Anda mungkin juga menyukai
- The Six Steps of Data AnalysisDokumen4 halamanThe Six Steps of Data AnalysisGRUPOPOSITIVO POSITIVOBelum ada peringkat
- Some Concepts of Sampling & HypothesisDokumen3 halamanSome Concepts of Sampling & HypothesisMostafizur RahmanBelum ada peringkat
- ARDS CaseStudy BDokumen7 halamanARDS CaseStudy BCORROS JASMIN MARIEBelum ada peringkat
- Six Sigma in Healthcare ServiceDokumen7 halamanSix Sigma in Healthcare Service第九組林學謙Belum ada peringkat
- Dsur I Chapter 05 Exploring AssumptionsDokumen26 halamanDsur I Chapter 05 Exploring AssumptionsDannyBelum ada peringkat
- Assignment On Bayes' TheormDokumen5 halamanAssignment On Bayes' TheormmohitdinoBelum ada peringkat
- Confidence IntervalDokumen7 halamanConfidence IntervalyoyotguevarraBelum ada peringkat
- Introduction To Biostatistics1Dokumen23 halamanIntroduction To Biostatistics1Noha SalehBelum ada peringkat
- Radiography of Patients With Special NeedsDokumen14 halamanRadiography of Patients With Special NeedsPrince Ahmed100% (2)
- Ch. 7 - Sampling and Infrential StatisticsDokumen27 halamanCh. 7 - Sampling and Infrential StatisticsNour MohamedBelum ada peringkat
- Sri Guru Tegh Bahadur Institute of Management & Information Technology (Ggsipu)Dokumen63 halamanSri Guru Tegh Bahadur Institute of Management & Information Technology (Ggsipu)Pooja GarhwalBelum ada peringkat
- Introduction To Biostatistics: Reynaldo G. San Luis III, MDDokumen28 halamanIntroduction To Biostatistics: Reynaldo G. San Luis III, MDAileen JaymeBelum ada peringkat
- Cellinjury 151004125508 Lva1 App6892Dokumen147 halamanCellinjury 151004125508 Lva1 App6892Ajmal RockzzBelum ada peringkat
- Different Types of Sampling DesignsDokumen12 halamanDifferent Types of Sampling Designsshincepeterms100% (5)
- STAT Module 4Dokumen10 halamanSTAT Module 4Jayson CabreraBelum ada peringkat
- Chapter 7 Linear Energy Transfer and Relative Biologic EffecivenessDokumen43 halamanChapter 7 Linear Energy Transfer and Relative Biologic Effecivenessroxy8marie8chanBelum ada peringkat
- Chapter 1 General OverviewDokumen43 halamanChapter 1 General OverviewAbhishiktaAbhiBelum ada peringkat
- Growth AssessmentDokumen65 halamanGrowth Assessmentdr parveen bathlaBelum ada peringkat
- Presentation On SPSS: Presented byDokumen58 halamanPresentation On SPSS: Presented byFatiima Tuz ZahraBelum ada peringkat
- Basic Epidemiology Lessons 1 5Dokumen99 halamanBasic Epidemiology Lessons 1 5Khelly Joshua UyBelum ada peringkat
- Clinical Picture, Diagnosis and Treatment: Acute Radiation SyndromeDokumen77 halamanClinical Picture, Diagnosis and Treatment: Acute Radiation SyndromeAinsley Macmorris UlbrechtBelum ada peringkat
- Inferential StatisticsDokumen119 halamanInferential StatisticsG Gጂጂ TubeBelum ada peringkat
- The TongueDokumen21 halamanThe Tonguemanojchouhan2014Belum ada peringkat
- CH 14Dokumen13 halamanCH 14Manish MalikBelum ada peringkat
- FDIDokumen9 halamanFDIPankaj ChetryBelum ada peringkat
- Alveolar Bone in HealthDokumen43 halamanAlveolar Bone in HealthAdit VekariaBelum ada peringkat
- CorrelationDokumen13 halamanCorrelationShishir SoodanaBelum ada peringkat
- Gdi and GemDokumen32 halamanGdi and GemDaVid Silence KawlniBelum ada peringkat
- Introduction To Community Dentistry and Dental Public HealthDokumen36 halamanIntroduction To Community Dentistry and Dental Public HealthAnosha RiazBelum ada peringkat
- AnnovaDokumen19 halamanAnnovaLabiz Saroni Zida0% (1)
- 001 Lecture1Dokumen86 halaman001 Lecture1intj2001712100% (1)
- CatpcaDokumen19 halamanCatpcaRodito AcolBelum ada peringkat
- Overview of Research ProcessDokumen3 halamanOverview of Research ProcessKenneth GuingabBelum ada peringkat
- Complete Notes STATSDokumen16 halamanComplete Notes STATSsilvestre bolosBelum ada peringkat
- Regression AnalysisDokumen21 halamanRegression AnalysisjjjjkjhkhjkhjkjkBelum ada peringkat
- Anova 1: Eric Jacobs Hubert KorziliusDokumen39 halamanAnova 1: Eric Jacobs Hubert KorziliusPolinaBelum ada peringkat
- Biostatistics (Correlation and Regression)Dokumen29 halamanBiostatistics (Correlation and Regression)Devyani Marathe100% (1)
- Unit 4: Ethical Frameworks and Principles in Moral DispositionDokumen23 halamanUnit 4: Ethical Frameworks and Principles in Moral DispositionJohn Carlo LadieroBelum ada peringkat
- Teeth Numeration SystemDokumen33 halamanTeeth Numeration Systemhind shabanBelum ada peringkat
- Chapter 1. BiostatisticsDokumen34 halamanChapter 1. BiostatisticsHend maarofBelum ada peringkat
- Triangles of NeckDokumen59 halamanTriangles of NeckParijat Chakraborty PJBelum ada peringkat
- ANOVA and RegressionDokumen1 halamanANOVA and Regressiontkhattab999Belum ada peringkat
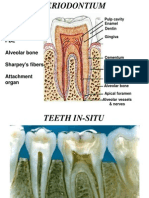
- Periodontium 1Dokumen65 halamanPeriodontium 1Hussain M A KhuwajaBelum ada peringkat
- Hypothesis Testing: Frances Chumney, PHDDokumen38 halamanHypothesis Testing: Frances Chumney, PHDHenry DogoodBelum ada peringkat
- Measures of Central Tendency - Dispersion - Skewness - NOTES PGDMDokumen89 halamanMeasures of Central Tendency - Dispersion - Skewness - NOTES PGDMVartika NagarBelum ada peringkat
- Probability and Probability DistributionDokumen46 halamanProbability and Probability DistributionEdna Lip AnerBelum ada peringkat
- RegressionDokumen6 halamanRegressionooveBelum ada peringkat
- Applied Statistics II-2 and IIIDokumen59 halamanApplied Statistics II-2 and IIIMagnifico FangaWoroBelum ada peringkat
- Session 3 - Logistic RegressionDokumen28 halamanSession 3 - Logistic RegressionNausheen Fatima50% (2)
- Components of A Complete Periodontal ExaminationDokumen12 halamanComponents of A Complete Periodontal ExaminationIvan Fadhillah NurdinBelum ada peringkat
- Chapter 12 ANOVADokumen25 halamanChapter 12 ANOVAMadison HartfieldBelum ada peringkat
- Measures of SkewnessDokumen12 halamanMeasures of Skewnesssameera26Belum ada peringkat
- Human Physiology Cell Structure Function I Lecture 31.july - .2012Dokumen21 halamanHuman Physiology Cell Structure Function I Lecture 31.july - .2012Aakash ReddyBelum ada peringkat
- Introduction To BiostatisticsDokumen13 halamanIntroduction To BiostatisticsGarmenkellBelum ada peringkat
- Session2-Simple Linear Model PDFDokumen56 halamanSession2-Simple Linear Model PDFindrakuBelum ada peringkat
- Anatomy of The Maxilla and Mandible and Anatomical Safety ZonesDokumen40 halamanAnatomy of The Maxilla and Mandible and Anatomical Safety ZonesM Priya100% (2)
- The Normal PeriodontiumDokumen38 halamanThe Normal PeriodontiumAlex HaileyesusBelum ada peringkat
- 12-3 Measures of Central Tendency and DispersionDokumen10 halaman12-3 Measures of Central Tendency and DispersionNoman AliBelum ada peringkat
- SPSS AssignmentDokumen8 halamanSPSS AssignmentYamini JohriBelum ada peringkat
- RM Practical FileDokumen59 halamanRM Practical Filegarvit sharmaBelum ada peringkat
- Physical Therapy Protocols For Conditions of Shoulder RegionDokumen111 halamanPhysical Therapy Protocols For Conditions of Shoulder RegionPieng Napa100% (1)
- Physical Therapy Protocols - Knee ConditionsDokumen120 halamanPhysical Therapy Protocols - Knee Conditionssayles4174100% (1)
- Physical Therapy Protocols For Conditions of Thorax RegionDokumen52 halamanPhysical Therapy Protocols For Conditions of Thorax RegionVytautas PilelisBelum ada peringkat
- Research - Step by StepDokumen1 halamanResearch - Step by StepShrutiBelum ada peringkat
- Physical Therapy Protocols For Conditions of The Low Back RegionDokumen76 halamanPhysical Therapy Protocols For Conditions of The Low Back RegiontinadasilvaBelum ada peringkat
- Physical Therapy Protocols For The Conditions of Hip RegionDokumen50 halamanPhysical Therapy Protocols For The Conditions of Hip RegionAnita GajariBelum ada peringkat
- Physical Therapy Protocols For Ankle and Foot ConditionsDokumen116 halamanPhysical Therapy Protocols For Ankle and Foot ConditionstinadasilvaBelum ada peringkat
- Physical Therapy Protocols For Conditions of Elbow RegionDokumen96 halamanPhysical Therapy Protocols For Conditions of Elbow RegionerwincapiBelum ada peringkat
- Upper Extremity Physical Therapy ExercisesDokumen14 halamanUpper Extremity Physical Therapy ExercisesShrutiBelum ada peringkat
- Lower Extremity Physical Therapy ExercisesDokumen13 halamanLower Extremity Physical Therapy ExercisesShruti100% (1)
- Orthopedics Standard of Care GuidelinesDokumen543 halamanOrthopedics Standard of Care GuidelinesppeterarmstrongBelum ada peringkat
- How To Conduct A Literature Search - An OverviewDokumen39 halamanHow To Conduct A Literature Search - An OverviewShrutiBelum ada peringkat
- Brigham & Women's Hospital - Return To Sports GuidelinesDokumen17 halamanBrigham & Women's Hospital - Return To Sports GuidelinesShruti100% (1)
- Brigham & Women's Hospital - Elbow & Hand Rehabilitation PT ProtocolsDokumen25 halamanBrigham & Women's Hospital - Elbow & Hand Rehabilitation PT ProtocolsShrutiBelum ada peringkat
- Shoulder Post-Operative Rehabilitation ProtocolsDokumen6 halamanShoulder Post-Operative Rehabilitation ProtocolsShrutiBelum ada peringkat
- Brigham & Women's Hospital - Knee Rehabilitation PT ProtocolsDokumen27 halamanBrigham & Women's Hospital - Knee Rehabilitation PT ProtocolsShrutiBelum ada peringkat
- SamplingDokumen30 halamanSamplingShrutiBelum ada peringkat
- CardioDokumen6 halamanCardioShrutiBelum ada peringkat
- ExerciseDokumen5 halamanExerciseShrutiBelum ada peringkat
- Verilum® 5.2: Video Display Calibration and Conformance TrackingDokumen19 halamanVerilum® 5.2: Video Display Calibration and Conformance TrackingleagagaBelum ada peringkat
- Core Redhat Linux System Administraton Version 6 7 & 8Dokumen5 halamanCore Redhat Linux System Administraton Version 6 7 & 8iaas labsBelum ada peringkat
- Configurar MRTGDokumen5 halamanConfigurar MRTGNTMINFO SEMEDBelum ada peringkat
- Project File Student Management SystemDokumen14 halamanProject File Student Management Systemshivakumar kondavenkataBelum ada peringkat
- Home Designer Suite 2021 Users GuideDokumen122 halamanHome Designer Suite 2021 Users Guiderick.mccort2766Belum ada peringkat
- QSI QTERM Handheld Terminal - ManualDokumen46 halamanQSI QTERM Handheld Terminal - ManualDefaultAnomolyBelum ada peringkat
- Hardware Manual MP4800 - EnglishDokumen45 halamanHardware Manual MP4800 - EnglishAta Uey100% (1)
- Forcepoint DLP HelpDokumen530 halamanForcepoint DLP HelpAjeetBelum ada peringkat
- How To Configure Samba On RedHat LinuxDokumen4 halamanHow To Configure Samba On RedHat LinuxTamil SelvanBelum ada peringkat
- PADT TheFocus 35 PDFDokumen18 halamanPADT TheFocus 35 PDFDipak BorsaikiaBelum ada peringkat
- PHP and MySql-IVDokumen13 halamanPHP and MySql-IVSuriya KakaniBelum ada peringkat
- FSN 13-03-003 - Verix V SDK Version 3.7.4 Release DevNetDokumen3 halamanFSN 13-03-003 - Verix V SDK Version 3.7.4 Release DevNetsoy_yosBelum ada peringkat
- Formatting Instructions For Neurips 2018Dokumen5 halamanFormatting Instructions For Neurips 2018G RichardBelum ada peringkat
- Laravel HandbookDokumen111 halamanLaravel Handbookguillermo oceguedaBelum ada peringkat
- SeaLINK Operation Manual V5.0Dokumen38 halamanSeaLINK Operation Manual V5.0garifu_san100% (2)
- Disk Storage, Basic File Structures, and HashingDokumen18 halamanDisk Storage, Basic File Structures, and HashingHasnaa AdelBelum ada peringkat
- Mcafee Application Control 8.2.0 - Windows Product Guide 1-4-2021Dokumen129 halamanMcafee Application Control 8.2.0 - Windows Product Guide 1-4-2021Valentin Stefan TalpeanuBelum ada peringkat
- Normalization Book PDFDokumen181 halamanNormalization Book PDFThenmozhi RajagopalBelum ada peringkat
- TSM Backup & Restoration CommandsDokumen2 halamanTSM Backup & Restoration Commandskart_kartBelum ada peringkat
- SDescDokumen27 halamanSDescBlobBelum ada peringkat
- Daysim ManualDokumen48 halamanDaysim ManualMuhammadAhmadBelum ada peringkat
- Cardpeek Reference ManualDokumen60 halamanCardpeek Reference Manualstudent dzBelum ada peringkat
- Manual Modflow 6 251 292Dokumen42 halamanManual Modflow 6 251 292cerbero perroBelum ada peringkat
- Tender SpecificationsDokumen13 halamanTender SpecificationsRizwan Alam SiddiquiBelum ada peringkat
- Make Tutorial: 6.1 SetupDokumen9 halamanMake Tutorial: 6.1 SetuprajBelum ada peringkat
- Curve Expert ProDokumen213 halamanCurve Expert ProJerry Vivas TorrezBelum ada peringkat
- Formatting in MS WordDokumen10 halamanFormatting in MS WordvivsridharBelum ada peringkat
- ATPDraw 5 User Manual UpdatesDokumen51 halamanATPDraw 5 User Manual UpdatesdoniluzBelum ada peringkat
- BMC ProactiveNetDokumen594 halamanBMC ProactiveNetfranc_estorsBelum ada peringkat