Anda mungkin juga menyukai
- Model-Based Adaptive Critic Designs: Editor's SummaryDokumen31 halamanModel-Based Adaptive Critic Designs: Editor's SummaryioncopaeBelum ada peringkat
- Model Predictive Control of An Inverted Pendulum, MPCDokumen4 halamanModel Predictive Control of An Inverted Pendulum, MPCerdsan100% (1)
- Computers and Mathematics With Applications: Ramiro S. Barbosa, J.A. Tenreiro Machado, Isabel S. JesusDokumen8 halamanComputers and Mathematics With Applications: Ramiro S. Barbosa, J.A. Tenreiro Machado, Isabel S. Jesusdebasishmee5808Belum ada peringkat
- A Sliding Mode-Multimodel Control For A Sensorless Pumping SystemDokumen6 halamanA Sliding Mode-Multimodel Control For A Sensorless Pumping SystemKatherine DukeBelum ada peringkat
- Speed Control Design of A PMSM Based On Functional Model Predictive ApproachDokumen15 halamanSpeed Control Design of A PMSM Based On Functional Model Predictive Approachhieuhuech1Belum ada peringkat
- Exp 7Dokumen3 halamanExp 7hashmalshrfy030Belum ada peringkat
- Robust Linear ParameterDokumen6 halamanRobust Linear ParametervinaycltBelum ada peringkat
- Gain-Scheduling - CSTR Klatt & Engell - 1998Dokumen12 halamanGain-Scheduling - CSTR Klatt & Engell - 1998VitorDiegoBelum ada peringkat
- Optimal Observers: Kalman FiltersDokumen2 halamanOptimal Observers: Kalman FiltersHoussem GrachaBelum ada peringkat
- AAPA 2019asadiDokumen9 halamanAAPA 2019asadizhizhang5591Belum ada peringkat
- Classical Control 2 Sche A MeDokumen6 halamanClassical Control 2 Sche A MeEric Leo AsiamahBelum ada peringkat
- Control System Simulation Lab 6: Completed By: Name: Rohan Ramesh Rangate MIS No: 121936012Dokumen5 halamanControl System Simulation Lab 6: Completed By: Name: Rohan Ramesh Rangate MIS No: 121936012rohan rangateBelum ada peringkat
- LCS Basics Revesion PDFDokumen3 halamanLCS Basics Revesion PDFrajeshmholmukheBelum ada peringkat
- University of Khartoum Faculty of Engineering Chemical Engineering DepartmentDokumen27 halamanUniversity of Khartoum Faculty of Engineering Chemical Engineering DepartmentmurtadaBelum ada peringkat
- Design of Indirect MRAS-based Adaptive Control SystemsDokumen5 halamanDesign of Indirect MRAS-based Adaptive Control SystemsThiện DũngBelum ada peringkat
- ISA Transactions: Yongkun Wang, Mingwei Sun, Zenghui Wang, Zhongxin Liu, Zengqiang ChenDokumen8 halamanISA Transactions: Yongkun Wang, Mingwei Sun, Zenghui Wang, Zhongxin Liu, Zengqiang ChenNadeshiko KinomotoBelum ada peringkat
- Synergetic ControlDokumen13 halamanSynergetic Controlrostamkola1229Belum ada peringkat
- Tutorial Xinda-Hu ImpDokumen8 halamanTutorial Xinda-Hu ImpMuhammad SiddiqueBelum ada peringkat
- 10ijss DraftDokumen25 halaman10ijss DraftSuresh PatilBelum ada peringkat
- Discrete-Time Sliding Mode Control of Permanent Magnet Linear Synchronous Motor in High-Performance Motion With Large Parameter UncertaintyDokumen4 halamanDiscrete-Time Sliding Mode Control of Permanent Magnet Linear Synchronous Motor in High-Performance Motion With Large Parameter UncertaintyElzan AgungBelum ada peringkat
- Controls Infosheet and Sample Problems 0Dokumen11 halamanControls Infosheet and Sample Problems 0Md Nur-A-Adam DonyBelum ada peringkat
- Icee2015 Paper Id3911Dokumen4 halamanIcee2015 Paper Id3911Zellagui EnergyBelum ada peringkat
- MPC Tuning For Systems With Right Half Plane ZerosDokumen6 halamanMPC Tuning For Systems With Right Half Plane ZerosAhmed Chahine ZorganeBelum ada peringkat
- Designing Controller by State Space Techniques Using Reduced Order Model AlgorithmDokumen5 halamanDesigning Controller by State Space Techniques Using Reduced Order Model AlgorithmGladiolus TranBelum ada peringkat
- Control System Design by Frequency Response Using Matlab: Riyadh Nazar Ali AL-Gburi, Ali Saleh AzizDokumen7 halamanControl System Design by Frequency Response Using Matlab: Riyadh Nazar Ali AL-Gburi, Ali Saleh AzizAmanBelum ada peringkat
- Automatic Control Term Project FinalDokumen23 halamanAutomatic Control Term Project Finalnopphawin.44Belum ada peringkat
- Ambo University: Regulation and ControlDokumen20 halamanAmbo University: Regulation and ControlFikadu EshetuBelum ada peringkat
- Control System ModelingDokumen24 halamanControl System ModelingSiva Bala KrishnanBelum ada peringkat
- ControlDokumen34 halamanControlmurtadaBelum ada peringkat
- Control Systems Typed NotesDokumen129 halamanControl Systems Typed Notesta003744Belum ada peringkat
- Speed Control of DC Motor Using Sliding Mode Control ApproachDokumen5 halamanSpeed Control of DC Motor Using Sliding Mode Control ApproachIOSRjournalBelum ada peringkat
- Minor Project Write UpDokumen7 halamanMinor Project Write UpAviral UpadhyayBelum ada peringkat
- An Adaptive Controller Using Output Feedback For Improving Dynamic Stability of Synchronous Power SystemDokumen7 halamanAn Adaptive Controller Using Output Feedback For Improving Dynamic Stability of Synchronous Power Systemনূর হোসেন সৌরভBelum ada peringkat
- Research ArticleDokumen8 halamanResearch Articletariq76Belum ada peringkat
- Controller (Notes)Dokumen22 halamanController (Notes)Alex OsesBelum ada peringkat
- Chapter1 - Introduction To Automatic ControlDokumen37 halamanChapter1 - Introduction To Automatic ControlAhmed awwadBelum ada peringkat
- 1 - Introduction To Control SystemsDokumen11 halaman1 - Introduction To Control SystemsKenzie WalipiBelum ada peringkat
- An Introduction To Nonlinear Model Predictive ControlDokumen23 halamanAn Introduction To Nonlinear Model Predictive ControlSohibul HajahBelum ada peringkat
- Desain Sistem Kendali Umpan Balik State Pada Kasus Kontinyu Untuk Meja Kerja CNCDokumen9 halamanDesain Sistem Kendali Umpan Balik State Pada Kasus Kontinyu Untuk Meja Kerja CNCArgatha AlwinsyahBelum ada peringkat
- Sliding Mode Control of PMSM Based On A Novel Disturbance ObserverDokumen5 halamanSliding Mode Control of PMSM Based On A Novel Disturbance ObserverNguyễn Văn HoàBelum ada peringkat
- Amc 15410Dokumen14 halamanAmc 15410Ronny A. ChavezBelum ada peringkat
- PID Theory ExplainedDokumen9 halamanPID Theory ExplainedMansen NsubugaBelum ada peringkat
- Control Lab Project ReportDokumen28 halamanControl Lab Project ReportDanyal QamarBelum ada peringkat
- Control Systems PDFDokumen132 halamanControl Systems PDFsumit soniBelum ada peringkat
- PHD ACODokumen13 halamanPHD ACOPrasadYadavBelum ada peringkat
- InTech-A New Kind of Nonlinear Model Predictive Control Algorithm Enhanced by Control Lyapunov FunctionsDokumen28 halamanInTech-A New Kind of Nonlinear Model Predictive Control Algorithm Enhanced by Control Lyapunov FunctionsArviandy AribowoBelum ada peringkat
- Session 50 Theory of Explicit Dynamic AnalysisDokumen12 halamanSession 50 Theory of Explicit Dynamic AnalysisPraveen MalikBelum ada peringkat
- Development Algorithms For Servo Systems: FuzzyDokumen8 halamanDevelopment Algorithms For Servo Systems: FuzzyMohit ChoradiaBelum ada peringkat
- Decentralized Control of Active Vehicle Suspensions With PreviewDokumen6 halamanDecentralized Control of Active Vehicle Suspensions With PreviewGibs RiveraBelum ada peringkat
- Evaluation of Block-Oriented Models Use For The Purpose of Robust Controllers SynthesisDokumen9 halamanEvaluation of Block-Oriented Models Use For The Purpose of Robust Controllers SynthesisJhonathanCamposResendeBelum ada peringkat
- PIDControllerDokumen42 halamanPIDControllerstephenBelum ada peringkat
- Non-Linear Speed Control of PMSM - Mar13Dokumen8 halamanNon-Linear Speed Control of PMSM - Mar13bala krishnanBelum ada peringkat
- Report 2 (PID)Dokumen5 halamanReport 2 (PID)Araragi KoyomiBelum ada peringkat
- Unit IDokumen7 halamanUnit IanandhBelum ada peringkat
- Sliding Computed Torque Control Based On Passivity For A Haptic Device: Phantom Premium 1.0Dokumen7 halamanSliding Computed Torque Control Based On Passivity For A Haptic Device: Phantom Premium 1.0Eduardo Martínez CameroBelum ada peringkat
- Model Predictive Control in LabVIEWDokumen22 halamanModel Predictive Control in LabVIEWBrankko Jhonathan Torres SaavedraBelum ada peringkat
- Control of DC Motor Using Different Control StrategiesDari EverandControl of DC Motor Using Different Control StrategiesBelum ada peringkat
- Nonlinear Control Feedback Linearization Sliding Mode ControlDari EverandNonlinear Control Feedback Linearization Sliding Mode ControlBelum ada peringkat
- Computational Methods for Process SimulationDari EverandComputational Methods for Process SimulationPenilaian: 3 dari 5 bintang3/5 (1)
- 8th Semester Path Lab 6Dokumen11 halaman8th Semester Path Lab 6سيد احسن رضاBelum ada peringkat
- 8th Semester Path PATH LABDokumen5 halaman8th Semester Path PATH LABسيد احسن رضاBelum ada peringkat
- Path Planning LAB: Dynamic ProgrammingDokumen7 halamanPath Planning LAB: Dynamic Programmingسيد احسن رضاBelum ada peringkat
- Gpa Sem 6Dokumen6 halamanGpa Sem 6سيد احسن رضاBelum ada peringkat
- Dynamics of Linear SystemDokumen246 halamanDynamics of Linear SystemAbhishek SardarBelum ada peringkat
- WinAC Target DOKU V12 enDokumen91 halamanWinAC Target DOKU V12 enMarko JurisevicBelum ada peringkat
- ITU R BS.1770 1 FiltersDokumen5 halamanITU R BS.1770 1 FiltersVicente LeunamBelum ada peringkat
- Vacuum Oven: DZF ModelDokumen15 halamanVacuum Oven: DZF ModelFernanda ContursiBelum ada peringkat
- A Vector Control System of PMSM With The Assistance of Fuzzy PID ControllerDokumen6 halamanA Vector Control System of PMSM With The Assistance of Fuzzy PID ControllerFelix Adrian Trujillo PerdomoBelum ada peringkat
- Computer Science 2006 Sem V& VIDokumen17 halamanComputer Science 2006 Sem V& VIJinu MadhavanBelum ada peringkat
- Maglev ConveyorDokumen7 halamanMaglev ConveyorLalbahadur MajhiBelum ada peringkat
- 2013 - 14 HydraulicsDokumen122 halaman2013 - 14 HydraulicspradeepalokrajBelum ada peringkat
- Minor Project Report On Load Frequency Control of Interconnected Power Systems Using Pso AlgorithmDokumen31 halamanMinor Project Report On Load Frequency Control of Interconnected Power Systems Using Pso Algorithmyash jeet singhBelum ada peringkat
- ECE320 StudyGuideDokumen262 halamanECE320 StudyGuideTumenbayar LkhagvatserenBelum ada peringkat
- Fundamentals of Process Control Theory ThirdEd - Murrill - Unit2Dokumen10 halamanFundamentals of Process Control Theory ThirdEd - Murrill - Unit2Ganesh GanyBelum ada peringkat
- Introduction From Fault Detection To Fault ToleranceDokumen8 halamanIntroduction From Fault Detection To Fault ToleranceJavier LamedaBelum ada peringkat
- Signal Flow GraphDokumen38 halamanSignal Flow Graphgaurav_juneja_4Belum ada peringkat
- SyllabusDokumen2 halamanSyllabusGourab DebnathBelum ada peringkat
- Accurate Modeling and Robust Hovering Control For A Quad-Rotor VTOL AircraftDokumen19 halamanAccurate Modeling and Robust Hovering Control For A Quad-Rotor VTOL AircraftIkeaMonsterBelum ada peringkat
- 1 20302 D A PPT 00 Introduction To Instrumentation Process Control 38s (Lecture Seule)Dokumen19 halaman1 20302 D A PPT 00 Introduction To Instrumentation Process Control 38s (Lecture Seule)Morgan SidesoBelum ada peringkat
- Fees Details WP - Technocrat AutomationDokumen16 halamanFees Details WP - Technocrat AutomationsushantadharBelum ada peringkat
- ABB Lift Control ACSM 1 PDFDokumen280 halamanABB Lift Control ACSM 1 PDFSolrac ToneBelum ada peringkat
- Modern Control Theory PDFDokumen113 halamanModern Control Theory PDFBelayneh Tadesse75% (4)
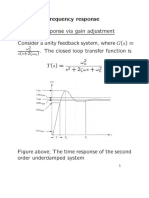
- Design via frequency response Transient response via gain adjustment Consider a unity feedback system, where G(s) = - The closed loop transfer function is T (s) = ω s + 2ζωs + ωDokumen12 halamanDesign via frequency response Transient response via gain adjustment Consider a unity feedback system, where G(s) = - The closed loop transfer function is T (s) = ω s + 2ζωs + ωmdthBelum ada peringkat
- Unit 1, 2 Control - Systems - NotesDokumen97 halamanUnit 1, 2 Control - Systems - NoteskingsukumarBelum ada peringkat
- Trajectory Tracking of A 2-DOF Helicopter System Using Fuzzy Controller ApproachDokumen6 halamanTrajectory Tracking of A 2-DOF Helicopter System Using Fuzzy Controller Approachhai zhangBelum ada peringkat
- Perancangan Simulasi PID Controller Mengunakan Graphic User Interface Dan SimulinkDokumen11 halamanPerancangan Simulasi PID Controller Mengunakan Graphic User Interface Dan SimulinkercompBelum ada peringkat
- ATM200 ActuatorsDokumen8 halamanATM200 ActuatorsAffandy12twelveBelum ada peringkat
- Control Engineering - Project TopicsDokumen11 halamanControl Engineering - Project TopicsDavid AbbreyBelum ada peringkat
- Implementation of A Discrete Fuzzy PID Excitation Con 2012 Ain Shams EngineeDokumen9 halamanImplementation of A Discrete Fuzzy PID Excitation Con 2012 Ain Shams EngineeRajneesh KatochBelum ada peringkat
- Voltage Controller of DC-DC Buck Boost Converter With Proposed PID ControllerDokumen5 halamanVoltage Controller of DC-DC Buck Boost Converter With Proposed PID ControllerAbdul HafeezBelum ada peringkat
- How High Can You Go?: New Approaches For Cooling System EfficiencyDokumen4 halamanHow High Can You Go?: New Approaches For Cooling System EfficiencyagnieasBelum ada peringkat
- Pole-Placement Designs of Power System StabilizersDokumen7 halamanPole-Placement Designs of Power System StabilizersabelcatayBelum ada peringkat
- PHD Call For ApplicationDokumen41 halamanPHD Call For ApplicationAptu Andy KurniawanBelum ada peringkat