Anda mungkin juga menyukai
- Réseaux mobiles et satellitaires: Principes, calculs et simulationsDari EverandRéseaux mobiles et satellitaires: Principes, calculs et simulationsBelum ada peringkat
- Chapitre3-Canaux DiscretsDokumen12 halamanChapitre3-Canaux DiscretsHamid BouassamBelum ada peringkat
- Cours 1 Circuits Et Dispositifs Passifs Pour Microonde .HTMDokumen6 halamanCours 1 Circuits Et Dispositifs Passifs Pour Microonde .HTMMegherbi RahalBelum ada peringkat
- TD RsaDokumen4 halamanTD RsaNdik LipemBelum ada peringkat
- CC Se PDFDokumen11 halamanCC Se PDFDelphin KaoBelum ada peringkat
- Corrigé Examen Communications Numériques - 2017Dokumen12 halamanCorrigé Examen Communications Numériques - 2017alaBelum ada peringkat
- Codage CanalDokumen2 halamanCodage CanalAsma Bouhlel YounesBelum ada peringkat
- 094 Bases de Communications Numeriques 2 TDMDokumen5 halaman094 Bases de Communications Numeriques 2 TDMAhm DHBelum ada peringkat
- OPTIMISATION DU TEMPS DE COURSE DANS UN SUPERMARCHE Avec Une Solution de SELF SCANNINGDokumen124 halamanOPTIMISATION DU TEMPS DE COURSE DANS UN SUPERMARCHE Avec Une Solution de SELF SCANNINGJules NdangaBelum ada peringkat
- Devoir À RendreDokumen1 halamanDevoir À RendreSafae100% (1)
- Codage Canal V2 PDFDokumen68 halamanCodage Canal V2 PDFOussama DariàouiBelum ada peringkat
- Cours L3 Télécom-Communication NumériqueDokumen14 halamanCours L3 Télécom-Communication NumériquePaypal RezultBelum ada peringkat
- TP N°02 Codage Shanon-FanoDokumen2 halamanTP N°02 Codage Shanon-FanoMohamed MohamedBelum ada peringkat
- Antenne Et Propagation RadioDokumen48 halamanAntenne Et Propagation Radiocolin37100% (2)
- Sujet 2 Theorie de L'information Et Codage NumeriqueDokumen1 halamanSujet 2 Theorie de L'information Et Codage NumeriqueDuvet francoisBelum ada peringkat
- Série de TD 1Dokumen3 halamanSérie de TD 1Děmøïšěllë RãnBelum ada peringkat
- Description D'une LiaisonDokumen42 halamanDescription D'une LiaisonMike Garvens Bien—aiméBelum ada peringkat
- Theorie InformationDokumen88 halamanTheorie Informationayman lamzouriBelum ada peringkat
- Fstmdeust Mipe141ceechapvilesdiodes 151122002110 Lva1 App6891 PDFDokumen71 halamanFstmdeust Mipe141ceechapvilesdiodes 151122002110 Lva1 App6891 PDFمصطفاوي محمدBelum ada peringkat
- Ies Nyquist PDFDokumen3 halamanIes Nyquist PDFboubacarfarkatoureBelum ada peringkat
- Travail Pour L'oral FinalDokumen2 halamanTravail Pour L'oral FinalAbdellah MaBelum ada peringkat
- TD Communication Analogique 18Dokumen2 halamanTD Communication Analogique 18superzakiBelum ada peringkat
- Cours TI 2018Dokumen124 halamanCours TI 2018kana sergeBelum ada peringkat
- Codage Et Information-Prof (Version Finale)Dokumen143 halamanCodage Et Information-Prof (Version Finale)scar lightBelum ada peringkat
- PR5 DPSKDokumen25 halamanPR5 DPSKKhachane ImaneBelum ada peringkat
- TD1-reseauxDokumen5 halamanTD1-reseauxelmamoun1Belum ada peringkat
- OFDM Louet Supelec RennesDokumen26 halamanOFDM Louet Supelec RennesyanrosBelum ada peringkat
- EXAMEN Antennes LMD 2010 PDFDokumen2 halamanEXAMEN Antennes LMD 2010 PDFhousssem benhaniBelum ada peringkat
- Rapport GHAZI 2Dokumen9 halamanRapport GHAZI 2Imad SimoBelum ada peringkat
- Technique de transmission-chapII-Modulation D'amplitude AMDokumen18 halamanTechnique de transmission-chapII-Modulation D'amplitude AMSouAi AzIzBelum ada peringkat
- Notion de Base Des RéseauxDokumen72 halamanNotion de Base Des RéseauxJawadi HamdiBelum ada peringkat
- Chapitre 3-2019-2020 PDFDokumen12 halamanChapitre 3-2019-2020 PDFbellaBelum ada peringkat
- Cour 3Dokumen35 halamanCour 3manaaadelBelum ada peringkat
- Intro Codage Source Et Codage de Canal PDFDokumen145 halamanIntro Codage Source Et Codage de Canal PDFAli KHALFA100% (1)
- TD - Transm en BBDokumen2 halamanTD - Transm en BBKINGOBelum ada peringkat
- Simulation Sur MATLAB D'un Système de Communication À Spectre Étalé Par Séquence Directe Ds-CdmaDokumen66 halamanSimulation Sur MATLAB D'un Système de Communication À Spectre Étalé Par Séquence Directe Ds-CdmaTELECOM STUDENTBelum ada peringkat
- Exercices Corriges MatricesDokumen3 halamanExercices Corriges Matriceslionelmessi10Belum ada peringkat
- CNAM Signal TD 1Dokumen18 halamanCNAM Signal TD 1kaoutarBelum ada peringkat
- Ampli ACCORDEDokumen10 halamanAmpli ACCORDEMaria MEKLI100% (1)
- TD MasterDokumen13 halamanTD MasterabdellahmorBelum ada peringkat
- Les Antennes L2sans Exercices Résolus PDFDokumen29 halamanLes Antennes L2sans Exercices Résolus PDFilyes ben nachwenBelum ada peringkat
- Chapitre 1Dokumen12 halamanChapitre 1Houda SenoussiBelum ada peringkat
- Presentation TDMADokumen6 halamanPresentation TDMAKhaoula SamaaliBelum ada peringkat
- TP En206 2011 2012 PDFDokumen17 halamanTP En206 2011 2012 PDFAdil AbouelhassanBelum ada peringkat
- H15 MAT2717 FinalDokumen2 halamanH15 MAT2717 Finalkalahassa123Belum ada peringkat
- Notes de Cours Techniques Multiplexage PDFDokumen11 halamanNotes de Cours Techniques Multiplexage PDFSamar ArfaouiBelum ada peringkat
- Serie TD 2Dokumen2 halamanSerie TD 2maîgaBelum ada peringkat
- Spe Sujet Radio ModulationDokumen4 halamanSpe Sujet Radio ModulationrihabBelum ada peringkat
- TP OFDM & CDMA PDFDokumen14 halamanTP OFDM & CDMA PDFAbderrahmane BoussekoumBelum ada peringkat
- TP 03 Contrainte de Trafic, Grade of Service (GOS), La Loi D'erlang BDokumen14 halamanTP 03 Contrainte de Trafic, Grade of Service (GOS), La Loi D'erlang BBOUZANA Elamine100% (1)
- Chapitre1 Le RTCPDokumen16 halamanChapitre1 Le RTCPJawad HmoumaneBelum ada peringkat
- TPTelecom EOAADokumen22 halamanTPTelecom EOAAAli KHALFABelum ada peringkat
- Epu Elec5 TR TP Telecom 1 AntennesDokumen14 halamanEpu Elec5 TR TP Telecom 1 Antennesxenaman1767% (3)
- PrgsystelecommDokumen19 halamanPrgsystelecommberber houcineBelum ada peringkat
- Ofdm PDFDokumen17 halamanOfdm PDFaimadjeBelum ada peringkat
- TPTelecomEOAA PDFDokumen22 halamanTPTelecomEOAA PDFSaad ChakkorBelum ada peringkat
- Canaux Non Idéaux Partie 2Dokumen21 halamanCanaux Non Idéaux Partie 2Lÿdîã Kâbylë100% (1)
- Cours TI Chap3Dokumen21 halamanCours TI Chap3Belhedi ChaimaBelum ada peringkat
- Slide ELE112 2013-2014Dokumen235 halamanSlide ELE112 2013-2014Abdelkader HEMAZBelum ada peringkat
- JAVADokumen85 halamanJAVAaymBelum ada peringkat
- Chapitre 1 - Introduction À L'analyse NumériqueDokumen4 halamanChapitre 1 - Introduction À L'analyse NumériqueAnou ArBelum ada peringkat
- Structures 3D - Exemple CYPEDokumen38 halamanStructures 3D - Exemple CYPEtrafficzitBelum ada peringkat
- Méthode HornerDokumen4 halamanMéthode HornerBen Ali FathiBelum ada peringkat
- Automate TSX 37 PDFDokumen10 halamanAutomate TSX 37 PDFLASSAADBelum ada peringkat
- Examen 2022Dokumen9 halamanExamen 2022bouchrihamoundirdzBelum ada peringkat
- Camtasia StudioDokumen2 halamanCamtasia StudioAnonymous Os3wA48dBelum ada peringkat
- INTELLIGENCE ECONOMIQUE ET STRATEGIQUE: LE CAS DES ETATS-UNIS - Thomas Bonnecarrere - Nelly Dubois - Florentin Rollet - OIivier SoulaDokumen38 halamanINTELLIGENCE ECONOMIQUE ET STRATEGIQUE: LE CAS DES ETATS-UNIS - Thomas Bonnecarrere - Nelly Dubois - Florentin Rollet - OIivier SoulaThomas BONNECARRERE100% (1)
- CCNP Route FormationDokumen2 halamanCCNP Route FormationTrong Oganort GampoulaBelum ada peringkat
- 3 - Simulation Des Systemes À Événement DiscretDokumen20 halaman3 - Simulation Des Systemes À Événement DiscretLeila KarimBelum ada peringkat
- La Place de L'internet Dans La Communication Au MarocDokumen21 halamanLa Place de L'internet Dans La Communication Au MarocEMaroketingBelum ada peringkat
- HILTI T3 VBU Supports Portes BatteriesDokumen5 halamanHILTI T3 VBU Supports Portes BatteriesLê Ngọc-HàBelum ada peringkat
- Marche Du e Commerce en Algerie 844016Dokumen26 halamanMarche Du e Commerce en Algerie 844016Mouna SamarraBelum ada peringkat
- ProblemeDokumen2 halamanProblemeyosrhammemiiiBelum ada peringkat
- Les Macros Complémentaires Avec ExcelDokumen33 halamanLes Macros Complémentaires Avec ExcelPeter KaboreBelum ada peringkat
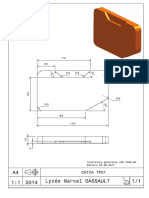
- Catia v5Dokumen25 halamanCatia v5Mohammed DahbiBelum ada peringkat
- Yanis FreeDokumen5 halamanYanis FreeYanis KirecheBelum ada peringkat
- Comment Utiliser Nmap PDFDokumen2 halamanComment Utiliser Nmap PDFNicoleBelum ada peringkat
- Procédure de Récupération CegidDokumen6 halamanProcédure de Récupération CegidtomecruzzBelum ada peringkat
- Statique 2009 Corrige StagiaireDokumen82 halamanStatique 2009 Corrige StagiaireOnguetou JulesBelum ada peringkat
- Mehdi DiapoDokumen14 halamanMehdi Diapoapi-308518022Belum ada peringkat
- Avast CléDokumen2 halamanAvast Clébroisy018283Belum ada peringkat
- CC Avec Correction Module POO Univ Tlemcen Promo 2018-2019 (Tchi Drive)Dokumen6 halamanCC Avec Correction Module POO Univ Tlemcen Promo 2018-2019 (Tchi Drive)Riadh MatmatBelum ada peringkat
- SDGDokumen4 halamanSDGZwe LinBelum ada peringkat
- Mémo Fiche Hyper-V - Fiche 4 - Utiliser Une Clé USB Sous Hyper (V PDFDokumen5 halamanMémo Fiche Hyper-V - Fiche 4 - Utiliser Une Clé USB Sous Hyper (V PDFDaba Cheikh WadeBelum ada peringkat
- Examen TPDokumen5 halamanExamen TPnoussa79Belum ada peringkat
- Ens Ens Ens STD Opt Dig Gie 002 A3Dokumen262 halamanEns Ens Ens STD Opt Dig Gie 002 A3JonathanBelum ada peringkat
- Amelioration Continue SMQSE Cofiroute ST02 MERESSEAurore 04062012 V0 PDFDokumen41 halamanAmelioration Continue SMQSE Cofiroute ST02 MERESSEAurore 04062012 V0 PDFAdam Hadj CharifBelum ada peringkat
- Gestion Equipes MulticulturellesDokumen7 halamanGestion Equipes MulticulturellesRoxana YantoBelum ada peringkat
- TP FinalDokumen2 halamanTP FinalŚoÛſfiIàŋBelum ada peringkat