Anda mungkin juga menyukai
- ReadmeDokumen36 halamanReadmemaghfirataniaBelum ada peringkat
- 3.4 Reading Questions Electoral CollegeDokumen2 halaman3.4 Reading Questions Electoral CollegeIvy HoBelum ada peringkat
- Ploting Rpart Tree With PRPDokumen28 halamanPloting Rpart Tree With PRPalexa_sherpyBelum ada peringkat
- Genesis: Series: Studies On The Go by Laurie Polich-ShortDokumen18 halamanGenesis: Series: Studies On The Go by Laurie Polich-ShortZondervanBelum ada peringkat
- Matlab Beginner's GuideDokumen71 halamanMatlab Beginner's GuideHunter GaleBelum ada peringkat
- SPSS ANNOTATED OUTPUT Discriminant Analysis 1Dokumen14 halamanSPSS ANNOTATED OUTPUT Discriminant Analysis 1Aditya MehraBelum ada peringkat
- Closing The Gap The Quest To Understand Prime NumbersDokumen198 halamanClosing The Gap The Quest To Understand Prime NumbersCharmaine LimBelum ada peringkat
- Introduction To RPARTDokumen67 halamanIntroduction To RPARTSrinivas SugguBelum ada peringkat
- Q3 Week 1 Homeroom Guidance JGRDokumen9 halamanQ3 Week 1 Homeroom Guidance JGRJasmin Goot Rayos50% (4)
- Gold Price Prediction Using Machine LearningDokumen9 halamanGold Price Prediction Using Machine LearningEditor IJTSRDBelum ada peringkat
- Classification and Regression Trees Wadsworth Statistics ProbabilityDokumen420 halamanClassification and Regression Trees Wadsworth Statistics ProbabilityTitoBelum ada peringkat
- Pola Harmonik Modif WarnaDokumen14 halamanPola Harmonik Modif WarnaandreashendiBelum ada peringkat
- Paul S. Adler - Paul Du Gay - Glenn Morgan - Michael Reed (Eds.) - The Oxford Handbook of Sociology, Social Theory, and Organization Studies - Contemporary Currents-Oxford University Press, USA (2014)Dokumen817 halamanPaul S. Adler - Paul Du Gay - Glenn Morgan - Michael Reed (Eds.) - The Oxford Handbook of Sociology, Social Theory, and Organization Studies - Contemporary Currents-Oxford University Press, USA (2014)Andreea Dobrita67% (3)
- Advanced Excel - Quick Guide - TutorialspointDokumen70 halamanAdvanced Excel - Quick Guide - TutorialspointmufasBelum ada peringkat
- Technical Analysis and Nonlinear Dynamics: Vasco Jorge Salazar SoaresDokumen46 halamanTechnical Analysis and Nonlinear Dynamics: Vasco Jorge Salazar SoaresSabzgostar Avande ParsBelum ada peringkat
- Gary Antonacci - Momentum Success Factors (2012)Dokumen33 halamanGary Antonacci - Momentum Success Factors (2012)johnetownsendBelum ada peringkat
- Time Series ForecastingDokumen52 halamanTime Series ForecastingAniket ChauhanBelum ada peringkat
- ExtremeHurst For Bloomberg GuideDokumen45 halamanExtremeHurst For Bloomberg GuideBe SauBelum ada peringkat
- ESignal Manual Ch5 DashboardDokumen18 halamanESignal Manual Ch5 DashboardlaxmiccBelum ada peringkat
- Decision Trees For Predictive Modeling (Neville)Dokumen24 halamanDecision Trees For Predictive Modeling (Neville)Mohith Reddy100% (1)
- Biotechnology WebquestDokumen2 halamanBiotechnology Webquestapi-353567032Belum ada peringkat
- K-Means Clustering Algorithm: - V - ' Is The Euclidean Distance Between X ' Is The Number of Data Points in IDokumen3 halamanK-Means Clustering Algorithm: - V - ' Is The Euclidean Distance Between X ' Is The Number of Data Points in ICarlos Perez SBelum ada peringkat
- Predictive Modeling Using Decision TreesDokumen46 halamanPredictive Modeling Using Decision TreesTruely MaleBelum ada peringkat
- ClusteringDokumen104 halamanClusteringSoumyadip GhoshBelum ada peringkat
- Sidereal Zodiac For Kanpur, Uttar Pradesh, IndiaDokumen3 halamanSidereal Zodiac For Kanpur, Uttar Pradesh, IndiaAshish KushwahaBelum ada peringkat
- K Means Cluster Analysis in SPSSDokumen2 halamanK Means Cluster Analysis in SPSSsureshexecutive0% (1)
- Time and Space Analysis of AlgorithmsDokumen5 halamanTime and Space Analysis of AlgorithmsAbhishek MitraBelum ada peringkat
- Common Preps Time and Space - Ex1 PDFDokumen1 halamanCommon Preps Time and Space - Ex1 PDFblack patchxBelum ada peringkat
- Array Calc 10 DDokumen40 halamanArray Calc 10 DGustavo PaizBelum ada peringkat
- Cluster Methods in SASDokumen13 halamanCluster Methods in SASramanujsarkarBelum ada peringkat
- Principal Component Analysis Notes : InfoDokumen22 halamanPrincipal Component Analysis Notes : InfoVALMICK GUHABelum ada peringkat
- Alan Bain - Stochastic CalculusDokumen89 halamanAlan Bain - Stochastic CalculusSachin BamaneBelum ada peringkat
- Martin Gardner Codes Ciphers and Secret WritingDokumen49 halamanMartin Gardner Codes Ciphers and Secret Writingacloss2012Belum ada peringkat
- Emmett T.J. Fibonacci Based Forecasts 1985Dokumen4 halamanEmmett T.J. Fibonacci Based Forecasts 1985Om PrakashBelum ada peringkat
- The U S Economic Outlook The U.S. Economic OutlookDokumen30 halamanThe U S Economic Outlook The U.S. Economic OutlookZerohedge100% (3)
- VLOOKUP Essentials Guide Excel Campus PDFDokumen1 halamanVLOOKUP Essentials Guide Excel Campus PDFlenovojiBelum ada peringkat
- Flanagan Webinar SlidesDokumen36 halamanFlanagan Webinar SlidesOshawawookiesBelum ada peringkat
- Prime NumberDokumen8 halamanPrime NumbertriptiagBelum ada peringkat
- Facto ExtraDokumen74 halamanFacto ExtraAfulitoBelum ada peringkat
- Universiteit Hasselt Concepts in Bayesian Inference Exam June 2015Dokumen8 halamanUniversiteit Hasselt Concepts in Bayesian Inference Exam June 2015Nina MorgensternBelum ada peringkat
- Graphs of Sine, Cosine and TangentDokumen4 halamanGraphs of Sine, Cosine and TangentIsi ObohBelum ada peringkat
- H.K. Moffatt - Cosmic Dynamos: From Alpha To OmegaDokumen5 halamanH.K. Moffatt - Cosmic Dynamos: From Alpha To OmegaVortices3443Belum ada peringkat
- Market Basket Analysis and Advanced Data Mining: Professor Amit BasuDokumen24 halamanMarket Basket Analysis and Advanced Data Mining: Professor Amit BasuDinesh GahlawatBelum ada peringkat
- Python Questionnaire and ExercisesDokumen11 halamanPython Questionnaire and ExercisesԱրև ՍանամյանBelum ada peringkat
- Empirical Asset Pricing Via Machine Learning in China Stock MarketDokumen25 halamanEmpirical Asset Pricing Via Machine Learning in China Stock MarketHarsh Agarwal100% (1)
- VMS Gann Angles With Volatility Ver.1Dokumen24 halamanVMS Gann Angles With Volatility Ver.1Vipul AgrawalBelum ada peringkat
- Jaipur National University: Project Design With SeminarDokumen26 halamanJaipur National University: Project Design With SeminarFaizan Shaikh100% (1)
- K Means AlgorithmDokumen6 halamanK Means AlgorithmAsir Mosaddek SakibBelum ada peringkat
- Trade CyclesDokumen10 halamanTrade CyclessushmasomannaBelum ada peringkat
- Quadratic EquationDokumen28 halamanQuadratic EquationAffy LoveBelum ada peringkat
- Quiz #9 (CH 11) - Siyao GuanDokumen7 halamanQuiz #9 (CH 11) - Siyao Guanbalwantsharma1993Belum ada peringkat
- Project 5 - GasDokumen17 halamanProject 5 - GasAreej Aftab SiddiquiBelum ada peringkat
- Pune 08.01 Data Sheet-1Dokumen6 halamanPune 08.01 Data Sheet-1vv100% (1)
- Number System Practice QuestionsDokumen11 halamanNumber System Practice QuestionsSanskriti SahgalBelum ada peringkat
- Gann Square of 9 CalculatorDokumen3 halamanGann Square of 9 CalculatorSrinivasan SubramanianBelum ada peringkat
- Maths AssignmentDokumen6 halamanMaths AssignmentKaison LauBelum ada peringkat
- AK - STATISTIKA - 01 - Describing DataDokumen26 halamanAK - STATISTIKA - 01 - Describing DataMargareth SilvianaBelum ada peringkat
- Write Up of All Angle RulesDokumen6 halamanWrite Up of All Angle Rulesapi-233663523100% (1)
- Ebook 037 Tutorial Spss K Means Cluster Analysis PDFDokumen13 halamanEbook 037 Tutorial Spss K Means Cluster Analysis PDFShivam JadhavBelum ada peringkat
- SPSS Annotated Output K Means Cluster AnalDokumen10 halamanSPSS Annotated Output K Means Cluster AnalAditya MehraBelum ada peringkat
- Ebook 038 Tutorial Spss Two Step Cluster Analysis PDFDokumen10 halamanEbook 038 Tutorial Spss Two Step Cluster Analysis PDFRex Rieta VillavelezBelum ada peringkat
- 11-12-K Means Using SPSSDokumen4 halaman11-12-K Means Using SPSSritesh choudhuryBelum ada peringkat
- Ebook 042 Tutorial Spss Hierarchical Cluster AnalysisDokumen17 halamanEbook 042 Tutorial Spss Hierarchical Cluster AnalysissnehaBelum ada peringkat
- Selected Cities in India USA Germany and OthersDokumen4 halamanSelected Cities in India USA Germany and Othersashirwad singhBelum ada peringkat
- EdTech FinTech IndiaDokumen1 halamanEdTech FinTech Indiaashirwad singhBelum ada peringkat
- Zimbabwe With TechnologyDokumen2 halamanZimbabwe With Technologyashirwad singhBelum ada peringkat
- Chemical Using CompaniesDokumen3 halamanChemical Using Companiesashirwad singhBelum ada peringkat
- Computer Companies in Malaysia IndonesiaDokumen2 halamanComputer Companies in Malaysia Indonesiaashirwad singhBelum ada peringkat
- Notable Company in RwandaDokumen7 halamanNotable Company in Rwandaashirwad singhBelum ada peringkat
- Chap 12Dokumen27 halamanChap 12mahaweb100% (1)
- APOLLO TyresDokumen14 halamanAPOLLO Tyresashirwad singhBelum ada peringkat
- 8 QTR ResultsDokumen5 halaman8 QTR Resultsashirwad singhBelum ada peringkat
- Cetking 75 Must Do Parallel Arrangement QuestionsDokumen8 halamanCetking 75 Must Do Parallel Arrangement QuestionsTR SangramBelum ada peringkat
- CEAT TyresDokumen14 halamanCEAT Tyresashirwad singhBelum ada peringkat
- Jet Airways PDFDokumen2 halamanJet Airways PDFashirwad singhBelum ada peringkat
- Quiz Questions - Unlocked PDFDokumen6 halamanQuiz Questions - Unlocked PDFashirwad singhBelum ada peringkat
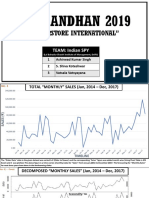
- Prabandhan 2019: "Superstore International"Dokumen9 halamanPrabandhan 2019: "Superstore International"ashirwad singhBelum ada peringkat
- TOP 50 Important GK Questions On Interim Budget 2019: Follow UsDokumen7 halamanTOP 50 Important GK Questions On Interim Budget 2019: Follow Usashirwad singhBelum ada peringkat
- Assignment-2 UktiDokumen2 halamanAssignment-2 Uktiashirwad singhBelum ada peringkat
- Sterlite Plant PDFDokumen1 halamanSterlite Plant PDFashirwad singhBelum ada peringkat
- 1Dokumen1 halaman1ashirwad singhBelum ada peringkat
- All About Ignition Coils: Technical InformationDokumen15 halamanAll About Ignition Coils: Technical InformationTrương Ngọc ThắngBelum ada peringkat
- Hilti AnchorDokumen5 halamanHilti AnchorGopi KrishnanBelum ada peringkat
- Evaluating The Policy Outcomes For Urban Resiliency in Informal Settlements Since Independence in Dhaka, Bangladesh: A ReviewDokumen14 halamanEvaluating The Policy Outcomes For Urban Resiliency in Informal Settlements Since Independence in Dhaka, Bangladesh: A ReviewJaber AbdullahBelum ada peringkat
- DMP 2021 TPJ SRDokumen275 halamanDMP 2021 TPJ SRishu sBelum ada peringkat
- Guide To Networking Essentials Fifth Edition: Making Networks WorkDokumen33 halamanGuide To Networking Essentials Fifth Edition: Making Networks WorkKhamis SeifBelum ada peringkat
- Sage 200 Evolution Training JourneyDokumen5 halamanSage 200 Evolution Training JourneysibaBelum ada peringkat
- DBR KochiDokumen22 halamanDBR Kochipmali2Belum ada peringkat
- Maverick Research: World Order 2.0: The Birth of Virtual NationsDokumen9 halamanMaverick Research: World Order 2.0: The Birth of Virtual NationsСергей КолосовBelum ada peringkat
- A2frc MetricDokumen1 halamanA2frc MetricSudar MyshaBelum ada peringkat
- Personal Information: Witec Smaranda 11, A3 Bis, Blvd. Chisinau, Bucharest, Romania 0040722597553Dokumen6 halamanPersonal Information: Witec Smaranda 11, A3 Bis, Blvd. Chisinau, Bucharest, Romania 0040722597553MirelaRoșcaBelum ada peringkat
- Instructions For The Safe Use Of: Web LashingsDokumen2 halamanInstructions For The Safe Use Of: Web LashingsVij Vaibhav VermaBelum ada peringkat
- WTO & MFA AnalysisDokumen17 halamanWTO & MFA Analysisarun1974Belum ada peringkat
- CH 3 Revision Worksheet 2 Class 6 CSDokumen1 halamanCH 3 Revision Worksheet 2 Class 6 CSShreyank SinghBelum ada peringkat
- Statement 1577731252322 PDFDokumen11 halamanStatement 1577731252322 PDFPriyanka ParidaBelum ada peringkat
- Competing Models of Entrepreneurial IntentionsDokumen22 halamanCompeting Models of Entrepreneurial IntentionsAsri Aneuk HimabisBelum ada peringkat
- Problems of Spun Concrete Piles Constructed in Soft Soil in HCMC and Mekong Delta - VietnamDokumen6 halamanProblems of Spun Concrete Piles Constructed in Soft Soil in HCMC and Mekong Delta - VietnamThaoBelum ada peringkat
- Steinway Case - CH 03Dokumen5 halamanSteinway Case - CH 03Twēéty TuiñkleBelum ada peringkat
- (1895) Indianapolis Police ManualDokumen122 halaman(1895) Indianapolis Police ManualHerbert Hillary Booker 2ndBelum ada peringkat
- Mitsubishi Forklift Fg30nm Service ManualDokumen22 halamanMitsubishi Forklift Fg30nm Service Manualbridgetsilva030690rqd100% (130)
- (Ambition) Malaysia 2023 Market Insights ReportDokumen46 halaman(Ambition) Malaysia 2023 Market Insights ReportMaz Izman BudimanBelum ada peringkat
- Transport Phenomena 18.4.CDokumen3 halamanTransport Phenomena 18.4.CDelyana RatnasariBelum ada peringkat
- Enabling Trade Report 2013, World Trade ForumDokumen52 halamanEnabling Trade Report 2013, World Trade ForumNancy Islam100% (1)
- Vacuum Dehydrator & Oil Purification System: A Filter Focus Technical Publication D1-14Dokumen1 halamanVacuum Dehydrator & Oil Purification System: A Filter Focus Technical Publication D1-14Drew LeibbrandtBelum ada peringkat
- What Is EBSD ? Why Use EBSD ? Why Measure Microstructure ? What Does EBSD Do That Cannot Already Be Done ?Dokumen5 halamanWhat Is EBSD ? Why Use EBSD ? Why Measure Microstructure ? What Does EBSD Do That Cannot Already Be Done ?Zahir Rayhan JhonBelum ada peringkat
- Berger Paints - Ar-19-20 PDFDokumen302 halamanBerger Paints - Ar-19-20 PDFSahil Garg100% (1)
- 3D Archicad Training - Module 1Dokumen3 halaman3D Archicad Training - Module 1Brahmantia Iskandar MudaBelum ada peringkat
- Easy Pictionary Words: Angel Eyeball PizzaDokumen3 halamanEasy Pictionary Words: Angel Eyeball Pizzakathy158Belum ada peringkat