Anda mungkin juga menyukai
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeDari EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifePenilaian: 4 dari 5 bintang4/5 (5794)
- Unit 9final 1Dokumen21 halamanUnit 9final 1jazz440Belum ada peringkat
- The Little Book of Hygge: Danish Secrets to Happy LivingDari EverandThe Little Book of Hygge: Danish Secrets to Happy LivingPenilaian: 3.5 dari 5 bintang3.5/5 (399)
- Bba103 MQP KeysDokumen15 halamanBba103 MQP KeysDr. Smita ChoudharyBelum ada peringkat
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryDari EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryPenilaian: 3.5 dari 5 bintang3.5/5 (231)
- Legal Environment of Business in IndiaDokumen17 halamanLegal Environment of Business in Indiajazz440Belum ada peringkat
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceDari EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RacePenilaian: 4 dari 5 bintang4/5 (894)
- Unit 2 Collection, Classification, and Presentation of Data: StructureDokumen20 halamanUnit 2 Collection, Classification, and Presentation of Data: Structurejazz440Belum ada peringkat
- The Yellow House: A Memoir (2019 National Book Award Winner)Dari EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Penilaian: 4 dari 5 bintang4/5 (98)
- CodeDokumen1.672 halamanCodejazz440Belum ada peringkat
- Shoe Dog: A Memoir by the Creator of NikeDari EverandShoe Dog: A Memoir by the Creator of NikePenilaian: 4.5 dari 5 bintang4.5/5 (537)
- Unit 7 Index Numbers: StructureDokumen27 halamanUnit 7 Index Numbers: Structurejazz440Belum ada peringkat
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureDari EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FuturePenilaian: 4.5 dari 5 bintang4.5/5 (474)
- BDE IPConfigOutputDokumen1 halamanBDE IPConfigOutputjazz440Belum ada peringkat
- Never Split the Difference: Negotiating As If Your Life Depended On ItDari EverandNever Split the Difference: Negotiating As If Your Life Depended On ItPenilaian: 4.5 dari 5 bintang4.5/5 (838)
- A High-Performance Telecommunications Data Warehouse Using DB2 For LinuxDokumen17 halamanA High-Performance Telecommunications Data Warehouse Using DB2 For Linuxjazz440Belum ada peringkat
- Grit: The Power of Passion and PerseveranceDari EverandGrit: The Power of Passion and PerseverancePenilaian: 4 dari 5 bintang4/5 (587)
- JavaDokumen1 halamanJavaNajib AbdillahBelum ada peringkat
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaDari EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaPenilaian: 4.5 dari 5 bintang4.5/5 (265)
- Unit 6finalDokumen20 halamanUnit 6finalAnonymous bTh744z7E6Belum ada peringkat
- Unit 2final 1Dokumen19 halamanUnit 2final 1jazz440Belum ada peringkat
- Economic Systems in Business EnvironmentDokumen17 halamanEconomic Systems in Business Environmentjazz440Belum ada peringkat
- The Emperor of All Maladies: A Biography of CancerDari EverandThe Emperor of All Maladies: A Biography of CancerPenilaian: 4.5 dari 5 bintang4.5/5 (271)
- Unit 2 Collection, Classification, and Presentation of Data: StructureDokumen20 halamanUnit 2 Collection, Classification, and Presentation of Data: Structurejazz440Belum ada peringkat
- On Fire: The (Burning) Case for a Green New DealDari EverandOn Fire: The (Burning) Case for a Green New DealPenilaian: 4 dari 5 bintang4/5 (73)
- Unit 6finalDokumen24 halamanUnit 6finaljazz440Belum ada peringkat
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersDari EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersPenilaian: 4.5 dari 5 bintang4.5/5 (344)
- Ewr Terminal BDokumen1 halamanEwr Terminal Bjazz440Belum ada peringkat
- Team of Rivals: The Political Genius of Abraham LincolnDari EverandTeam of Rivals: The Political Genius of Abraham LincolnPenilaian: 4.5 dari 5 bintang4.5/5 (234)
- Schedule Week4 Nov 2014 For StudentsDokumen6 halamanSchedule Week4 Nov 2014 For Studentsjazz440Belum ada peringkat
- FDA Forms For Medicines Shipments Only To USADokumen2 halamanFDA Forms For Medicines Shipments Only To USAjazz440Belum ada peringkat
- Research Method Test1-AugDokumen2 halamanResearch Method Test1-Augjazz440Belum ada peringkat
- Rise of ISIS: A Threat We Can't IgnoreDari EverandRise of ISIS: A Threat We Can't IgnorePenilaian: 3.5 dari 5 bintang3.5/5 (137)
- Listening Answer SheetDokumen1 halamanListening Answer Sheetjazz440Belum ada peringkat
- (IELTS-Fighter) - IELTS Speaking Part 2 by Simon PDFDokumen26 halaman(IELTS-Fighter) - IELTS Speaking Part 2 by Simon PDFblackbacBelum ada peringkat
- The Unwinding: An Inner History of the New AmericaDari EverandThe Unwinding: An Inner History of the New AmericaPenilaian: 4 dari 5 bintang4/5 (45)
- 32 Ielts Essay Samples Band 9Dokumen34 halaman32 Ielts Essay Samples Band 9mh73% (26)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyDari EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyPenilaian: 3.5 dari 5 bintang3.5/5 (2219)
- Canada MigrationDokumen14 halamanCanada Migrationjazz440Belum ada peringkat
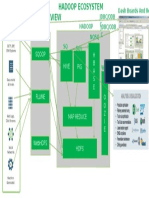
- Hadoop Ecosystem PresentationDokumen1 halamanHadoop Ecosystem Presentationjazz440Belum ada peringkat
- Gotham Deep Square Pan CookbookDokumen38 halamanGotham Deep Square Pan Cookbookjazz440Belum ada peringkat
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreDari EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You ArePenilaian: 4 dari 5 bintang4/5 (1090)
- Express Entry System: Information For Skilled Foreign WorkersDokumen16 halamanExpress Entry System: Information For Skilled Foreign WorkersTitoFernandezBelum ada peringkat
- Hadoop SetupDokumen43 halamanHadoop Setupjazz440Belum ada peringkat
- Monthly calendar 2017Dokumen12 halamanMonthly calendar 2017jazz440Belum ada peringkat
- Linux Basic Commands GuideDokumen26 halamanLinux Basic Commands GuidedhivyaBelum ada peringkat
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)Dari EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Penilaian: 4.5 dari 5 bintang4.5/5 (119)
- Bigtable: A Distributed Storage System For Structured DataDokumen14 halamanBigtable: A Distributed Storage System For Structured DataMax ChiuBelum ada peringkat
- AbDokumen13 halamanAbSk.Abdul NaveedBelum ada peringkat
- OracleDokumen26 halamanOracleДелије НикшићBelum ada peringkat
- Chrome FlagsDokumen12 halamanChrome Flagsmeraj1210% (1)
- Motenergy Me1507 Technical DrawingDokumen1 halamanMotenergy Me1507 Technical DrawingHilioBelum ada peringkat
- Engineering Thermodynamics Work and Heat Transfer 4th Edition by GFC Rogers Yon Mayhew 0582045665 PDFDokumen5 halamanEngineering Thermodynamics Work and Heat Transfer 4th Edition by GFC Rogers Yon Mayhew 0582045665 PDFFahad HasanBelum ada peringkat
- Receiving of Packaging Material SOPDokumen4 halamanReceiving of Packaging Material SOPanoushia alviBelum ada peringkat
- LLRP PROTOCOLDokumen19 halamanLLRP PROTOCOLRafo ValverdeBelum ada peringkat
- Well Logging 1Dokumen33 halamanWell Logging 1Spica FadliBelum ada peringkat
- InapDokumen38 halamanInapSourav Jyoti DasBelum ada peringkat
- INGLESDokumen20 halamanINGLESNikollay PeñaBelum ada peringkat
- 55fbb8b0dd37d Productive SkillDokumen6 halaman55fbb8b0dd37d Productive SkilldewiBelum ada peringkat
- Her Body and Other Parties: StoriesDari EverandHer Body and Other Parties: StoriesPenilaian: 4 dari 5 bintang4/5 (821)
- English Language and Applied Linguistics Textbooks Lo Res USDDokumen61 halamanEnglish Language and Applied Linguistics Textbooks Lo Res USDJames Blackburn Quéré Cutbirth100% (2)
- RoboServer Users Guide PDFDokumen25 halamanRoboServer Users Guide PDFdavid0young_2Belum ada peringkat
- Lesson Plan-Brainstorming Session For The Group Occupational Report-Jmeck Wfed495c-2 V4a7Dokumen2 halamanLesson Plan-Brainstorming Session For The Group Occupational Report-Jmeck Wfed495c-2 V4a7api-312884329Belum ada peringkat
- Lpi - 101-500Dokumen6 halamanLpi - 101-500Jon0% (1)
- Learning OrganizationDokumen104 halamanLearning Organizationanandita28100% (2)
- Soft Start - Altistart 48 - VX4G481Dokumen2 halamanSoft Start - Altistart 48 - VX4G481the hawakBelum ada peringkat
- Blueprint 7 Student Book Teachers GuideDokumen128 halamanBlueprint 7 Student Book Teachers GuideYo Rk87% (38)
- David Sosa - The Import of The Puzzle About BeliefDokumen31 halamanDavid Sosa - The Import of The Puzzle About BeliefSr. DanieoBelum ada peringkat
- Newsletter April.Dokumen4 halamanNewsletter April.J_Hevicon4246Belum ada peringkat
- Differential Aptitude TestsDokumen2 halamanDifferential Aptitude Testsiqrarifat50% (4)
- JCL RefresherDokumen50 halamanJCL RefresherCosta48100% (1)
- Nikbakht H. EFL Pronunciation Teaching - A Theoretical Review.Dokumen30 halamanNikbakht H. EFL Pronunciation Teaching - A Theoretical Review.researchdomain100% (1)
- 3rd Year-Industrial Training Letter SampleDokumen3 halaman3rd Year-Industrial Training Letter SampleSai GowthamBelum ada peringkat
- Aspen TutorialDokumen33 halamanAspen TutorialSarah RasheedBelum ada peringkat
- Escaping The Digital Dark AgeDokumen5 halamanEscaping The Digital Dark AgeKarlos lacalleBelum ada peringkat
- Vblock® Systems Password ManagementDokumen22 halamanVblock® Systems Password ManagementVakul BhattBelum ada peringkat
- Devki N Bhatt01240739754Dokumen10 halamanDevki N Bhatt01240739754menuselectBelum ada peringkat
- Win10 Backup Checklist v3 PDFDokumen1 halamanWin10 Backup Checklist v3 PDFsubwoofer123Belum ada peringkat