Anda mungkin juga menyukai
- Accrual EngineDokumen48 halamanAccrual Enginerajesh1978.nair2381100% (2)
- 035 Assignment PDFDokumen14 halaman035 Assignment PDFTman LetswaloBelum ada peringkat
- Project 2 C++Dokumen34 halamanProject 2 C++sana fiazBelum ada peringkat
- IBScanUltimate API Manual For Java (And Android)Dokumen53 halamanIBScanUltimate API Manual For Java (And Android)Alex Pinilla100% (1)
- 024 Price and Everything PDFDokumen12 halaman024 Price and Everything PDFTman LetswaloBelum ada peringkat
- IELTS Reading - Matching Headings PDFDokumen47 halamanIELTS Reading - Matching Headings PDFMamataMaharanaBelum ada peringkat
- Reading Skills For IELTS - Paraphrasing PDFDokumen16 halamanReading Skills For IELTS - Paraphrasing PDFMamataMaharanaBelum ada peringkat
- High Performance Techniques For Microsoft SQL ServerDokumen307 halamanHigh Performance Techniques For Microsoft SQL ServerLuigui GarcíaBelum ada peringkat
- DB0201EN-Week3-1-2-Querying-v4-py: 1.1 Task 1: Import The Ibm - DB Python LibraryDokumen5 halamanDB0201EN-Week3-1-2-Querying-v4-py: 1.1 Task 1: Import The Ibm - DB Python LibraryAlex OrtegaBelum ada peringkat
- PandasDokumen16 halamanPandaslalkrishna123Belum ada peringkat
- IP Practic MINEDokumen30 halamanIP Practic MINESouryo Das GuptaBelum ada peringkat
- Wa0012.Dokumen30 halamanWa0012.hewepo4344Belum ada peringkat
- Practical Record 2 PYTHON AND SQL PROGRAMS - 2023Dokumen76 halamanPractical Record 2 PYTHON AND SQL PROGRAMS - 2023isnprincipal2020Belum ada peringkat
- Introduction To PandasDokumen26 halamanIntroduction To PandasOkewunmi PaulBelum ada peringkat
- Laboratorio Creacion de Bases de Datos, Tablas y Diagramas en SqlserverDokumen7 halamanLaboratorio Creacion de Bases de Datos, Tablas y Diagramas en SqlserverrafaelBelum ada peringkat
- R DocsDokumen45 halamanR Docspbtd pbtBelum ada peringkat
- Intro To Py and ML - Part 2Dokumen10 halamanIntro To Py and ML - Part 2KAORU AmaneBelum ada peringkat
- Ip Worksheet 3 - Q'SDokumen6 halamanIp Worksheet 3 - Q'SShabin MuhammedBelum ada peringkat
- Rudi Bruchez: What I Have Seen So Far in My Performance Tuning AuditsDokumen56 halamanRudi Bruchez: What I Have Seen So Far in My Performance Tuning AuditsB4H TVBelum ada peringkat
- Laboratory Work #6. R - CSV Files: Getting and Setting The Working DirectoryDokumen21 halamanLaboratory Work #6. R - CSV Files: Getting and Setting The Working DirectoryNaski KuafniBelum ada peringkat
- Python PracticalsDokumen26 halamanPython Practicalsvenkat krishnanBelum ada peringkat
- Reading From SQL DatabasesDokumen13 halamanReading From SQL Databasesmauricio Lagos rogersBelum ada peringkat
- Learning Apache Spark With PythonDokumen10 halamanLearning Apache Spark With PythondalalroshanBelum ada peringkat
- Customer - Segmentation - Jupyter NotebookDokumen3 halamanCustomer - Segmentation - Jupyter Notebookakash.050501Belum ada peringkat
- Manipulating Dataframes With Pandas: Categoricals and GroupbyDokumen41 halamanManipulating Dataframes With Pandas: Categoricals and GroupbyCristian DiazBelum ada peringkat
- SQL DB Migration Checklist (Praveen) MB: 91-8197293434 PDFDokumen5 halamanSQL DB Migration Checklist (Praveen) MB: 91-8197293434 PDFMohan BrahmamBelum ada peringkat
- Python PandasDokumen1 halamanPython PandasHenish N JainBelum ada peringkat
- Problem 1: Clustering: #Load The Required PackagesDokumen43 halamanProblem 1: Clustering: #Load The Required PackagesravikgovinduBelum ada peringkat
- JSON A Panda PythonDokumen3 halamanJSON A Panda PythonParra VictorBelum ada peringkat
- Subset Selection Class AssignmentDokumen5 halamanSubset Selection Class AssignmentAashu NemaBelum ada peringkat
- DA0101EN-Review-Introduction - Jupyter NotebookDokumen8 halamanDA0101EN-Review-Introduction - Jupyter NotebookSohail DoulahBelum ada peringkat
- Object: Database (Training) Script Date: 01/25/2013 10:44:14Dokumen4 halamanObject: Database (Training) Script Date: 01/25/2013 10:44:14Reo GuptaBelum ada peringkat
- Console MP - LogDokumen53 halamanConsole MP - LogHarry ZbBelum ada peringkat
- Adfs O365Dokumen10 halamanAdfs O365smisatBelum ada peringkat
- Dpa Lab Practical File All Iu2041230030Dokumen22 halamanDpa Lab Practical File All Iu2041230030Devansh ChauhanBelum ada peringkat
- 032 Linear Regression With Time Series DataDokumen10 halaman032 Linear Regression With Time Series DataNguyễn ĐăngBelum ada peringkat
- ML Lab Manual FinalDokumen36 halamanML Lab Manual Finaltrinadhrao30112003Belum ada peringkat
- Database Connections in RDokumen10 halamanDatabase Connections in RSrđan ObradovićBelum ada peringkat
- 1 Pandas BasicsDokumen13 halaman1 Pandas BasicsBikuBelum ada peringkat
- Bonus Program FoxproDokumen18 halamanBonus Program FoxproSugiatno SakidinBelum ada peringkat
- Lecture Material 3Dokumen7 halamanLecture Material 32021me372Belum ada peringkat
- Audio ClassificationDokumen1 halamanAudio Classification1MV19ET014 Divya TABelum ada peringkat
- FDS Lab ManualDokumen48 halamanFDS Lab ManualBharathi VBelum ada peringkat
- Xii CSC Practicals-IiDokumen11 halamanXii CSC Practicals-IiSamranBelum ada peringkat
- Pip3 Install JupyterDokumen16 halamanPip3 Install Jupyterblah blBelum ada peringkat
- Lecture 1:set Up Jupyter, Import Data From Web and Select CasesDokumen16 halamanLecture 1:set Up Jupyter, Import Data From Web and Select CasesAhmed ElmiBelum ada peringkat
- PandasDokumen16 halamanPandasHoneyBelum ada peringkat
- Log HistoryDokumen5 halamanLog Historyluizito.1992Belum ada peringkat
- ThirdDokumen17 halamanThirdPraveen JoshiBelum ada peringkat
- Clone COE R12 EnvironmentDokumen11 halamanClone COE R12 EnvironmentKoushikKc ChatterjeeBelum ada peringkat
- ModifiedipDokumen27 halamanModifiedipsayantuf17Belum ada peringkat
- Practical File PythonDokumen25 halamanPractical File Pythonkaizenpro01Belum ada peringkat
- Dillidba Blogspot Com 2018 10 Configure Data Guard Switchover and HTML PDFDokumen11 halamanDillidba Blogspot Com 2018 10 Configure Data Guard Switchover and HTML PDFZakir HossenBelum ada peringkat
- Essentials of Information and Technology File: Submittedto: SubmittedbyDokumen30 halamanEssentials of Information and Technology File: Submittedto: SubmittedbySK KashyapBelum ada peringkat
- Datascience Printout1Dokumen27 halamanDatascience Printout1Vijayan .NBelum ada peringkat
- SQL Injection IISDokumen53 halamanSQL Injection IIStaha deghies100% (1)
- Creating EBCDokumen3 halamanCreating EBCThiagarajan VasudevanBelum ada peringkat
- Securing Database Contents With Transparent Data EncryptionDokumen11 halamanSecuring Database Contents With Transparent Data Encryptionmanuelcastro2009Belum ada peringkat
- Yylocalplayer Jni 2020 11 24 09 06 25 1Dokumen5 halamanYylocalplayer Jni 2020 11 24 09 06 25 1Rifaldy Rantung50% (2)
- ADF Pre-RequisitesDokumen22 halamanADF Pre-Requisitesnenucheppanu2Belum ada peringkat
- BHUSA09 Gates Oracle Met ASP Lo It SLIDESDokumen31 halamanBHUSA09 Gates Oracle Met ASP Lo It SLIDESAdrian StokesBelum ada peringkat
- 70 433Dokumen91 halaman70 433eolimabrBelum ada peringkat
- SQL Service Integration ServicesDokumen35 halamanSQL Service Integration ServicesSajan NairBelum ada peringkat
- Oracle On Premise DB Migration To AWS-RDSDokumen8 halamanOracle On Premise DB Migration To AWS-RDSSuresh KumarBelum ada peringkat
- Functionapplicationp PDFDokumen6 halamanFunctionapplicationp PDFPranav Pratap SinghBelum ada peringkat
- The Definitive Guide to Azure Data Engineering: Modern ELT, DevOps, and Analytics on the Azure Cloud PlatformDari EverandThe Definitive Guide to Azure Data Engineering: Modern ELT, DevOps, and Analytics on the Azure Cloud PlatformBelum ada peringkat
- IELTS Reading: True/False/Not Given or Yes/No/Not GivenDokumen6 halamanIELTS Reading: True/False/Not Given or Yes/No/Not GivenMamataMaharanaBelum ada peringkat
- Quiz 17 PDFDokumen1 halamanQuiz 17 PDFMamataMaharanaBelum ada peringkat
- IELTS Reading: Matching Information: Tough Sensor Can Take The HeatDokumen2 halamanIELTS Reading: Matching Information: Tough Sensor Can Take The HeatMamataMaharana50% (2)
- Quiz 6.3Dokumen1 halamanQuiz 6.3MamataMaharanaBelum ada peringkat
- IELTS Reading: Short Answer: The Price of UniversityDokumen2 halamanIELTS Reading: Short Answer: The Price of UniversityMamataMaharanaBelum ada peringkat
- IELTS Reading - Multiple Choice PDFDokumen5 halamanIELTS Reading - Multiple Choice PDFMamataMaharanaBelum ada peringkat
- IELTS Reading - Choosing A Title PDFDokumen31 halamanIELTS Reading - Choosing A Title PDFMamataMaharanaBelum ada peringkat
- IELTS Reading - Sentence Completion PDFDokumen6 halamanIELTS Reading - Sentence Completion PDFMamataMaharanaBelum ada peringkat
- Quiz 16 PDFDokumen1 halamanQuiz 16 PDFMamataMaharanaBelum ada peringkat
- IELTS Reading - Summary Exercise PDFDokumen5 halamanIELTS Reading - Summary Exercise PDFMamataMaharanaBelum ada peringkat
- NQCZQF) % Fou' FR NQCZQF) % Fou' FR NQCZQF) % Fou' FR NQCZQF) % Fou' FR NQCZQF) % Fou' FRDokumen6 halamanNQCZQF) % Fou' FR NQCZQF) % Fou' FR NQCZQF) % Fou' FR NQCZQF) % Fou' FR NQCZQF) % Fou' FRMamataMaharanaBelum ada peringkat
- Fo - K Fo - K Fo - K Fo - K Fo - K/////kue Kue Kue Kue Kue : Fo - K Fo - K Fo - K Fo - K Fo - K/////kue Kue Kue Kue KueDokumen5 halamanFo - K Fo - K Fo - K Fo - K Fo - K/////kue Kue Kue Kue Kue : Fo - K Fo - K Fo - K Fo - K Fo - K/////kue Kue Kue Kue KueMamataMaharanaBelum ada peringkat
- IELTS Reading Tips - Strategies & Comprehension PDFDokumen19 halamanIELTS Reading Tips - Strategies & Comprehension PDFMamataMaharanaBelum ada peringkat
- IELTS Reading True False Not Given - Essential Tips PDFDokumen87 halamanIELTS Reading True False Not Given - Essential Tips PDFMamataMaharanaBelum ada peringkat
- Java File Example 1: ExamplesDokumen5 halamanJava File Example 1: ExamplesMamataMaharanaBelum ada peringkat
- Outputstream Vs InputstreamDokumen12 halamanOutputstream Vs InputstreamMamataMaharanaBelum ada peringkat
- Directories in JavaDokumen4 halamanDirectories in JavaMamataMaharanaBelum ada peringkat
- LNKPKJ% LNKPKJ% LNKPKJ% LNKPKJ% LNKPKJ%: LNKPKJ% LNKPKJ% LNKPKJ% LNKPKJ% LNKPKJ%Dokumen5 halamanLNKPKJ% LNKPKJ% LNKPKJ% LNKPKJ% LNKPKJ%: LNKPKJ% LNKPKJ% LNKPKJ% LNKPKJ% LNKPKJ%MamataMaharanaBelum ada peringkat
- GKL Ckydfoleesyue GKL Ckydfoleesyue GKL Ckydfoleesyue GKL Ckydfoleesyue GKL CkydfoleesyueDokumen7 halamanGKL Ckydfoleesyue GKL Ckydfoleesyue GKL Ckydfoleesyue GKL Ckydfoleesyue GKL CkydfoleesyueMamataMaharanaBelum ada peringkat
- If - MRK Jekckbz If - MRK Jekckbz If - MRK Jekckbz If - MRK Jekckbz If - MRK JekckbzDokumen5 halamanIf - MRK Jekckbz If - MRK Jekckbz If - MRK Jekckbz If - MRK Jekckbz If - MRK JekckbzMamataMaharanaBelum ada peringkat
- Lokoyecue Lokoyecue Lokoyecue Lokoyecue Lokoyecue : Lokoyecue Lokoyecue Lokoyecue Lokoyecue LokoyecueDokumen6 halamanLokoyecue Lokoyecue Lokoyecue Lokoyecue Lokoyecue : Lokoyecue Lokoyecue Lokoyecue Lokoyecue LokoyecueMamataMaharanaBelum ada peringkat
- (Kkuiku DH Cnyrh Rlohj: Olar Hkkx&2Dokumen6 halaman(Kkuiku DH Cnyrh Rlohj: Olar Hkkx&2MamataMaharanaBelum ada peringkat
- Ge Èkjrh Osq Yky: Nlok¡ IkbDokumen3 halamanGe Èkjrh Osq Yky: Nlok¡ IkbMamataMaharanaBelum ada peringkat
- Iqlrosaq Tks Vej Gsa: Lkrok¡ IkbDokumen8 halamanIqlrosaq Tks Vej Gsa: Lkrok¡ IkbMamataMaharanaBelum ada peringkat
- Dkcqyhokyk: Vkbok¡ IkbDokumen9 halamanDkcqyhokyk: Vkbok¡ IkbMamataMaharanaBelum ada peringkat
- ghvs113 PDFDokumen3 halamanghvs113 PDFMamataMaharanaBelum ada peringkat
- Program To Print Reverse String by Using StackDokumen7 halamanProgram To Print Reverse String by Using StackHaripriya RanganathanBelum ada peringkat
- CSC186 Group Assignment - Printing ServiceDokumen21 halamanCSC186 Group Assignment - Printing ServiceSyahirah100% (2)
- Aaintroducción GIT en SCLMDokumen60 halamanAaintroducción GIT en SCLMMatias MoleroBelum ada peringkat
- Industrial Internship ReportDokumen17 halamanIndustrial Internship ReportAdityaGuptaBelum ada peringkat
- Programming 1 OBE Syllabi SampleDokumen4 halamanProgramming 1 OBE Syllabi Samplejosefalarka60% (5)
- IDL ENVI Reference Guide PDFDokumen774 halamanIDL ENVI Reference Guide PDFAshoka VanjareBelum ada peringkat
- Unbounded Spigot Algorithms For The Digits of Pi (Gibbons)Dokumen11 halamanUnbounded Spigot Algorithms For The Digits of Pi (Gibbons)gouluBelum ada peringkat
- OS Chapter 2Dokumen36 halamanOS Chapter 2maazali2735Belum ada peringkat
- 13 - Chapter 4 Technical Feasibility StudyDokumen24 halaman13 - Chapter 4 Technical Feasibility Studyangelica marasiganBelum ada peringkat
- OODBMS PresentationDokumen17 halamanOODBMS PresentationGirish Kumar NistalaBelum ada peringkat
- Clean Architecture: A Craftsman's Guide To Software Structure and DesignDokumen13 halamanClean Architecture: A Craftsman's Guide To Software Structure and DesignGaby Vilchez RojasBelum ada peringkat
- 14 Intro To Integer ProgrammingDokumen10 halaman14 Intro To Integer Programmingkavya guptaBelum ada peringkat
- Rajib Mall Lecture NotesDokumen75 halamanRajib Mall Lecture NotesAnuj NagpalBelum ada peringkat
- OMPython UserManualDokumen43 halamanOMPython UserManualVal OuBelum ada peringkat
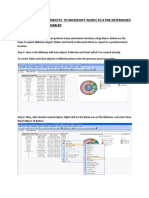
- Exporting Qlikview Objects To Microsoft Word To Predetermined LocationDokumen6 halamanExporting Qlikview Objects To Microsoft Word To Predetermined LocationJosé SalomãoBelum ada peringkat
- CH 3 Operators Statements in Python 3Dokumen23 halamanCH 3 Operators Statements in Python 3Pranav jangidBelum ada peringkat
- Python Syllabus and List of PracticalsDokumen4 halamanPython Syllabus and List of Practicalskishan chauhanBelum ada peringkat
- Python For The Network NerdDokumen30 halamanPython For The Network NerdTaras100% (1)
- PLSQL Assignments RevisedshreyDokumen8 halamanPLSQL Assignments RevisedshreyshreyaBelum ada peringkat
- Outsystems Enterprise Architect Ebook FinalDokumen24 halamanOutsystems Enterprise Architect Ebook FinalAnh NguyenBelum ada peringkat
- Operationalizing The ModelDokumen46 halamanOperationalizing The ModelMohamed RahalBelum ada peringkat
- Security Requirements Modeling Tool: For STS-Tool Version 2.1Dokumen23 halamanSecurity Requirements Modeling Tool: For STS-Tool Version 2.1Carlota MesiasBelum ada peringkat
- BLE Nordic ServicesDokumen13 halamanBLE Nordic ServicesDirceu Rodrigues JrBelum ada peringkat
- It8075 Unit 2 Cocomo IIDokumen30 halamanIt8075 Unit 2 Cocomo IIgkguruprasath007Belum ada peringkat
- ET0301 Assignment 2 BKDokumen7 halamanET0301 Assignment 2 BKSaravanan Guna SekaranBelum ada peringkat
- Oracle SQL HintsDokumen6 halamanOracle SQL HintsLakshmi Priya MacharlaBelum ada peringkat