Anda mungkin juga menyukai
- Módulo de Aprendizaje 6Dokumen7 halamanMódulo de Aprendizaje 6javier castilloBelum ada peringkat
- 02 FG Gráficas Pag 13a16 2017Dokumen6 halaman02 FG Gráficas Pag 13a16 2017Emanuel RodasBelum ada peringkat
- Actividad 7, Fundamentos de MatematicasDokumen10 halamanActividad 7, Fundamentos de MatematicasNïnä Tôvär PâëzBelum ada peringkat
- Estadistica 2 Er ParcialDokumen19 halamanEstadistica 2 Er ParcialFernando ChandiaBelum ada peringkat
- Taller 3Dokumen10 halamanTaller 3Nicolas ClavijoBelum ada peringkat
- Método GráficoDokumen18 halamanMétodo Gráficocitlali garciaBelum ada peringkat
- Regresiones Lineales CovariazaDokumen6 halamanRegresiones Lineales CovariazaFundacion Sire25% (4)
- U6-7-T2 - Alvarez Castillo VicenteDokumen11 halamanU6-7-T2 - Alvarez Castillo VicenteZero TwoBelum ada peringkat
- Metodo Simplex DualDokumen8 halamanMetodo Simplex DualHelbert Giovanni Rodriguez GalloBelum ada peringkat
- Actividad #7Dokumen8 halamanActividad #7Sebastián EnríquezBelum ada peringkat
- Ejercicios de Aplicación de Medidas de Tendencia CentralDokumen4 halamanEjercicios de Aplicación de Medidas de Tendencia CentralLorena LitumaBelum ada peringkat
- Taller Regresion Lineal Simple y Multiple-1Dokumen26 halamanTaller Regresion Lineal Simple y Multiple-1Jeisson RozoBelum ada peringkat
- Actividad de Aprendizaje 1 Taller 1Dokumen12 halamanActividad de Aprendizaje 1 Taller 1Ange PatoBelum ada peringkat
- U6-7-T2 - Alvarez Castillo Vicente PDFDokumen11 halamanU6-7-T2 - Alvarez Castillo Vicente PDFZero TwoBelum ada peringkat
- Gráficas, Experiencia N°2Dokumen5 halamanGráficas, Experiencia N°2Keller Modesto CalixtoBelum ada peringkat
- Tema 7. Regresión Lineal y CorrelaciónDokumen9 halamanTema 7. Regresión Lineal y CorrelaciónSebastián EnríquezBelum ada peringkat
- ModaDokumen21 halamanModaLuis MarroquínBelum ada peringkat
- Ejercicios ANOVA en Clases 6Dokumen23 halamanEjercicios ANOVA en Clases 6Diana SarangoBelum ada peringkat
- Ejercicio HistogramasDokumen2 halamanEjercicio HistogramasDEYSI MEDINAojijuBelum ada peringkat
- Clase 4 Tablas de Doble EntradaDokumen11 halamanClase 4 Tablas de Doble Entradaapi-36995570% (1)
- Problemas Propuestos Capitulo III EstadísticaDokumen12 halamanProblemas Propuestos Capitulo III EstadísticaSergio GalánBelum ada peringkat
- Unidad 3 Correlación y RegresiónDokumen14 halamanUnidad 3 Correlación y Regresiónsierra nevadaBelum ada peringkat
- Intersecciones, Análisis Dimensional, VectoresDokumen4 halamanIntersecciones, Análisis Dimensional, VectoresPaydosBelum ada peringkat
- Joinner Acosta, TallerDokumen8 halamanJoinner Acosta, TallerJoinner Acosta100% (1)
- Laboratorio de Estadística 4Dokumen37 halamanLaboratorio de Estadística 4Christine Golder100% (1)
- Trabajo de EstadisticaDokumen29 halamanTrabajo de EstadisticaLisbeth Peña SoelBelum ada peringkat
- InterseccionesDokumen4 halamanInterseccionesPaydosBelum ada peringkat
- TTDokumen6 halamanTTJAHFBelum ada peringkat
- 20feb Regresi Dengan MatriksDokumen5 halaman20feb Regresi Dengan MatriksArsidna Dinda LutfianaBelum ada peringkat
- Examen de Primera Unidad PDFDokumen5 halamanExamen de Primera Unidad PDFJOSEPH JORGE BENIQUE RODRIGUEZBelum ada peringkat
- La Siguiente Tabla Muestra La Relación Que Existe Entre Los Gastos en Publicidad (Millones) y Las Ventas Anuales (Millones)Dokumen5 halamanLa Siguiente Tabla Muestra La Relación Que Existe Entre Los Gastos en Publicidad (Millones) y Las Ventas Anuales (Millones)Frank PerezBelum ada peringkat
- TCC InvestigacionDokumen6 halamanTCC Investigacionraily ramos100% (1)
- Final de LaboratorioDokumen15 halamanFinal de LaboratorioElias ContrerasBelum ada peringkat
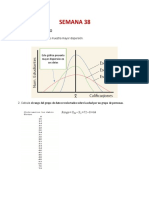
- Semana 38Dokumen4 halamanSemana 38David Patricio100% (1)
- Rosali Bro 1Dokumen6 halamanRosali Bro 1FABIANA DIANA SOLANO ACLARIBelum ada peringkat
- Libro 1Dokumen5 halamanLibro 1hinara yetBelum ada peringkat
- Examen de EstadisticasDokumen8 halamanExamen de EstadisticasCristian Guillermo Gutierrez ChoezBelum ada peringkat
- VIDEO - Momentos, Sesgos, Curtosis, Jhofre Sanaguaray PDFDokumen6 halamanVIDEO - Momentos, Sesgos, Curtosis, Jhofre Sanaguaray PDFMelanie Cayambe . DBelum ada peringkat
- Ejemplo Indice de GiniDokumen10 halamanEjemplo Indice de GiniIvette Jurado LozanoBelum ada peringkat
- VIDEO - Momentos, Sesgos, Curtosis, Jhofre SanaguarayDokumen6 halamanVIDEO - Momentos, Sesgos, Curtosis, Jhofre SanaguarayMelanie Cayambe . DBelum ada peringkat
- Acfrogb8zijtgxz Li Lrvagthbfq7kzq5qcgsjbnnc46g0dwonwd7cnduzv0aeruxu1tvxl1ukn Cex763jrndgxprgyabmj0tsedmd806f3fvvkbnkoyynh 7vpp4Dokumen7 halamanAcfrogb8zijtgxz Li Lrvagthbfq7kzq5qcgsjbnnc46g0dwonwd7cnduzv0aeruxu1tvxl1ukn Cex763jrndgxprgyabmj0tsedmd806f3fvvkbnkoyynh 7vpp4Victor Arath Alban FreireBelum ada peringkat
- Relación Entre VariablesDokumen5 halamanRelación Entre VariablesMafer GironBelum ada peringkat
- A) Las Fronteras de Clase: Gráfica de La OjivaDokumen2 halamanA) Las Fronteras de Clase: Gráfica de La OjivaJavierBelum ada peringkat
- TALLER - 1 CIPAS (Autoguardado) JFDokumen33 halamanTALLER - 1 CIPAS (Autoguardado) JFCARLOSBelum ada peringkat
- Estadígrafos de Dispersion Ccss 2022-IDokumen35 halamanEstadígrafos de Dispersion Ccss 2022-IALDAIR TARAZONA SOLORZANOBelum ada peringkat
- Medidas de AsociacionDokumen4 halamanMedidas de Asociacioncementerioveneno5Belum ada peringkat
- Plantilla Excel Ejemplo Semana 3 2023 PracticoDokumen13 halamanPlantilla Excel Ejemplo Semana 3 2023 Practico75875739Belum ada peringkat
- Sesion #13Dokumen34 halamanSesion #13Atenas Pamela Flores SalvatierraBelum ada peringkat
- Regresión Lineal y CorrelaciónDokumen13 halamanRegresión Lineal y CorrelaciónMichelle ChiguanoBelum ada peringkat
- Taller Covariamza - Correlacion - RegresionDokumen11 halamanTaller Covariamza - Correlacion - RegresionDavid AguiñoBelum ada peringkat
- X-Y - 0 - 2 - 2 - 9 1 4 2 7 - 1 0 4 17 Desvmx 1.58113883 Desvm Y 6.12372436 Muestra 5 N-1 4Dokumen8 halamanX-Y - 0 - 2 - 2 - 9 1 4 2 7 - 1 0 4 17 Desvmx 1.58113883 Desvm Y 6.12372436 Muestra 5 N-1 4José palaciosBelum ada peringkat
- Coeficiente de Correlacion - Adca...Dokumen5 halamanCoeficiente de Correlacion - Adca...Carlos AlcivarBelum ada peringkat
- Tema 3. Tratamiento Descriptivo Bidimensional (A.pastor)Dokumen21 halamanTema 3. Tratamiento Descriptivo Bidimensional (A.pastor)polturu2005Belum ada peringkat
- Trabajo Colo 2 EstadisticaDokumen10 halamanTrabajo Colo 2 EstadisticaNOTIFICACIONES SADBelum ada peringkat
- RyC EjerciciosDokumen14 halamanRyC EjercicioshernanBelum ada peringkat
- Jhon Parra - Lab - Regresion y CorrelacionDokumen7 halamanJhon Parra - Lab - Regresion y CorrelacionJHON ALEXANDER PARRA JIMENEZBelum ada peringkat
- FRECUENCIASDokumen3 halamanFRECUENCIASFabian Ricardo Higuera RodriguezBelum ada peringkat
- Trabajo Estadistica Tablas de FrecuenciaDokumen38 halamanTrabajo Estadistica Tablas de FrecuenciaDarin sernaBelum ada peringkat
- Estadistica Inferencial 2Dokumen10 halamanEstadistica Inferencial 2Diana fernandez herreraBelum ada peringkat
- Métodos Matriciales para ingenieros con MATLABDari EverandMétodos Matriciales para ingenieros con MATLABPenilaian: 5 dari 5 bintang5/5 (1)
- Batalla AyacuchoDokumen73 halamanBatalla AyacuchoSantiago MondinoBelum ada peringkat
- Traduccion Guias ESPEN de NE PDFDokumen3 halamanTraduccion Guias ESPEN de NE PDFDavid M. Lesmes100% (1)
- Taller de Costos 2Dokumen2 halamanTaller de Costos 2Martha Ortega MorenoBelum ada peringkat
- Tesina Jorge Baños PDFDokumen264 halamanTesina Jorge Baños PDFpaulkohanBelum ada peringkat
- Cuadro SinopticoDokumen2 halamanCuadro Sinopticoguadalupe del carmen gordillo lugo100% (1)
- Dinámica-Unidad 2-Actividades-406bDokumen23 halamanDinámica-Unidad 2-Actividades-406bcristian lagunesBelum ada peringkat
- Banco-Preguntas-Seguridad Industrial y Salud Ocupacional - 2018Dokumen8 halamanBanco-Preguntas-Seguridad Industrial y Salud Ocupacional - 2018Dimas Cesar Mendoza SanchezBelum ada peringkat
- Lab2 - Sensor de Distancia - NataliaSánchezDokumen16 halamanLab2 - Sensor de Distancia - NataliaSánchezNatalia SanchezBelum ada peringkat
- Mademsa Ventti 460 B Plus DryerDokumen14 halamanMademsa Ventti 460 B Plus DryerSusanaGulppiPintoBelum ada peringkat
- Manual de Uso para Samsung D5000 Serie 5 SMART TVDokumen191 halamanManual de Uso para Samsung D5000 Serie 5 SMART TVjmtexla68Belum ada peringkat
- ArtistryDokumen132 halamanArtistryChicho PerezBelum ada peringkat
- BM12093 0720Dokumen4 halamanBM12093 0720Ale MPBelum ada peringkat
- Ggplot Graficos CalidadDokumen29 halamanGgplot Graficos CalidadAnonymous dQZRlcoLdhBelum ada peringkat
- Plan de Gestion Integral de Residuos Solidos PMIRSDokumen24 halamanPlan de Gestion Integral de Residuos Solidos PMIRSVivis SánchezBelum ada peringkat
- PMC Extracción y Purificación de ADN de S. AureusDokumen2 halamanPMC Extracción y Purificación de ADN de S. AureusPablo Merlo CuadraBelum ada peringkat
- LumbagoDokumen12 halamanLumbagoMacarena Vidal Illanes100% (1)
- Artropodos 2018Dokumen224 halamanArtropodos 2018Jorge Janampa Campos100% (3)
- Construcción Del Concepto de Ángulo en Estudiantes de SecundariaDokumen0 halamanConstrucción Del Concepto de Ángulo en Estudiantes de SecundariaRicardo Salinas PáezBelum ada peringkat
- Los Diagnósticos en La Infancia Alicia Stolkiner. PDF - CompressedDokumen27 halamanLos Diagnósticos en La Infancia Alicia Stolkiner. PDF - CompressedSara AdornoBelum ada peringkat
- Informe Practico de Fisica Marco OrellanaDokumen4 halamanInforme Practico de Fisica Marco OrellanaMarco OrellanaBelum ada peringkat
- Sesión 2 Método ABCDokumen12 halamanSesión 2 Método ABCBrayan jhunior SAMAYANI ESPINOZABelum ada peringkat
- Manual Emdr Fin de Semana 2Dokumen211 halamanManual Emdr Fin de Semana 2Lorena Cano Sola100% (1)
- Proyecto Del Martillo MultiusosDokumen23 halamanProyecto Del Martillo Multiusosalejandra_sanchez_meza0% (2)
- 2.cuestionario EvaluacionDokumen23 halaman2.cuestionario Evaluacionortizlizbeth907Belum ada peringkat
- Evaluación Final MATEMÁTICAS AARÓN 2A OKDokumen7 halamanEvaluación Final MATEMÁTICAS AARÓN 2A OKpamela ojedabarriaBelum ada peringkat
- Presa Los EjidosDokumen14 halamanPresa Los EjidosWils Adolfo Calle TorresBelum ada peringkat
- Clasificacion de Los Costos Segun Su Aplicacion - Elemento-9 de ContabilidadDokumen44 halamanClasificacion de Los Costos Segun Su Aplicacion - Elemento-9 de ContabilidadGary Ramírez ArceBelum ada peringkat
- El Día Internacional de La Conservación Del SueloDokumen2 halamanEl Día Internacional de La Conservación Del SueloPaul Gonzales VargasBelum ada peringkat
- Facultad de Administración: Año de La Universalización de La SaludDokumen5 halamanFacultad de Administración: Año de La Universalización de La SaludQuispe Allauja Esmit EdwinBelum ada peringkat
- Dimensionamiento de Gasoductos y Redes de Distribución deDokumen29 halamanDimensionamiento de Gasoductos y Redes de Distribución deAbner100% (1)