Anda mungkin juga menyukai
- Análisis y diseño de algoritmos: Un enfoque prácticoDari EverandAnálisis y diseño de algoritmos: Un enfoque prácticoBelum ada peringkat
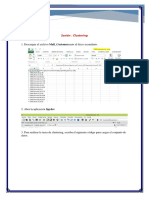
- ClusteringDokumen11 halamanClusteringDarwin Daniel Quispe SotoBelum ada peringkat
- Tratamiento y análisis de la información de mercados. COMM0110Dari EverandTratamiento y análisis de la información de mercados. COMM0110Belum ada peringkat
- Sesion 4Dokumen25 halamanSesion 4David LinaresBelum ada peringkat
- Diseño de elementos software con tecnologías basadas en componentes. IFCT0609Dari EverandDiseño de elementos software con tecnologías basadas en componentes. IFCT0609Belum ada peringkat
- Introducción a RapidMiner y estimación de precios de inmueblesDokumen7 halamanIntroducción a RapidMiner y estimación de precios de inmueblesAndy OrtizBelum ada peringkat
- Metodologias para La Gestion de Procesos de Mineria de DatosDokumen9 halamanMetodologias para La Gestion de Procesos de Mineria de Datoszap10863Belum ada peringkat
- Unidad 3. Actividades de AprendizajeDokumen10 halamanUnidad 3. Actividades de AprendizajeEsther2003Belum ada peringkat
- Cuál Es La Esencia Básica de La Realización de Un Modelo de SimulaciónDokumen4 halamanCuál Es La Esencia Básica de La Realización de Un Modelo de SimulaciónlupitaBelum ada peringkat
- Aplicacion Algoritmos WekaDokumen11 halamanAplicacion Algoritmos WekacristhianMarceloBelum ada peringkat
- Metodología Desarrollo de Programas en POO y MVCDokumen53 halamanMetodología Desarrollo de Programas en POO y MVCSocratesBelum ada peringkat
- Unidad I - Teoría de DecisiónDokumen37 halamanUnidad I - Teoría de Decisiónvege takas0% (1)
- Minería de datos Weka ejercicios análisis clasificación agrupación experimenterDokumen4 halamanMinería de datos Weka ejercicios análisis clasificación agrupación experimenterCrialex Meriches BiottBelum ada peringkat
- Manual Aimsun7 3 EJER ResultadosDokumen35 halamanManual Aimsun7 3 EJER ResultadosEdwin Ricardo MedinaBelum ada peringkat
- Módulo Xii Sib01 Act01Dokumen18 halamanMódulo Xii Sib01 Act01Anni MagtBelum ada peringkat
- Actividad1 - Investigación de OperacionesDokumen5 halamanActividad1 - Investigación de OperacionesJose ManuelBelum ada peringkat
- Felix - Reyes Laboratorio 2Dokumen10 halamanFelix - Reyes Laboratorio 2Felix Antonio Reyes CamposBelum ada peringkat
- Simulacion de Sistemas TEMARIODokumen12 halamanSimulacion de Sistemas TEMARIOAbeld TakamiBelum ada peringkat
- 03 Preparacion Analisis OODokumen20 halaman03 Preparacion Analisis OObenitezmigBelum ada peringkat
- Ejercicio WekaDokumen4 halamanEjercicio WekaRoiermax TrrtaBelum ada peringkat
- Instituto Tecnológico de Ensenada: SimulaciónDokumen8 halamanInstituto Tecnológico de Ensenada: SimulaciónChristian RosalesBelum ada peringkat
- Taller UnoDokumen15 halamanTaller Unojohn hernandezBelum ada peringkat
- Barrios Marín Antonio José TFGDokumen61 halamanBarrios Marín Antonio José TFGalexBelum ada peringkat
- Implementacion de Machine Learning para Recetar Medicamentos Basado en SintomasDokumen11 halamanImplementacion de Machine Learning para Recetar Medicamentos Basado en Sintomaskillermariin99Belum ada peringkat
- Investigacion MLDokumen9 halamanInvestigacion MLJulia MariaBelum ada peringkat
- Instroduccion Al ProModelDokumen54 halamanInstroduccion Al ProModelVictor Andrade SotoBelum ada peringkat
- SQLDokumen209 halamanSQLGeraldineBelum ada peringkat
- Estructura de Datos I (Ingenieria)Dokumen283 halamanEstructura de Datos I (Ingenieria)Andrea IturbideBelum ada peringkat
- Algoritmos de Ordenación y PDFDokumen27 halamanAlgoritmos de Ordenación y PDFJesus D.HBelum ada peringkat
- Tema 2Dokumen57 halamanTema 2Patricia CamposBelum ada peringkat
- Taller 3 - Grupo - 212026 - 39Dokumen15 halamanTaller 3 - Grupo - 212026 - 39Monica Suarez GutierrezBelum ada peringkat
- Machine LearningDokumen12 halamanMachine LearningIttzel MachadoBelum ada peringkat
- Caso PracticoDokumen5 halamanCaso Practicosechacienda sechaciendaBelum ada peringkat
- Aprendizaje Supervisado y No SupervisadoDokumen4 halamanAprendizaje Supervisado y No SupervisadoDARWIN RODOLFO DAVILA FERNANDEZ100% (1)
- Nine - Steps - En.es (ESPAÑOL)Dokumen6 halamanNine - Steps - En.es (ESPAÑOL)Damaris Ortiz FloresBelum ada peringkat
- Cómo Se Elabora El ClusteringDokumen3 halamanCómo Se Elabora El ClusteringrojasperezjoaquinliBelum ada peringkat
- Clase 2Dokumen26 halamanClase 2oscar ffireBelum ada peringkat
- Lab 01 EDA 2020Dokumen5 halamanLab 01 EDA 2020Deyson Victor Diaz TiconaBelum ada peringkat
- U2 JavaDokumen50 halamanU2 JavaVICTOR MOROBelum ada peringkat
- Proyecto de Io2Dokumen19 halamanProyecto de Io2richard vera vargasBelum ada peringkat
- Actividad 5 POODokumen14 halamanActividad 5 POOJorge Antonio Gamas LópezBelum ada peringkat
- Cuestionario Unidad 2Dokumen7 halamanCuestionario Unidad 2Gustavo Fuentes CordovaBelum ada peringkat
- Paso4 Grupo31Dokumen17 halamanPaso4 Grupo31Caren MendietaBelum ada peringkat
- Gestión Del Conocimiento - Parte 2Dokumen171 halamanGestión Del Conocimiento - Parte 2Jesus Huarcayjjfkdlxo&ja kdiewskfjfjaBelum ada peringkat
- Aprendizaje AutomaticoDokumen15 halamanAprendizaje Automaticowilliam david calsin bordaBelum ada peringkat
- KDD: Descubrimiento de conocimiento en bases de datosDokumen6 halamanKDD: Descubrimiento de conocimiento en bases de datosMagno TaipeBelum ada peringkat
- Ensayo Modelos de Investigacion de OperacionesDokumen3 halamanEnsayo Modelos de Investigacion de OperacionesJosué GarcésBelum ada peringkat
- Mineria de DatosDokumen9 halamanMineria de DatosedwinBelum ada peringkat
- Programacion Por MetasDokumen13 halamanProgramacion Por Metasgris martinez50% (2)
- AA3 Estructuras de ControlDokumen55 halamanAA3 Estructuras de ControlChristian BautistaBelum ada peringkat
- Tema 7 Clustering Agrupamiento ClasificacionDokumen38 halamanTema 7 Clustering Agrupamiento Clasificacionuriel291092Belum ada peringkat
- Pretarea - Grupo - 212026 - 57-VANESSA SIERRADokumen12 halamanPretarea - Grupo - 212026 - 57-VANESSA SIERRAvanessa sierra sanchezBelum ada peringkat
- Simulación: M.C Juan Francisco Rocha AguilarDokumen24 halamanSimulación: M.C Juan Francisco Rocha AguilarLuzmaria CaciqueBelum ada peringkat
- 1 y 2. MetodologiaDokumen7 halaman1 y 2. MetodologiaAgatha del OlmoBelum ada peringkat
- Tarea Inv Operativa 3Dokumen9 halamanTarea Inv Operativa 3Lizeth Cabrera ChirinosBelum ada peringkat
- Conceptos Fundamentales MLDokumen3 halamanConceptos Fundamentales MLSantiago Runcería OrtizBelum ada peringkat
- Paso 3 Trabajo Colaborativo Grupo 212026 2Dokumen35 halamanPaso 3 Trabajo Colaborativo Grupo 212026 2Cesar Garcia100% (2)
- Paso 1 - Reconocimiento de Pre Saberes Modelos de SimulaciónDokumen13 halamanPaso 1 - Reconocimiento de Pre Saberes Modelos de SimulaciónGonna MoveBelum ada peringkat
- Investigación - Proceso de Minería de Datos - Alfredo Avendaño SerranoDokumen17 halamanInvestigación - Proceso de Minería de Datos - Alfredo Avendaño SerranoAlfredo Avendaño SerranoBelum ada peringkat
- Detección de SPAM Mediante Redes BayesianasDokumen52 halamanDetección de SPAM Mediante Redes BayesianasEstebanBelum ada peringkat
- Cuestionario PrevioDokumen4 halamanCuestionario PrevioSonny PimentelBelum ada peringkat
- Practica5 (GC)Dokumen1 halamanPractica5 (GC)Marco Antonio Mendoza RodriguezBelum ada peringkat
- Programación CDokumen57 halamanProgramación Cgraduadoesime50% (2)
- Influencia de Los Videojuegos en Estudiantes de Educación Primaria PDFDokumen4 halamanInfluencia de Los Videojuegos en Estudiantes de Educación Primaria PDFSonny PimentelBelum ada peringkat
- Influencia de Los Videojuegos en Estudiantes de Educación Primaria PDFDokumen4 halamanInfluencia de Los Videojuegos en Estudiantes de Educación Primaria PDFSonny PimentelBelum ada peringkat
- Constitución Política DelPerú 1993 Art.58-77Dokumen4 halamanConstitución Política DelPerú 1993 Art.58-77GiovanaBelum ada peringkat
- BiseccionDokumen1 halamanBiseccionSonny PimentelBelum ada peringkat
- Inteligencia Artificial Inteligencia Computacional y Big Data PRESENTACION 1Dokumen20 halamanInteligencia Artificial Inteligencia Computacional y Big Data PRESENTACION 1Sonny PimentelBelum ada peringkat
- Guía JSP - JDBCDokumen35 halamanGuía JSP - JDBCFranco Alarcon RojasBelum ada peringkat
- Curso Spring - PresentacionDokumen3 halamanCurso Spring - PresentacionDany Cenas VásquezBelum ada peringkat
- 1-Programas Fortran - Arreglos UnidimensionalesDokumen6 halaman1-Programas Fortran - Arreglos UnidimensionalesJavier CaballeroBelum ada peringkat
- Codigo FinalDokumen13 halamanCodigo Finalbrenna18Belum ada peringkat
- Curso Práctico de Javascript: JuandcDokumen5 halamanCurso Práctico de Javascript: JuandcSumitsu HokoyamaBelum ada peringkat
- Lenguajes de ProgramacionDokumen20 halamanLenguajes de ProgramacionFernando Javier Farrachol GuerraBelum ada peringkat
- Introducción A Android Studio PDFDokumen15 halamanIntroducción A Android Studio PDFJader BerrioBelum ada peringkat
- Actividad 1 GlosarioDokumen3 halamanActividad 1 GlosarioJesus RoseroBelum ada peringkat
- DcomDokumen4 halamanDcomHaydee HilasacaBelum ada peringkat
- Guia de Modulo de Diseno de Software 2019Dokumen13 halamanGuia de Modulo de Diseno de Software 2019leidy tatiana sanchezBelum ada peringkat
- PLSQLDokumen2 halamanPLSQLAinalahmBelum ada peringkat
- Python POODokumen44 halamanPython POOjose felipe yhuaraqui remuzgoBelum ada peringkat
- Proyecto FORTRANDokumen4 halamanProyecto FORTRANPedro José Ballesteros CerpaBelum ada peringkat
- PLP 6Dokumen4 halamanPLP 6Willian WallasBelum ada peringkat
- Manual Informatica UAIDokumen67 halamanManual Informatica UAIEzequiel CarnovaleBelum ada peringkat
- Lenguaje EnsambladorDokumen3 halamanLenguaje Ensambladorkaren quiahuaBelum ada peringkat
- Qué es un algoritmoDokumen1 halamanQué es un algoritmojayko mejiaBelum ada peringkat
- Java 3DDokumen9 halamanJava 3DJunior Abad SanturBelum ada peringkat
- Informe de Labores y Horarios Luis Balcázar - 2023.06.25Dokumen6 halamanInforme de Labores y Horarios Luis Balcázar - 2023.06.25Diana PugllaBelum ada peringkat
- Modalidad de Exámenes - Semana 6 - Revisión Del IntentoDokumen4 halamanModalidad de Exámenes - Semana 6 - Revisión Del IntentoAlfonso ToledoBelum ada peringkat
- Silabo Informatica EmpresarialDokumen7 halamanSilabo Informatica EmpresarialClaudia Dayanng Tasayco VegaBelum ada peringkat
- PROMEDIO CALIFICACIONESDokumen4 halamanPROMEDIO CALIFICACIONESOscar Paul OrozcoBelum ada peringkat
- Montículo BinarioDokumen5 halamanMontículo BinarioBjbrianBelum ada peringkat
- Practica 3Dokumen4 halamanPractica 3Oscar RHBelum ada peringkat
- 1 Aplicar Herramientas OfimáticasDokumen4 halaman1 Aplicar Herramientas Ofimáticasmirtme0% (1)
- Robot-RescatistaReporte 8CDokumen2 halamanRobot-RescatistaReporte 8CGonzalo FernandezBelum ada peringkat
- Coria Rodrigo PracticaOrganizacionyArquitecturaDokumen9 halamanCoria Rodrigo PracticaOrganizacionyArquitecturaRodrigo CoriaBelum ada peringkat
- Norma Asarco IntroduccionDokumen4 halamanNorma Asarco IntroduccionRaul Carrasco GBelum ada peringkat
- EDA - 03 Listas EnlazadasDokumen14 halamanEDA - 03 Listas Enlazadasdaniel ylliscaBelum ada peringkat
- Manual Awk CastellanoDokumen118 halamanManual Awk Castellanodcastrelos2000Belum ada peringkat