brad Hill ELEC 7250 April 13, 2006pravallika vysyarajuBelum ada peringkat
- Ahmed Mohammed Senior Oracle DBA Phone: 972-338-9099Dokumen7 halamanAhmed Mohammed Senior Oracle DBA Phone: 972-338-9099Madhav GarikapatiBelum ada peringkat
- Sample FIleDokumen20 halamanSample FIleHARSH PLAYZBelum ada peringkat
- Excel Final ExamDokumen2 halamanExcel Final ExamTenywa MichealBelum ada peringkat
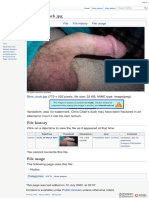
- FileBent Duck - JPG - CWCkiDokumen1 halamanFileBent Duck - JPG - CWCkiKay SchmiererBelum ada peringkat
- Lecture 3Dokumen7 halamanLecture 3xssdBelum ada peringkat
- Amake Amar Moto Thakte DaoDokumen15 halamanAmake Amar Moto Thakte DaoFarhanChowdhuryMehdiBelum ada peringkat
- Hit 7300 TSMNDokumen159 halamanHit 7300 TSMNMohammed Kumayl100% (1)
- Keystroke Logging KeyloggingDokumen14 halamanKeystroke Logging KeyloggingAnjali100% (1)
- How To Install Solr StandaloneDokumen7 halamanHow To Install Solr Standaloneheddoun00Belum ada peringkat
- HLD-FQZ-3Z Alternator and Starter Test Bench (Windows Computer)Dokumen2 halamanHLD-FQZ-3Z Alternator and Starter Test Bench (Windows Computer)Rocky Escudero GonzalesBelum ada peringkat
- Comupterization of A Mathematical Formula Solver SystemDokumen42 halamanComupterization of A Mathematical Formula Solver SystemAbduljelil ZubairuBelum ada peringkat
- Sample SQA QA Software Quality Assurance ResumeDokumen3 halamanSample SQA QA Software Quality Assurance ResumeArif Masood100% (1)
- How To NPM Unistall Unused Packages in Node - Js - by VithalReddy - stackFAME - MediumDokumen2 halamanHow To NPM Unistall Unused Packages in Node - Js - by VithalReddy - stackFAME - MediumcartenaBelum ada peringkat
- Sakila Sample Database: 1 Preface and Legal NoticesDokumen26 halamanSakila Sample Database: 1 Preface and Legal NoticesTermux HubBelum ada peringkat