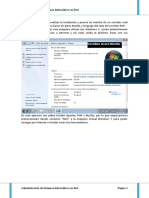
Anda mungkin juga menyukai
- SGE03Dokumen9 halamanSGE03jesusgomBelum ada peringkat
- Piris Ruiz Blas PSP05 TareaDokumen9 halamanPiris Ruiz Blas PSP05 TareakdekrisBelum ada peringkat
- Examen Trimestral de La 2 Evaluación LMGSI DAWDokumen2 halamanExamen Trimestral de La 2 Evaluación LMGSI DAWdeberes_13Belum ada peringkat
- Gomez Nunez JoseAntonio ED05 Tarea E1Dokumen7 halamanGomez Nunez JoseAntonio ED05 Tarea E1Jose Antonio Gomez NuñezBelum ada peringkat
- DAM - SGE - 19 - 20 - Tarea4Dokumen3 halamanDAM - SGE - 19 - 20 - Tarea4Elias Rodriguez Gonzalez100% (1)
- DAM AD01 Contenidos 2016 VI PDFDokumen47 halamanDAM AD01 Contenidos 2016 VI PDFpp el joputaBelum ada peringkat
- SGE01 TareaDokumen2 halamanSGE01 TareaDann SchverttBelum ada peringkat
- Tolosa Garcia Ignacio ED06 Tarea PDFDokumen6 halamanTolosa Garcia Ignacio ED06 Tarea PDFmariaBelum ada peringkat
- SI07 TareaDokumen16 halamanSI07 TareaGustaw Czujko100% (1)
- SGE03 TareaDokumen13 halamanSGE03 TareaDann Schvertt100% (2)
- Tarea07 BBDDDokumen4 halamanTarea07 BBDDnickScribano0% (1)
- SI02 - TareaDokumen5 halamanSI02 - TareaAndrea Ángel GarcíaBelum ada peringkat
- Lmsgi 05Dokumen14 halamanLmsgi 05Jose Aguila0% (1)
- TrabajoFinal SXEDokumen23 halamanTrabajoFinal SXEAlejandro AndresBelum ada peringkat
- Tarea06 BBDDDokumen2 halamanTarea06 BBDDnickScribanoBelum ada peringkat
- ED05-Tarea IndividualDokumen7 halamanED05-Tarea IndividualAaronBelum ada peringkat
- Ruiz Nieves Sara BD04 Tarea PDFDokumen13 halamanRuiz Nieves Sara BD04 Tarea PDFmaria100% (1)
- TAREA1 Sistemas InformáticosDokumen10 halamanTAREA1 Sistemas InformáticosDavid GarcíaBelum ada peringkat
- practicaBD07 PDFDokumen5 halamanpracticaBD07 PDFluis de carlosBelum ada peringkat
- BD01 TareaDokumen24 halamanBD01 TareaWilliams Agreda OrtizBelum ada peringkat
- Actividades Tema 1Dokumen1 halamanActividades Tema 1Pablo Paciarotti Di MaggioBelum ada peringkat
- Administracion de RedesDokumen16 halamanAdministracion de Redesyolandayou78Belum ada peringkat
- Solucion de La Tarea para Lmsgi01Dokumen5 halamanSolucion de La Tarea para Lmsgi01isadosBelum ada peringkat
- Tarea 2 - SI - DAMDokumen2 halamanTarea 2 - SI - DAMEliasBelum ada peringkat
- Acero Martin Carolina IAW01 TareaDokumen27 halamanAcero Martin Carolina IAW01 TareaCarolina Acero MartínBelum ada peringkat
- Práctica 3 ISODokumen7 halamanPráctica 3 ISOLeo CoronelBelum ada peringkat
- Tarea para LMSGI01Dokumen3 halamanTarea para LMSGI01franciscoBelum ada peringkat
- Iglesias Martinez Pablo BD04 Tarea BD4.2Dokumen1 halamanIglesias Martinez Pablo BD04 Tarea BD4.2Pablo Iglesias Martinez0% (1)
- Medina Garcia David SI07 TareaDokumen42 halamanMedina Garcia David SI07 TareaDavid Medina100% (1)
- Banon Martinez Angeles SI09 Tarea PDFDokumen10 halamanBanon Martinez Angeles SI09 Tarea PDFmariaBelum ada peringkat
- SI01 TareaDokumen33 halamanSI01 TareaJavier Peonza0% (1)
- Tema 3. Práctica 1Dokumen3 halamanTema 3. Práctica 1Nacho Pulido Fernandez-LayosBelum ada peringkat
- Tarea 3 ProgramaciónDokumen5 halamanTarea 3 ProgramaciónOscar Mendez0% (2)
- DAM - SGE - 19 - 20 - Tarea 5Dokumen2 halamanDAM - SGE - 19 - 20 - Tarea 5Elias Rodriguez GonzalezBelum ada peringkat
- SGE02 TareaDokumen8 halamanSGE02 TareaJose100% (1)
- LMSGI01Dokumen30 halamanLMSGI01tocinete100% (1)
- Martin Dominguez Ivan LMSGI03 TareaDokumen3 halamanMartin Dominguez Ivan LMSGI03 Tareaivan martinBelum ada peringkat
- Actividad 2Dokumen10 halamanActividad 2Claudio Jos� S�nchez SantanaBelum ada peringkat
- GBD06. - Construcción de GuionesDokumen43 halamanGBD06. - Construcción de GuionesNacho VRBelum ada peringkat
- Sistemas Informáticos - Tema - 6Dokumen7 halamanSistemas Informáticos - Tema - 6Aliesky RamosBelum ada peringkat
- Tarea Tema 5 PlataformaDokumen2 halamanTarea Tema 5 Plataformayopmail ajajBelum ada peringkat
- Tarea 5 de Base de Datos (Dam)Dokumen4 halamanTarea 5 de Base de Datos (Dam)Mario BelloBelum ada peringkat
- Tarea 6Dokumen2 halamanTarea 6Alfonso Macias MartinBelum ada peringkat
- Garcia Sanchez Felipe AW05 TareaDokumen13 halamanGarcia Sanchez Felipe AW05 TareaFelipe Garcia.sanchezBelum ada peringkat
- SI02 TareaDokumen9 halamanSI02 TareaDavid MedinaBelum ada peringkat
- BD03 TareaDokumen3 halamanBD03 TareaJesus GarciaBelum ada peringkat
- Principe Cecilia Noemi LMSGI01 Tarea PDFDokumen7 halamanPrincipe Cecilia Noemi LMSGI01 Tarea PDFAnonymous Ak7zMAZoCpBelum ada peringkat
- Solución de La Tarea para BD01Dokumen7 halamanSolución de La Tarea para BD01Chiodo EspBelum ada peringkat
- Entornos Desarrollo - Tema 6Dokumen16 halamanEntornos Desarrollo - Tema 6Alfonso AuzalBelum ada peringkat
- Tarea 5Dokumen2 halamanTarea 5Alfonso Macias MartinBelum ada peringkat
- FHW01. - Configuración de Equipos y Periféricos. Arquitectura de Ordenadores.Dokumen133 halamanFHW01. - Configuración de Equipos y Periféricos. Arquitectura de Ordenadores.corberBelum ada peringkat
- BD Tarea1Dokumen8 halamanBD Tarea1AdrianpixelBelum ada peringkat
- Assadki Mohamed Si03Dokumen15 halamanAssadki Mohamed Si03Mohamed AssadkiBelum ada peringkat
- IDP Tarea 8 AyudaDokumen4 halamanIDP Tarea 8 AyudaParidas CúperBelum ada peringkat
- TareaDokumen5 halamanTareanirvanag76Belum ada peringkat
- Solucion Propuesta Tarea 05Dokumen5 halamanSolucion Propuesta Tarea 05Marcos González GarcíaBelum ada peringkat
- BD06 TareaDokumen3 halamanBD06 TareaAntonio MartinBelum ada peringkat
- PAR04 Contenidos VIDokumen65 halamanPAR04 Contenidos VIJnXBelum ada peringkat
- Akfsdkl SI04TareaDokumen5 halamanAkfsdkl SI04TareadasflaBelum ada peringkat
- ERP Desarrollo de ComponentesDokumen17 halamanERP Desarrollo de Componentesfernandoeti64Belum ada peringkat
- Memf1601625283407r541 2 PDFDokumen2 halamanMemf1601625283407r541 2 PDFjesusgomBelum ada peringkat
- VWFS Mandato CORE PDFDokumen1 halamanVWFS Mandato CORE PDFjesusgomBelum ada peringkat
- Funciones Más Útiles para WordPressDokumen15 halamanFunciones Más Útiles para WordPressjesusgomBelum ada peringkat
- SSCI0109Dokumen23 halamanSSCI0109jesusgom0% (1)
- Proyecto Actividad 2 Hoja Instrucciones AlumnoDokumen2 halamanProyecto Actividad 2 Hoja Instrucciones AlumnojesusgomBelum ada peringkat
- UF0921 UD1 Análisis Del Sector Transporte (146 D) AFSDokumen146 halamanUF0921 UD1 Análisis Del Sector Transporte (146 D) AFSjesusgomBelum ada peringkat
- Proyecto Actividad 1 Hoja Instrucciones Alumno-2Dokumen2 halamanProyecto Actividad 1 Hoja Instrucciones Alumno-2jesusgomBelum ada peringkat
- UF0921 UD2 Clasificación Empresas Transporte (26 D)Dokumen33 halamanUF0921 UD2 Clasificación Empresas Transporte (26 D)jesusgomBelum ada peringkat
- UF0921 UD5 Transportes Bajo Rã©gimen de Autorizaciã N Especial (85 D) 1Â PDFDokumen85 halamanUF0921 UD5 Transportes Bajo Rã©gimen de Autorizaciã N Especial (85 D) 1Â PDFjesusgomBelum ada peringkat
- Jpeinados TFM0916 MemoriaDokumen203 halamanJpeinados TFM0916 Memoriajesusgom0% (1)
- UF0921 UD3 Organizacià N Empresa (72 D)Dokumen72 halamanUF0921 UD3 Organizacià N Empresa (72 D)jesusgom100% (1)
- UF0921 UD5 Transportes Bajo Rã©gimen de Autorizaciã N Especial (69 D) 2ÂDokumen69 halamanUF0921 UD5 Transportes Bajo Rã©gimen de Autorizaciã N Especial (69 D) 2ÂjesusgomBelum ada peringkat
- Glosarios y Siglas de CorreosDokumen23 halamanGlosarios y Siglas de Correosjesusgom100% (1)
- PMDM03 4Dokumen7 halamanPMDM03 4jesusgomBelum ada peringkat
- Como Montar Un PC 2020Dokumen1 halamanComo Montar Un PC 2020jesusgomBelum ada peringkat
- Almacenamiento InternoDokumen9 halamanAlmacenamiento InternojesusgomBelum ada peringkat
- PMDM03 2Dokumen10 halamanPMDM03 2jesusgomBelum ada peringkat
- Instalacion Libreria en Odoo PDFDokumen7 halamanInstalacion Libreria en Odoo PDFjesusgomBelum ada peringkat
- 1 Anuncio SUBSANACION INMLING 20-21 PDFDokumen41 halaman1 Anuncio SUBSANACION INMLING 20-21 PDFjesusgomBelum ada peringkat
- Catalogo x3 PDFDokumen23 halamanCatalogo x3 PDFjesusgomBelum ada peringkat
- Get - Patrones de Diseño PDFDokumen25 halamanGet - Patrones de Diseño PDFChristo1319Belum ada peringkat
- Actividad de Aprendizaje 2 - Diagrama de ClasesDokumen8 halamanActividad de Aprendizaje 2 - Diagrama de ClasesSergio CepedaBelum ada peringkat
- Curso de Bases de Datos - MetaDokumen29 halamanCurso de Bases de Datos - MetaFidel ParabacutoBelum ada peringkat
- Tabla - TIPOS DE DATOSDokumen17 halamanTabla - TIPOS DE DATOSÁngel RodríguezBelum ada peringkat
- Copia Texto ParaleloDokumen60 halamanCopia Texto ParaleloJAVIER ALEXIS MARTIR IRAHETABelum ada peringkat
- Procedimientos y Funciones Apuntes de C#Dokumen6 halamanProcedimientos y Funciones Apuntes de C#maldito92Belum ada peringkat
- Curso 1 C++ PDFDokumen472 halamanCurso 1 C++ PDFHector ManuelBelum ada peringkat
- Informe 3 Victor Molina - OdtDokumen25 halamanInforme 3 Victor Molina - OdtVictorAntonioMolinaBelum ada peringkat
- Teoría 5Dokumen111 halamanTeoría 5upperozy-3251Belum ada peringkat
- Investigacion Robots SerialesDokumen10 halamanInvestigacion Robots SerialesVICTOR LUIS MORON CENTENOBelum ada peringkat
- Tema 1 Desarrollo de Proyectos de SoftwareDokumen20 halamanTema 1 Desarrollo de Proyectos de SoftwareEdgar LluscoBelum ada peringkat
- POLIMORFISMODokumen10 halamanPOLIMORFISMOAquiles Jonatan Karageorge LimacheBelum ada peringkat
- PROGRAMACION CON 12 UNIDADES C#Dokumen42 halamanPROGRAMACION CON 12 UNIDADES C#Juana RodriguezBelum ada peringkat
- Diseño Lógico y NormalizaciónDokumen9 halamanDiseño Lógico y NormalizacióntecnicosiBelum ada peringkat
- Curso C++ (C Con Clase)Dokumen389 halamanCurso C++ (C Con Clase)AldoAxel100% (10)
- Proyecto Final de ProgramacionDokumen6 halamanProyecto Final de ProgramacionDiego Alejandro Gómez GaviriaBelum ada peringkat
- Presentación de Curso Programación Orientada A ObjetosDokumen5 halamanPresentación de Curso Programación Orientada A ObjetosCristian LondoñoBelum ada peringkat
- Aca 2 Bases de DatosDokumen13 halamanAca 2 Bases de DatosCamilo BurbanoBelum ada peringkat
- Inf 1fas2Dokumen120 halamanInf 1fas2Sergio Esteban Zaragoza ArmentaBelum ada peringkat
- Proyecto CorregidoDokumen138 halamanProyecto CorregidobrendaBelum ada peringkat
- Análisis y Diseño de Sistemas - Sesion 03 - Modelado de DominioDokumen27 halamanAnálisis y Diseño de Sistemas - Sesion 03 - Modelado de DominioGianfranco Eduardo Bravo LudeñaBelum ada peringkat
- Framework para Implementar Aplicaciones Web en Diferentes Lenguajes de ProgramaciónDokumen115 halamanFramework para Implementar Aplicaciones Web en Diferentes Lenguajes de ProgramaciónDiegõHmetBelum ada peringkat
- Ingresar Datos Por Teclado en La Consola - Java InicialDokumen5 halamanIngresar Datos Por Teclado en La Consola - Java InicialDelia ProyectosBelum ada peringkat
- Examen SIGDokumen5 halamanExamen SIGErick Ruben Cazarez Lopez100% (1)
- ArraysDokumen9 halamanArraysJuan CardenasBelum ada peringkat
- Resumen SIDIDokumen87 halamanResumen SIDIChusVegaPiconBelum ada peringkat
- Apuntes de Clase de Java ScriptDokumen198 halamanApuntes de Clase de Java ScriptManuel SánchezBelum ada peringkat
- Python No MuerdeDokumen97 halamanPython No MuerdeSamy OrquideaBelum ada peringkat
- Introducción A Base Datos O ODokumen26 halamanIntroducción A Base Datos O OKikers de la BorquezBelum ada peringkat
- Semana 2 Sesion 2 H21Dokumen55 halamanSemana 2 Sesion 2 H21Asael OspinoBelum ada peringkat