Anda mungkin juga menyukai
- Advanced OS Assignment 3 Thread Management-1Dokumen2 halamanAdvanced OS Assignment 3 Thread Management-1khan aliBelum ada peringkat
- Latch Lock and Mutex Contention TroubleshootingDokumen20 halamanLatch Lock and Mutex Contention Troubleshootingvippy_love100% (1)
- KernrateDokumen22 halamanKernrateSandro ReimãoBelum ada peringkat
- Ractice Roblems O S: I D P: Perating Ystems Nternals and Esign Rinciples S EDokumen28 halamanRactice Roblems O S: I D P: Perating Ystems Nternals and Esign Rinciples S EHamza Asim Ghazi100% (1)
- Squid LogDokumen18 halamanSquid LogxuserBelum ada peringkat
- SRS Library Cache Locks Report: Service Response GuideDokumen8 halamanSRS Library Cache Locks Report: Service Response Guideshaikali1980Belum ada peringkat
- How To Configure Two Node High Availability Cluster On RHELDokumen18 halamanHow To Configure Two Node High Availability Cluster On RHELslides courseBelum ada peringkat
- Informations Some Interfaces of Proc Filesystem. Is There Any Other Ways To Get Process Memory Informations Apart From Proc Interfaces?Dokumen10 halamanInformations Some Interfaces of Proc Filesystem. Is There Any Other Ways To Get Process Memory Informations Apart From Proc Interfaces?kumar0% (1)
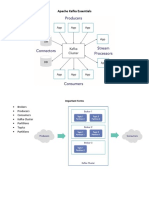
- Apache KafkaDokumen6 halamanApache KafkaJason GomezBelum ada peringkat
- Oracle - Pass4sure.1z0 070.v2017!11!24.by - Florida.50qDokumen39 halamanOracle - Pass4sure.1z0 070.v2017!11!24.by - Florida.50qsandeep_aietBelum ada peringkat
- Iitd Exam Os SolutionDokumen6 halamanIitd Exam Os SolutionRohit JoshiBelum ada peringkat
- S1, 2019 - V:1 (Monday, 25.02.2019, 16:00) Use For Class CommunicationsDokumen5 halamanS1, 2019 - V:1 (Monday, 25.02.2019, 16:00) Use For Class CommunicationsMister007jhBelum ada peringkat
- Oracle Real-Exams 1z0-070 v2021-04-27 by Alexander 63qDokumen46 halamanOracle Real-Exams 1z0-070 v2021-04-27 by Alexander 63qMoataz AbdelhamidBelum ada peringkat
- Hibernate CachingDokumen4 halamanHibernate CachingMonikhaBelum ada peringkat
- W4118 Operating Systems: Instructor: Junfeng YangDokumen30 halamanW4118 Operating Systems: Instructor: Junfeng Yangsonia123Belum ada peringkat
- Brendan Gregg: Container Performance AnalysisDokumen75 halamanBrendan Gregg: Container Performance Analysiscsy365Belum ada peringkat
- Oracle PracticeTest 1z0-070 v2017-12-11 by Tristan 49qDokumen39 halamanOracle PracticeTest 1z0-070 v2017-12-11 by Tristan 49qMoataz AbdelhamidBelum ada peringkat
- Nexus Notes Session-01Dokumen9 halamanNexus Notes Session-01SUDHAN RBelum ada peringkat
- IC Compiler Data Setup & Basic Flow: Learning ObjectivesDokumen16 halamanIC Compiler Data Setup & Basic Flow: Learning ObjectiveschenBelum ada peringkat
- IBM DS8000 Storage Allocation Overview Including Thin ProvisioningDokumen39 halamanIBM DS8000 Storage Allocation Overview Including Thin ProvisioningRam GuggulBelum ada peringkat
- CtsDokumen13 halamanCtsAnonymous qX2xaKBelum ada peringkat
- HibernateDokumen161 halamanHibernateNagendra VenkatBelum ada peringkat
- DB Server Limits (Process/sessions) DB Server Limits (Process/sessions)Dokumen21 halamanDB Server Limits (Process/sessions) DB Server Limits (Process/sessions)imran ahmedBelum ada peringkat
- MCS 041 2011Dokumen7 halamanMCS 041 2011peetkumarBelum ada peringkat
- A Framework For Analyzing and Improving Content-Based Chunking Algorithms - 2005Dokumen11 halamanA Framework For Analyzing and Improving Content-Based Chunking Algorithms - 2005IsaacBelum ada peringkat
- Cse410 Sp09 Final SolDokumen10 halamanCse410 Sp09 Final Soladchy7Belum ada peringkat
- Rac Q&aDokumen51 halamanRac Q&aVeeranji VelpulaBelum ada peringkat
- L1 Cache iMXRT AN12042Dokumen14 halamanL1 Cache iMXRT AN12042Catalin NeacsuBelum ada peringkat
- Introduction To The Linux KernelDokumen51 halamanIntroduction To The Linux Kernelbharath_mv7-1Belum ada peringkat
- 01 Stornext ConceptsDokumen6 halaman01 Stornext ConceptsEmerson LimaBelum ada peringkat
- Design Compiler SynthesisDokumen14 halamanDesign Compiler SynthesisafriendBelum ada peringkat
- Lab 3 CPEN 311Dokumen15 halamanLab 3 CPEN 311gaojiajun1058Belum ada peringkat
- Fluent 6 & CFX 5Dokumen20 halamanFluent 6 & CFX 5Pritish MohanBelum ada peringkat
- Ass 2Dokumen8 halamanAss 2Anjani KunwarBelum ada peringkat
- Data Deduplication Quantum Stornext: Real Tes NG Real Data Real ResultsDokumen49 halamanData Deduplication Quantum Stornext: Real Tes NG Real Data Real ResultsmbuddhikotBelum ada peringkat
- CachelabDokumen10 halamanCachelab张凡Belum ada peringkat
- DTN NS3Dokumen4 halamanDTN NS3Mirza RizkyBelum ada peringkat
- Cache-Assignment Handout 12Dokumen9 halamanCache-Assignment Handout 12sch123321Belum ada peringkat
- 19CS2106S 19CS2106A Test - I Set - 1 Key and SchemeDokumen8 halaman19CS2106S 19CS2106A Test - I Set - 1 Key and SchemeKilla AparnaBelum ada peringkat
- Technical Skills Enhancement - PL/SQL Best Practices Oracle ArchitectureDokumen35 halamanTechnical Skills Enhancement - PL/SQL Best Practices Oracle ArchitectureHuynh Sy NguyenBelum ada peringkat
- EE204 - Computer Architecture Course ProjectDokumen7 halamanEE204 - Computer Architecture Course ProjectSuneelKumarChauhanBelum ada peringkat
- Sun Grid Engine TutorialDokumen14 halamanSun Grid Engine TutorialoligoelementoBelum ada peringkat
- Openstack Ha Guide TrunkDokumen24 halamanOpenstack Ha Guide TrunkluchoalcoBelum ada peringkat
- Chapter 5 Memory ManagmentDokumen27 halamanChapter 5 Memory ManagmentNasis DerejeBelum ada peringkat
- Cache Memory ADokumen62 halamanCache Memory ARamiz KrasniqiBelum ada peringkat
- Lab 2 Process & Multithreaded Process Course: Operating SystemsDokumen18 halamanLab 2 Process & Multithreaded Process Course: Operating SystemsNhân ChuBelum ada peringkat
- Prj5 - Thread SynchronizationDokumen6 halamanPrj5 - Thread SynchronizationadminBelum ada peringkat
- BT0051 To BT0055 All in One BScIT SMU Assignment (Complited)Dokumen51 halamanBT0051 To BT0055 All in One BScIT SMU Assignment (Complited)raunak19Belum ada peringkat
- Docker SBeliakou Part03Dokumen61 halamanDocker SBeliakou Part03fqkjcwfcidtsmlcxaaBelum ada peringkat
- Cache LabDokumen10 halamanCache Labarteepu37022Belum ada peringkat
- Linux Administration - Linux Interview Questions 7Dokumen5 halamanLinux Administration - Linux Interview Questions 7click2chaituBelum ada peringkat
- Enter Post Title HereDokumen12 halamanEnter Post Title HereArun JagaBelum ada peringkat
- Cisco ANA Registry Backup and RestoreDokumen10 halamanCisco ANA Registry Backup and Restoreton047hive991Belum ada peringkat
- prj1 Specs2010Dokumen15 halamanprj1 Specs2010Punit SoniBelum ada peringkat
- Tecnologico de Estudios Superiores de Ecatepec: Proyecto Final MinishellDokumen17 halamanTecnologico de Estudios Superiores de Ecatepec: Proyecto Final MinishellIgnacio Gutierrez GomezBelum ada peringkat
- WinCC Flexible Langzeitarchivierung en PDFDokumen44 halamanWinCC Flexible Langzeitarchivierung en PDFEdson LeandroBelum ada peringkat
- Preface: Introduction To VLSI Circuits and SystemsDokumen16 halamanPreface: Introduction To VLSI Circuits and SystemsraviBelum ada peringkat
- ELECTRONIC DATA PROCESSING and COMPUTER SYSTEMS BSCE 1A G3 - ReportDokumen32 halamanELECTRONIC DATA PROCESSING and COMPUTER SYSTEMS BSCE 1A G3 - ReportcdaineredBelum ada peringkat
- Write A Program To Accept Username and Password From The End User Text View and Edit TextDokumen7 halamanWrite A Program To Accept Username and Password From The End User Text View and Edit TextSs1122100% (1)
- BACnet MS TP Configuration Guide PN50032 Rev A Mar 2020Dokumen14 halamanBACnet MS TP Configuration Guide PN50032 Rev A Mar 2020litonBelum ada peringkat
- Dice Resume CV Jose GazoDokumen3 halamanDice Resume CV Jose Gazovamsi chinniBelum ada peringkat
- NCS Catalogue - 2020Dokumen173 halamanNCS Catalogue - 2020Đức Nguyễn VănBelum ada peringkat
- Test Case TemplateDokumen9 halamanTest Case TemplateFajar AkhtarBelum ada peringkat
- Dawood University of Engineering and Technology, KarachiDokumen19 halamanDawood University of Engineering and Technology, KarachiOSAMABelum ada peringkat
- Test Class Interview QuestionDokumen3 halamanTest Class Interview QuestionMradul SinghBelum ada peringkat
- Text File Hiding Randomly Using Secret Sharing Scheme: Yossra H. AliDokumen6 halamanText File Hiding Randomly Using Secret Sharing Scheme: Yossra H. AliesrBelum ada peringkat
- Question: Why Are Collisions Not Very Important in Modern Networks? WHDokumen1 halamanQuestion: Why Are Collisions Not Very Important in Modern Networks? WHAdrian Villanueva DatoBelum ada peringkat
- Affiliate MarketingDokumen2 halamanAffiliate Marketingjason7sean-30030Belum ada peringkat
- Dempster-Shafer Theory: Introduction, Connections With Rough Sets and Application To ClusteringDokumen48 halamanDempster-Shafer Theory: Introduction, Connections With Rough Sets and Application To Clusteringhenri joel jrBelum ada peringkat
- Platform License Agreement 12 Sept 2023Dokumen8 halamanPlatform License Agreement 12 Sept 2023voot00voot2326Belum ada peringkat
- SDM MCQ BankDokumen87 halamanSDM MCQ BankRamkishan ShindeBelum ada peringkat
- Communication: Past and Present Means and Modes OFDokumen17 halamanCommunication: Past and Present Means and Modes OFankitghoshBelum ada peringkat
- RFC 430Dokumen96 halamanRFC 430birinderBelum ada peringkat
- Nanovna: Very Tiny Handheld Vector Network Analyzer User GuideDokumen12 halamanNanovna: Very Tiny Handheld Vector Network Analyzer User GuidemykillerdroneBelum ada peringkat
- DDI0598C B MPAM SupplementDokumen410 halamanDDI0598C B MPAM SupplementBob DengBelum ada peringkat
- CT071-3-3-DDAC-Class Test Paper #2 - QuestionDokumen8 halamanCT071-3-3-DDAC-Class Test Paper #2 - QuestionPurnima OliBelum ada peringkat
- Aukey BluetoothDokumen1 halamanAukey BluetoothJavier FernándezBelum ada peringkat
- MS125 Switches: Layer 2 Access Switches With 10G SFP+ Uplinks, Designed For Small Branch DeploymentsDokumen6 halamanMS125 Switches: Layer 2 Access Switches With 10G SFP+ Uplinks, Designed For Small Branch DeploymentsShiva PrasadBelum ada peringkat
- 1 Dvs 2 Dvs 3 DDokumen114 halaman1 Dvs 2 Dvs 3 Djuan jose sarazu cotrina100% (1)
- Graphic Violence On Social Media and Its Impact On Young AdultsDokumen11 halamanGraphic Violence On Social Media and Its Impact On Young AdultsPsychology and Education: A Multidisciplinary JournalBelum ada peringkat
- SIFANG CSC-150EB V1.03 Busbar Protection IED Manual 2019-11Dokumen186 halamanSIFANG CSC-150EB V1.03 Busbar Protection IED Manual 2019-11MarkusKunBelum ada peringkat
- s21 Ultra 5g Galaxy Buds LiveDokumen3 halamans21 Ultra 5g Galaxy Buds LiveFakhryBelum ada peringkat
- Contextual Report (2023006)Dokumen24 halamanContextual Report (2023006)Tech FiFtyBelum ada peringkat
- 2009-Microsoft Semantic EngineDokumen25 halaman2009-Microsoft Semantic EngineLi DingBelum ada peringkat
- Hydrogen ManualDokumen16 halamanHydrogen Manualsunking0604Belum ada peringkat
- Uas Adt 20112082 Empud MahpudinDokumen2 halamanUas Adt 20112082 Empud MahpudinEmpud MahpudinBelum ada peringkat