Anda mungkin juga menyukai
- Tipos de GráficasDokumen11 halamanTipos de GráficasMonse Herrera'0% (1)
- Linea Del Tiempo Estudio Dificultedes de AprendizajeDokumen2 halamanLinea Del Tiempo Estudio Dificultedes de AprendizajeLuis Enrique80% (15)
- MaloDokumen19 halamanMaloCarolina Durango GuerraBelum ada peringkat
- Clase Graficos UnivariadosDokumen7 halamanClase Graficos UnivariadosTimothy BarlowBelum ada peringkat
- HistogramaDokumen5 halamanHistogramaLESLIE STEPHANIE DIAZ ROMEROBelum ada peringkat
- Representación GráficaDokumen7 halamanRepresentación GráficaCLAUDIA LUCENDO GUILLANBelum ada peringkat
- Histograma InvestigaciónDokumen2 halamanHistograma InvestigaciónJoelly Alejandra Rodríguez EsquedaBelum ada peringkat
- PROTOCOLO COLABORATIVO 2 Estadística DescriptivaDokumen6 halamanPROTOCOLO COLABORATIVO 2 Estadística DescriptivaSara RamosBelum ada peringkat
- Cuestionario Sobre GráficosDokumen4 halamanCuestionario Sobre GráficosSheyla BautistaBelum ada peringkat
- Gráficas en EstadísticaDokumen3 halamanGráficas en EstadísticaMoises VeyvideaBelum ada peringkat
- 9.2 Matplotlip DiagramasDokumen17 halaman9.2 Matplotlip DiagramasEsteban Jimenez RojasBelum ada peringkat
- Album de Estadistica Jailin Gomez y Valeria Jimena PDFDokumen51 halamanAlbum de Estadistica Jailin Gomez y Valeria Jimena PDFnadly gomezBelum ada peringkat
- Histograma de FrecuenciasDokumen20 halamanHistograma de FrecuenciasJesus FernandezBelum ada peringkat
- Tablas de Frcuencias Actividad 2 Del 20 de FebreroDokumen9 halamanTablas de Frcuencias Actividad 2 Del 20 de FebreroAura Cristina CERON OCOGUAJEBelum ada peringkat
- Representación Gráfica (Economia F1-Estadística)Dokumen7 halamanRepresentación Gráfica (Economia F1-Estadística)jonathan alejandroBelum ada peringkat
- GraficasDokumen2 halamanGraficasSteffany GómezBelum ada peringkat
- Tipos de Gráficos EstadisticosDokumen6 halamanTipos de Gráficos EstadisticoskarenBelum ada peringkat
- Gráficos EstadísticosDokumen26 halamanGráficos Estadísticossandra_quispe12Belum ada peringkat
- GráficasDokumen6 halamanGráficasPe AngelBelum ada peringkat
- GraficoDokumen9 halamanGraficoFreddyAngelOrtizBelum ada peringkat
- Tipos de Gráficos y Sus AplicacionesDokumen7 halamanTipos de Gráficos y Sus AplicacionesWENDY YAMILETH CASTRO HERNANDEZBelum ada peringkat
- Tipos de GraficasDokumen3 halamanTipos de GraficasRhafa ChelBelum ada peringkat
- Tarea2 - Equipo 2 MicroeconomiaDokumen5 halamanTarea2 - Equipo 2 MicroeconomiaAylin Monserrat Caamal PechBelum ada peringkat
- Representación Gráfica de Los Datos-2Dokumen13 halamanRepresentación Gráfica de Los Datos-2CARLOS ALBERTO VERA MACHUCABelum ada peringkat
- Importancia de Los Tipos de Graficas EstadisticasDokumen5 halamanImportancia de Los Tipos de Graficas Estadisticascarlos armando juarez noeBelum ada peringkat
- Estadistica SofDokumen14 halamanEstadistica SofINFANTES RIVAS INGRID MARISELLABelum ada peringkat
- Album de GraficosDokumen10 halamanAlbum de Graficosiris dominguezBelum ada peringkat
- Graficas y TablasDokumen12 halamanGraficas y Tablascarime yajayra cabreraBelum ada peringkat
- SEMANA 10. Graficos EstadisticosDokumen13 halamanSEMANA 10. Graficos EstadisticosQuispe Sullca, EdgarBelum ada peringkat
- HistogramaDokumen12 halamanHistogramaJaanett' GuzzmánnBelum ada peringkat
- Grafica de LíneasDokumen8 halamanGrafica de Líneasjose francisco gomez cazaresBelum ada peringkat
- Tipos de GraficaDokumen14 halamanTipos de GraficaIrvin jose Hernández chulinBelum ada peringkat
- Tipos de GráficasDokumen4 halamanTipos de GráficasCarlos CristianBelum ada peringkat
- Tipos de Graficas EstadisticaDokumen1 halamanTipos de Graficas EstadisticaGustavo Moran100% (1)
- Grafico de Bastones - EstadisticaDokumen19 halamanGrafico de Bastones - EstadisticaYeison Smith Perez JulonBelum ada peringkat
- EstadisticaDokumen9 halamanEstadisticaSujey0% (1)
- Gráficos MHS (2023)Dokumen10 halamanGráficos MHS (2023)Yami GonzalezBelum ada peringkat
- Gráficas EstadísticasDokumen9 halamanGráficas EstadísticasEdmar GarciaBelum ada peringkat
- Wuolah Free App 1706189292541 Gulag FreeDokumen14 halamanWuolah Free App 1706189292541 Gulag Freejaja jajaBelum ada peringkat
- Tipos Elementos y Caracteristicas de GraficasDokumen17 halamanTipos Elementos y Caracteristicas de GraficasDaniel Alfredo Piña CandelariaBelum ada peringkat
- Copia de Tarea BioestDokumen8 halamanCopia de Tarea Bioestmaryferst27hBelum ada peringkat
- Ordenamiento de DatosDokumen32 halamanOrdenamiento de DatosRomán Terrazas ValdezBelum ada peringkat
- Introducción A Las Representaciones GraficasDokumen14 halamanIntroducción A Las Representaciones GraficasMayerlín Obregón BenítezBelum ada peringkat
- Graficos y Cuadros de Datos EstadisticosDokumen14 halamanGraficos y Cuadros de Datos EstadisticosA L E J A N D R ABelum ada peringkat
- Que Es Un GraficoDokumen2 halamanQue Es Un GraficoIoetRoqBelum ada peringkat
- Histograma: Representación Gráfica de Una Variable en Forma de BarrasDokumen28 halamanHistograma: Representación Gráfica de Una Variable en Forma de BarrasJose Luis Galvan RodriguezBelum ada peringkat
- GRAFICASDokumen9 halamanGRAFICASFernando OvandoBelum ada peringkat
- Representacion Grafica DistribucionDokumen9 halamanRepresentacion Grafica DistribucionRuth Magdalena Pullaguari PinedaBelum ada peringkat
- GráficaDokumen2 halamanGráficaGame WorldBelum ada peringkat
- RStudio Graficas - Estadistica DescriptivaDokumen15 halamanRStudio Graficas - Estadistica DescriptivaFernandito TancaraBelum ada peringkat
- Apuntes GraficosDokumen7 halamanApuntes GraficosCeleste RiquelmeBelum ada peringkat
- 2 Gráficos para Una Variable Cuantitativa - Gráficos Con RDokumen22 halaman2 Gráficos para Una Variable Cuantitativa - Gráficos Con RArturo MedinaBelum ada peringkat
- ForoAnalice La Importancia de La Identificación de Las Variables para La Organización y Presentación de Información.Dokumen9 halamanForoAnalice La Importancia de La Identificación de Las Variables para La Organización y Presentación de Información.cristhian galeanoBelum ada peringkat
- Histogramas y Diagramas de ParetoDokumen5 halamanHistogramas y Diagramas de ParetoCristyan SabillonBelum ada peringkat
- Estadistica I Act 3 Corte I Trimestre IVDokumen19 halamanEstadistica I Act 3 Corte I Trimestre IVMaria LopezBelum ada peringkat
- Graficos MatematicasDokumen20 halamanGraficos MatematicasCarlos Santibañez100% (1)
- Segundo Informe Estadistico de Estadistica Descriptiva Seccion 02Dokumen9 halamanSegundo Informe Estadistico de Estadistica Descriptiva Seccion 02Karismel HenríquezBelum ada peringkat
- Histogram ADokumen13 halamanHistogram ANorelys MaitaBelum ada peringkat
- Histograma PDFDokumen4 halamanHistograma PDFAlejo Ticona100% (1)
- Histograma de imagen: Revelando conocimientos visuales, explorando las profundidades de los histogramas de imágenes en visión por computadoraDari EverandHistograma de imagen: Revelando conocimientos visuales, explorando las profundidades de los histogramas de imágenes en visión por computadoraBelum ada peringkat
- GUÍA PARA EL DESARROLLO DE LA INTELIGENCIA EMOCIONAL GRADO 1° y 2°Dokumen11 halamanGUÍA PARA EL DESARROLLO DE LA INTELIGENCIA EMOCIONAL GRADO 1° y 2°Angela CastelblancoBelum ada peringkat
- Actividad Religion 2ºDokumen3 halamanActividad Religion 2ºMar CumaBelum ada peringkat
- El Impacto Político y Jurídico de La Constitución Del 2010 y Sus Perspectivas en El Plano InstitucionalDokumen2 halamanEl Impacto Político y Jurídico de La Constitución Del 2010 y Sus Perspectivas en El Plano InstitucionalEscuela Enrique Chamberlain100% (1)
- Planificación Lenguaje Unidad 1 4° A 2023Dokumen7 halamanPlanificación Lenguaje Unidad 1 4° A 2023Marcela QuilodranBelum ada peringkat
- Clasificacion de Brazos RoboticosDokumen12 halamanClasificacion de Brazos RoboticosRichard Muñoz100% (1)
- Actividades y Actividad IntegradoraDokumen12 halamanActividades y Actividad IntegradoraEdgar perezBelum ada peringkat
- Res DNCP 4366 23Dokumen23 halamanRes DNCP 4366 23alb_navBelum ada peringkat
- 45 Frases de Grandes Hombres Que Machacaron Cruelmente La Imagen de La MujerDokumen4 halaman45 Frases de Grandes Hombres Que Machacaron Cruelmente La Imagen de La MujerPedro Cañizares CuadraBelum ada peringkat
- Ley de Okun en El PeruDokumen41 halamanLey de Okun en El PeruAldo Rojas Sánchez100% (1)
- Fijación de PreciosDokumen29 halamanFijación de PreciosMac BookBelum ada peringkat
- Guía 6Dokumen9 halamanGuía 6Brigette AvilaBelum ada peringkat
- Talleres Algebra LinealDokumen15 halamanTalleres Algebra LinealMiguel CruzBelum ada peringkat
- Certificado PDFDokumen2 halamanCertificado PDFzlatna marcela mejia molinaBelum ada peringkat
- Principios Regulatorios Del PresupuestoDokumen3 halamanPrincipios Regulatorios Del PresupuestoJose Luis Rodriguez100% (2)
- Crítica Literaria y GéneroDokumen164 halamanCrítica Literaria y GéneroAnaLauraBelum ada peringkat
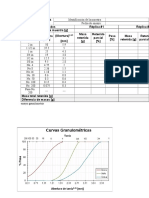
- Ensayos de Granulometria Contenidode Humedad y Conprecion SimpleDokumen4 halamanEnsayos de Granulometria Contenidode Humedad y Conprecion SimpleOber ZelaBelum ada peringkat
- Generalidades de Los LíquidosDokumen3 halamanGeneralidades de Los LíquidosMaria Jose Rodriguez GaonaBelum ada peringkat
- Trabajo en Bitácora en El Encuentro Grupal VDokumen4 halamanTrabajo en Bitácora en El Encuentro Grupal VJenniffer Gomez0% (1)
- Propuesta Metodológica para El Mejoramiento Nutricional de Preparaciones Comunes en La Dieta Escolar - MatrizDokumen9 halamanPropuesta Metodológica para El Mejoramiento Nutricional de Preparaciones Comunes en La Dieta Escolar - Matrizsimón encarnación rivas tiledoBelum ada peringkat
- Le Corbusier - VeneciaDokumen12 halamanLe Corbusier - VeneciaErika NicoBelum ada peringkat
- Estatutos Agrosolidaria Mas Camara de Comercio.Dokumen33 halamanEstatutos Agrosolidaria Mas Camara de Comercio.Carlos Ivan CamargoBelum ada peringkat
- Situaciones para Estudiar FraccionesDokumen7 halamanSituaciones para Estudiar FraccionesVictoria MontenegroBelum ada peringkat
- Psicologia EspecialDokumen8 halamanPsicologia EspecialLuis Marcelo ValergaBelum ada peringkat
- Norma NTC 5480 (Final)Dokumen21 halamanNorma NTC 5480 (Final)oscar espinelBelum ada peringkat
- Curso: EE354 Análisis de Sistemas de Potencia II: Escuela Profesional de Ingeniería EléctricaDokumen21 halamanCurso: EE354 Análisis de Sistemas de Potencia II: Escuela Profesional de Ingeniería EléctricaULISES MARIANO MAYANGA MENDOZABelum ada peringkat
- Cronología de La PandemiaDokumen2 halamanCronología de La PandemiabajolamismasombraBelum ada peringkat
- SISTEMA NACIONAL DE GESTIÓN DE RECURSOS HUMANOS Parte 1Dokumen15 halamanSISTEMA NACIONAL DE GESTIÓN DE RECURSOS HUMANOS Parte 1Kathy FloresBelum ada peringkat
- Business Model CanvasDokumen1 halamanBusiness Model CanvasSalvador GonzálezBelum ada peringkat
- Presentación Clase Identificación 2017Dokumen19 halamanPresentación Clase Identificación 2017Romina BrugmanBelum ada peringkat