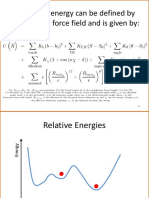
Anda mungkin juga menyukai
- 011-0161 An Integrated Inventory Control and Facility Location System With Capacity Constraints: A Multi-Objective Evolutionary ApproachDokumen25 halaman011-0161 An Integrated Inventory Control and Facility Location System With Capacity Constraints: A Multi-Objective Evolutionary ApproachomkarbhaskarBelum ada peringkat
- A New Concept for Tuning Design Weights in Survey Sampling: Jackknifing in Theory and PracticeDari EverandA New Concept for Tuning Design Weights in Survey Sampling: Jackknifing in Theory and PracticeBelum ada peringkat
- An Inventory-Location Model for Distribution CentersDokumen24 halamanAn Inventory-Location Model for Distribution CentersAliBelum ada peringkat
- Supply Chain Network Design Optimization Model For Multi-Period Multi-Product Under UncertaintyDokumen12 halamanSupply Chain Network Design Optimization Model For Multi-Period Multi-Product Under UncertaintyShiba Narayan SahuBelum ada peringkat
- J Dib 2020 105142Dokumen6 halamanJ Dib 2020 105142Muhammad ShahfiqBelum ada peringkat
- Reverse Logistics Network Design A State-Of-The-Art Literature ReviewDokumen7 halamanReverse Logistics Network Design A State-Of-The-Art Literature ReviewshjpotpifBelum ada peringkat
- IJIS2020 AcceptedVesrionDokumen26 halamanIJIS2020 AcceptedVesrionnyandeniunhlakaBelum ada peringkat
- Mathematical ModelDokumen8 halamanMathematical ModelShubham GaonkarBelum ada peringkat
- Demand forecasting for oil inventory using limited dataDokumen9 halamanDemand forecasting for oil inventory using limited dataJorge RomeroBelum ada peringkat
- A Bi-Objective Supply Chain Design Problem With Uncertainty by Cardona-Valdes (2011)Dokumen12 halamanA Bi-Objective Supply Chain Design Problem With Uncertainty by Cardona-Valdes (2011)jerc1324Belum ada peringkat
- An Inventory-Location Model with Working and Safety Stock CostsDokumen32 halamanAn Inventory-Location Model with Working and Safety Stock CostsEduardo GonzálezBelum ada peringkat
- Fuzzy Optimal Inventory and Shipment Policy On Non - Coordinated Supply Chain Under Quadratic Price Dependent DemandDokumen10 halamanFuzzy Optimal Inventory and Shipment Policy On Non - Coordinated Supply Chain Under Quadratic Price Dependent DemandIJRASETPublicationsBelum ada peringkat
- Genetic Algorithm For Vehicle Routing Problem With BackhaulsDokumen8 halamanGenetic Algorithm For Vehicle Routing Problem With BackhaulsYuri Adixs Ucux'saeBelum ada peringkat
- 2 - A Two Phase Local Search With A Discrete-Event Heuristic For The Omnichannel Vehicle Routing ProblemDokumen14 halaman2 - A Two Phase Local Search With A Discrete-Event Heuristic For The Omnichannel Vehicle Routing Problemgiangtran.89224020022Belum ada peringkat
- 2018 - Machine LearningDokumen56 halaman2018 - Machine LearningRosnani Ginting TBABelum ada peringkat
- Solving Facility Location Problems with Center of Gravity and P-Median ApproachesDokumen30 halamanSolving Facility Location Problems with Center of Gravity and P-Median ApproachesAbhishek PadhyeBelum ada peringkat
- Multi-stage stochastic integer programming approach for capacity expansion under uncertaintyDokumen23 halamanMulti-stage stochastic integer programming approach for capacity expansion under uncertaintyLavi SahuBelum ada peringkat
- OR2 - Transportation Cost Optimization - Nawaf Alshaikh1Dokumen7 halamanOR2 - Transportation Cost Optimization - Nawaf Alshaikh1Nawaf ALshaikhBelum ada peringkat
- Coordination Schemes For Decentralized Supply Chain PlanningDokumen5 halamanCoordination Schemes For Decentralized Supply Chain PlanningengrohitsinghalBelum ada peringkat
- A Multiobjective Optimization Method For Strategic: Sourcing and Inventory ReplenishmentDokumen6 halamanA Multiobjective Optimization Method For Strategic: Sourcing and Inventory ReplenishmentManjiree Ingole JoshiBelum ada peringkat
- Mixed Integer PROGRAMMINGDokumen11 halamanMixed Integer PROGRAMMINGSumit DhallBelum ada peringkat
- Literature Review On Application of Linear ProgrammingDokumen6 halamanLiterature Review On Application of Linear ProgrammingafmabreouxqmrcBelum ada peringkat
- Icmiee Pi 140224Dokumen5 halamanIcmiee Pi 140224Rizwan KhanBelum ada peringkat
- A Supply Chain Network Design Optimization Model From The Perspective of A Retail Distribution Supply ChainDokumen5 halamanA Supply Chain Network Design Optimization Model From The Perspective of A Retail Distribution Supply ChainHimadri Sen GuptaBelum ada peringkat
- Sciencedirect: Joint Optimization of Production Planning and Capacity Adjustment For Assembly SystemDokumen6 halamanSciencedirect: Joint Optimization of Production Planning and Capacity Adjustment For Assembly SystemCESARPINEDABelum ada peringkat
- MidtermADM3302M SolutionDokumen5 halamanMidtermADM3302M SolutionAlbur Raheem-Jabar100% (1)
- IBIMA Walid Ellili PDFDokumen18 halamanIBIMA Walid Ellili PDFWalid ElliliBelum ada peringkat
- Solving Real-Time Truck-to-Door Assignment at Cross Docking WarehousesDokumen17 halamanSolving Real-Time Truck-to-Door Assignment at Cross Docking WarehousesakshatBelum ada peringkat
- UntitledDokumen19 halamanUntitledIsabel Zanella ZancaBelum ada peringkat
- Value Based Strategic Distributed Generator Placement by Particle Swarm OptimizationDokumen6 halamanValue Based Strategic Distributed Generator Placement by Particle Swarm OptimizationInternational Organization of Scientific Research (IOSR)Belum ada peringkat
- Computers and Operations Research: Franco Quezada, Céline Gicquel, Safia Kedad-Sidhoum, Dong Quan VuDokumen15 halamanComputers and Operations Research: Franco Quezada, Céline Gicquel, Safia Kedad-Sidhoum, Dong Quan VuQuỳnh NguyễnBelum ada peringkat
- Network DesignDokumen23 halamanNetwork Designdishita kaushikBelum ada peringkat
- International Journal of Computational Engineering Research (IJCER)Dokumen6 halamanInternational Journal of Computational Engineering Research (IJCER)International Journal of computational Engineering research (IJCER)Belum ada peringkat
- Developing a Supply Chain Network Model for Piecewise Transportation CostsDokumen8 halamanDeveloping a Supply Chain Network Model for Piecewise Transportation CostsHa TranBelum ada peringkat
- Learning Automata Based Method For Grid Computing Resource Valuation With Resource Suitability CriteriaDokumen9 halamanLearning Automata Based Method For Grid Computing Resource Valuation With Resource Suitability CriteriaijgcaBelum ada peringkat
- Literature Review On Linear ProgrammingDokumen5 halamanLiterature Review On Linear Programmingea0kvft0100% (1)
- Warehouse LocationDokumen14 halamanWarehouse LocationAdhitya Sulis HandonoBelum ada peringkat
- Excel Solver for Linear Programming ProblemsDokumen9 halamanExcel Solver for Linear Programming Problemsmay_soulBelum ada peringkat
- Dynamic Approach To K-Means Clustering Algorithm-2Dokumen16 halamanDynamic Approach To K-Means Clustering Algorithm-2IAEME PublicationBelum ada peringkat
- DynamicclusteringDokumen6 halamanDynamicclusteringkasun prabhathBelum ada peringkat
- A Retrial Queueing Model With Thresholds and Phase Type Retrial TDokumen24 halamanA Retrial Queueing Model With Thresholds and Phase Type Retrial TK SanthiSrinivasanBelum ada peringkat
- A Method To Build A Representation Using A Classifier and Its Use in A K Nearest Neighbors-Based DeploymentDokumen8 halamanA Method To Build A Representation Using A Classifier and Its Use in A K Nearest Neighbors-Based DeploymentRaghunath CherukuriBelum ada peringkat
- Challenges in Modeling Demand For InventDokumen7 halamanChallenges in Modeling Demand For InventFernando Rojas ZuñigaBelum ada peringkat
- ADD6Dokumen9 halamanADD6Chetan ChaudhariBelum ada peringkat
- Second Priced Dynamic Auction MechanismDokumen5 halamanSecond Priced Dynamic Auction Mechanismsurendiran123Belum ada peringkat
- Customer Segmentation Using Unsupervised Learning On Daily Energy Load ProfilesDokumen7 halamanCustomer Segmentation Using Unsupervised Learning On Daily Energy Load ProfilesPablo OrricoBelum ada peringkat
- A Locationa Inventory Supply Chain ProblDokumen9 halamanA Locationa Inventory Supply Chain ProblNguyễn QuỳnhBelum ada peringkat
- Rev LogDokumen18 halamanRev LogSHRAYANSH AGARWALBelum ada peringkat
- Customer Churn Prediction in Banking Sector - A Hybrid ApproachDokumen6 halamanCustomer Churn Prediction in Banking Sector - A Hybrid ApproachIJRASETPublicationsBelum ada peringkat
- Aggregate Planning in Manufacturing Company - Linear Programming ApproachDokumen8 halamanAggregate Planning in Manufacturing Company - Linear Programming ApproachMawar NooviaBelum ada peringkat
- Data Analysis and Mining: Solutions To Practice ExercisesDokumen3 halamanData Analysis and Mining: Solutions To Practice ExercisesBada SainathBelum ada peringkat
- Ondemand Warehousing2Dokumen52 halamanOndemand Warehousing2Gaurav SinghBelum ada peringkat
- Mathematical and Computer Modelling: R.K. Gupta, A.K. Bhunia, S.K. GoyalDokumen13 halamanMathematical and Computer Modelling: R.K. Gupta, A.K. Bhunia, S.K. Goyaltimeking00Belum ada peringkat
- Parallel GA optimizes generation expansion planningDokumen8 halamanParallel GA optimizes generation expansion planningbhumaniBelum ada peringkat
- Optimal Distributed Generation Placement Using Ant Colony OptimizationDokumen6 halamanOptimal Distributed Generation Placement Using Ant Colony OptimizationPervez AhmadBelum ada peringkat
- Cost Optimize in Could ComputingDokumen4 halamanCost Optimize in Could Computingpaid workBelum ada peringkat
- Reviewed Ds Project Report For Group 2Dokumen19 halamanReviewed Ds Project Report For Group 2Daddy MewariBelum ada peringkat
- Computers & Industrial Engineering: Ali Diabat, Effrosyni TheodorouDokumen9 halamanComputers & Industrial Engineering: Ali Diabat, Effrosyni TheodorouQuỳnh NguyễnBelum ada peringkat
- Clustering Techniques and Their Applications in EngineeringDokumen16 halamanClustering Techniques and Their Applications in EngineeringIgor Demetrio100% (1)
- Paper Schedulling Ruiz y MarotoDokumen20 halamanPaper Schedulling Ruiz y Marotojkl316Belum ada peringkat
- I Jcs It 2014050535Dokumen5 halamanI Jcs It 2014050535jkl316Belum ada peringkat
- MOEA Optimization Using NSGA-IIDokumen20 halamanMOEA Optimization Using NSGA-IInim1987Belum ada peringkat
- Proceedings of 2010 Int'l Conf on Industrial EngineeringDokumen6 halamanProceedings of 2010 Int'l Conf on Industrial Engineeringjkl316Belum ada peringkat
- Multiple Criteria Decision Analysis Using A Likelihood-Based Outranking Method Based On Interval-Valued Intuitionistic Fuzzy SetsDokumen21 halamanMultiple Criteria Decision Analysis Using A Likelihood-Based Outranking Method Based On Interval-Valued Intuitionistic Fuzzy Setsjkl316Belum ada peringkat
- Created by Neevia Docuprinter Trial Version Created by Neevia Docuprinter Trial VersionDokumen7 halamanCreated by Neevia Docuprinter Trial Version Created by Neevia Docuprinter Trial Versionjkl316Belum ada peringkat
- SymbrainDokumen26 halamanSymbrainCaterina CarboneBelum ada peringkat
- Tabu Search PDFDokumen294 halamanTabu Search PDFjkl316Belum ada peringkat
- JF 24 PDFDokumen6 halamanJF 24 PDFjkl316Belum ada peringkat
- Core-Generating Approximate Minimum Entropy Discretization For Rough Set Feature Selection in Pattern ClassificationDokumen8 halamanCore-Generating Approximate Minimum Entropy Discretization For Rough Set Feature Selection in Pattern Classificationjkl316Belum ada peringkat
- Optimization of Neural Networks: A Comparative Analysis of The Genetic Algorithm and Simulated AnnealingDokumen28 halamanOptimization of Neural Networks: A Comparative Analysis of The Genetic Algorithm and Simulated Annealingjkl316Belum ada peringkat
- Algorithms For Association Rule Mining - A General Survey and ComparisonDokumen7 halamanAlgorithms For Association Rule Mining - A General Survey and Comparisonjkl316Belum ada peringkat
- Sabp PDFDokumen25 halamanSabp PDFjkl316Belum ada peringkat
- Information Sciences: Doina BucurDokumen16 halamanInformation Sciences: Doina Bucurjkl316Belum ada peringkat
- Core-Generating Approximate Minimum Entropy Discretization For Rough Set Feature Selection in Pattern ClassificationDokumen18 halamanCore-Generating Approximate Minimum Entropy Discretization For Rough Set Feature Selection in Pattern Classificationjkl316Belum ada peringkat
- Grue AssocDokumen65 halamanGrue Assocjkl316Belum ada peringkat
- The Use of Evolutionary Algorithms in Data MiningDokumen29 halamanThe Use of Evolutionary Algorithms in Data Miningjkl316Belum ada peringkat
- Knowledge Discovery With Genetic Programming For Providing Feedback To Courseware AuthorsDokumen40 halamanKnowledge Discovery With Genetic Programming For Providing Feedback To Courseware Authorsjkl316Belum ada peringkat
- Microsoft Word - JCD FinalDokumen8 halamanMicrosoft Word - JCD Finaljkl316Belum ada peringkat
- Graph Based Approaches Used in Association Rule MiningDokumen64 halamanGraph Based Approaches Used in Association Rule MiningNguyen Van HuyBelum ada peringkat
- Multiobjective Optimization Based On ReputationDokumen22 halamanMultiobjective Optimization Based On Reputationjkl316Belum ada peringkat
- Generalized Association Rule Mining Using Genetic Algorithms (GADokumen11 halamanGeneralized Association Rule Mining Using Genetic Algorithms (GAAnonymous TxPyX8cBelum ada peringkat
- Design of Fuzzy Rule-Based Classifiers With Semantic CointensionDokumen17 halamanDesign of Fuzzy Rule-Based Classifiers With Semantic Cointensionjkl316Belum ada peringkat
- TU Berka-Rauch PaperDokumen30 halamanTU Berka-Rauch Paperjkl316Belum ada peringkat
- Validationofassociationrulemining ACI2013 Wright SittigDokumen10 halamanValidationofassociationrulemining ACI2013 Wright Sittigjkl316Belum ada peringkat
- Genetic Algorithms For Multi-Criterion Classification and Clustering in Data MiningDokumen12 halamanGenetic Algorithms For Multi-Criterion Classification and Clustering in Data Miningjkl316Belum ada peringkat
- Design of Fuzzy Rule-Based Classifiers With Semantic CointensionDokumen17 halamanDesign of Fuzzy Rule-Based Classifiers With Semantic Cointensionjkl316Belum ada peringkat
- Genetic Algorithms Rule Discovery Data Mining: For inDokumen7 halamanGenetic Algorithms Rule Discovery Data Mining: For injkl316Belum ada peringkat
- Fuzzy Rule Base Ensemble Generated From Data by Linguistic Associations MiningDokumen22 halamanFuzzy Rule Base Ensemble Generated From Data by Linguistic Associations Miningjkl316Belum ada peringkat
- Global optimization model for ship designDokumen18 halamanGlobal optimization model for ship designlucas poloBelum ada peringkat
- CHEN64341 Energy Systems Coursework Andrew Stefanus 10149409Dokumen12 halamanCHEN64341 Energy Systems Coursework Andrew Stefanus 10149409AndRew SteFanus100% (1)
- Simulated AnnealingDokumen15 halamanSimulated AnnealingMohana MuraliBelum ada peringkat
- Path Optimization in 3D Printer: Algorithms and Experimentation SystemDokumen6 halamanPath Optimization in 3D Printer: Algorithms and Experimentation SystemfelipeBelum ada peringkat
- Scientific MATLABDokumen214 halamanScientific MATLABSheva Yatzar Fedayeen100% (1)
- Power Loss Minimization in Distribution Networks Using GADokumen108 halamanPower Loss Minimization in Distribution Networks Using GAAmos KormeBelum ada peringkat
- Design and Implementation of A Web-Based Timetable System For Higher Education InstitutionsDokumen13 halamanDesign and Implementation of A Web-Based Timetable System For Higher Education InstitutionsjeffBelum ada peringkat
- Mitigation and Control of Defeating Jammers Using P-1 FactorizationDokumen7 halamanMitigation and Control of Defeating Jammers Using P-1 FactorizationijcnesBelum ada peringkat
- Hill Climbing MethodsDokumen14 halamanHill Climbing Methodsapi-370591280% (5)
- Mobile Robot Navigation and Obstacle AvoidanceDokumen13 halamanMobile Robot Navigation and Obstacle AvoidanceSummer TriangleBelum ada peringkat
- CS 561: Artificial Intelligence: Local SearchDokumen51 halamanCS 561: Artificial Intelligence: Local Searchpeter hardyBelum ada peringkat
- 11-2001-Application of Tabu Search To Optimal Placement of Distributed GeneratorsDokumen6 halaman11-2001-Application of Tabu Search To Optimal Placement of Distributed GeneratorsAbbas DivianBelum ada peringkat
- AI Module II Lecture 2Dokumen15 halamanAI Module II Lecture 2jeevithaBelum ada peringkat
- CWI, Amsterdam, The Netherlands Department of Computer Science, Leiden University, The NetherlandsDokumen8 halamanCWI, Amsterdam, The Netherlands Department of Computer Science, Leiden University, The NetherlandsDsh Sa de CvBelum ada peringkat
- PD Slides03 PartitionDokumen88 halamanPD Slides03 PartitionSucharitha ReddyBelum ada peringkat
- Particle Swarm Optimization Based Reactive Power Dispatch For PowDokumen98 halamanParticle Swarm Optimization Based Reactive Power Dispatch For Powwjdan alzwi100% (1)
- SlidesDokumen46 halamanSlidesPulak Naskar100% (1)
- Efficient Formation of Storage Classes For Warehouse Storage LocationDokumen10 halamanEfficient Formation of Storage Classes For Warehouse Storage LocationhmtnslBelum ada peringkat
- Mel ZG641 Course HandoutDokumen12 halamanMel ZG641 Course HandoutJisitomarBelum ada peringkat
- Hill Climbing Algorithm in AIDokumen5 halamanHill Climbing Algorithm in AIAfaque AlamBelum ada peringkat
- CH332 L3 Emin PDFDokumen17 halamanCH332 L3 Emin PDFkdsarodeBelum ada peringkat
- Solving TSP Using Hopfield ModelDokumen12 halamanSolving TSP Using Hopfield ModelNAAMIBelum ada peringkat
- Shallow Neural NetworkDokumen152 halamanShallow Neural NetworkSreetam GangulyBelum ada peringkat
- Community Detection in Social Networks An OverviewDokumen6 halamanCommunity Detection in Social Networks An OverviewInternational Journal of Research in Engineering and TechnologyBelum ada peringkat
- Design and Implementation of A Web-Based Timetabling System-3Dokumen20 halamanDesign and Implementation of A Web-Based Timetabling System-3WELDON CHERUIYOTBelum ada peringkat
- Genetic Algorithms Optimize Thomson ProblemDokumen31 halamanGenetic Algorithms Optimize Thomson ProblemHabtamu AbrahamBelum ada peringkat
- Resource Optimization 5248363Dokumen5 halamanResource Optimization 5248363amit091379533Belum ada peringkat
- AI Assignment 2 Q and ADokumen7 halamanAI Assignment 2 Q and AChinmay JoshiBelum ada peringkat
- Thesis On Floorplanning VLSI by RameshDokumen91 halamanThesis On Floorplanning VLSI by RameshRaffi SkBelum ada peringkat
- Walid Coap 2004Dokumen18 halamanWalid Coap 2004MustafaMahdiBelum ada peringkat
- Generative AI: The Insights You Need from Harvard Business ReviewDari EverandGenerative AI: The Insights You Need from Harvard Business ReviewPenilaian: 4.5 dari 5 bintang4.5/5 (2)
- ChatGPT Side Hustles 2024 - Unlock the Digital Goldmine and Get AI Working for You Fast with More Than 85 Side Hustle Ideas to Boost Passive Income, Create New Cash Flow, and Get Ahead of the CurveDari EverandChatGPT Side Hustles 2024 - Unlock the Digital Goldmine and Get AI Working for You Fast with More Than 85 Side Hustle Ideas to Boost Passive Income, Create New Cash Flow, and Get Ahead of the CurveBelum ada peringkat
- Scary Smart: The Future of Artificial Intelligence and How You Can Save Our WorldDari EverandScary Smart: The Future of Artificial Intelligence and How You Can Save Our WorldPenilaian: 4.5 dari 5 bintang4.5/5 (54)
- Who's Afraid of AI?: Fear and Promise in the Age of Thinking MachinesDari EverandWho's Afraid of AI?: Fear and Promise in the Age of Thinking MachinesPenilaian: 4.5 dari 5 bintang4.5/5 (12)
- ChatGPT Money Machine 2024 - The Ultimate Chatbot Cheat Sheet to Go From Clueless Noob to Prompt Prodigy Fast! Complete AI Beginner’s Course to Catch the GPT Gold Rush Before It Leaves You BehindDari EverandChatGPT Money Machine 2024 - The Ultimate Chatbot Cheat Sheet to Go From Clueless Noob to Prompt Prodigy Fast! Complete AI Beginner’s Course to Catch the GPT Gold Rush Before It Leaves You BehindBelum ada peringkat
- AI Money Machine: Unlock the Secrets to Making Money Online with AIDari EverandAI Money Machine: Unlock the Secrets to Making Money Online with AIBelum ada peringkat
- Artificial Intelligence: A Guide for Thinking HumansDari EverandArtificial Intelligence: A Guide for Thinking HumansPenilaian: 4.5 dari 5 bintang4.5/5 (30)
- How to Make Money Online Using ChatGPT Prompts: Secrets Revealed for Unlocking Hidden Opportunities. Earn Full-Time Income Using ChatGPT with the Untold Potential of Conversational AI.Dari EverandHow to Make Money Online Using ChatGPT Prompts: Secrets Revealed for Unlocking Hidden Opportunities. Earn Full-Time Income Using ChatGPT with the Untold Potential of Conversational AI.Belum ada peringkat
- ChatGPT Millionaire 2024 - Bot-Driven Side Hustles, Prompt Engineering Shortcut Secrets, and Automated Income Streams that Print Money While You Sleep. The Ultimate Beginner’s Guide for AI BusinessDari EverandChatGPT Millionaire 2024 - Bot-Driven Side Hustles, Prompt Engineering Shortcut Secrets, and Automated Income Streams that Print Money While You Sleep. The Ultimate Beginner’s Guide for AI BusinessBelum ada peringkat
- The Master Algorithm: How the Quest for the Ultimate Learning Machine Will Remake Our WorldDari EverandThe Master Algorithm: How the Quest for the Ultimate Learning Machine Will Remake Our WorldPenilaian: 4.5 dari 5 bintang4.5/5 (107)
- Artificial Intelligence: The Insights You Need from Harvard Business ReviewDari EverandArtificial Intelligence: The Insights You Need from Harvard Business ReviewPenilaian: 4.5 dari 5 bintang4.5/5 (104)
- Power and Prediction: The Disruptive Economics of Artificial IntelligenceDari EverandPower and Prediction: The Disruptive Economics of Artificial IntelligencePenilaian: 4.5 dari 5 bintang4.5/5 (38)
- 2084: Artificial Intelligence and the Future of HumanityDari Everand2084: Artificial Intelligence and the Future of HumanityPenilaian: 4 dari 5 bintang4/5 (81)
- The Emperor's New Mind: Concerning Computers, Minds, and the Laws of PhysicsDari EverandThe Emperor's New Mind: Concerning Computers, Minds, and the Laws of PhysicsPenilaian: 3.5 dari 5 bintang3.5/5 (403)
- AI and Machine Learning for Coders: A Programmer's Guide to Artificial IntelligenceDari EverandAI and Machine Learning for Coders: A Programmer's Guide to Artificial IntelligencePenilaian: 4 dari 5 bintang4/5 (2)
- 100+ Amazing AI Image Prompts: Expertly Crafted Midjourney AI Art Generation ExamplesDari Everand100+ Amazing AI Image Prompts: Expertly Crafted Midjourney AI Art Generation ExamplesBelum ada peringkat
- Mastering Large Language Models: Advanced techniques, applications, cutting-edge methods, and top LLMs (English Edition)Dari EverandMastering Large Language Models: Advanced techniques, applications, cutting-edge methods, and top LLMs (English Edition)Belum ada peringkat
- ChatGPT: Is the future already here?Dari EverandChatGPT: Is the future already here?Penilaian: 4 dari 5 bintang4/5 (21)
- The Digital Mindset: What It Really Takes to Thrive in the Age of Data, Algorithms, and AIDari EverandThe Digital Mindset: What It Really Takes to Thrive in the Age of Data, Algorithms, and AIPenilaian: 3.5 dari 5 bintang3.5/5 (7)
- Killer ChatGPT Prompts: Harness the Power of AI for Success and ProfitDari EverandKiller ChatGPT Prompts: Harness the Power of AI for Success and ProfitPenilaian: 2 dari 5 bintang2/5 (1)
- ChatGPT for Business the Best Artificial Intelligence Applications, Marketing and Tools to Boost Your IncomeDari EverandChatGPT for Business the Best Artificial Intelligence Applications, Marketing and Tools to Boost Your IncomeBelum ada peringkat
- System Design Interview: 300 Questions And Answers: Prepare And PassDari EverandSystem Design Interview: 300 Questions And Answers: Prepare And PassBelum ada peringkat