Anda mungkin juga menyukai
- VAR - Analysis - Phan Tich Tu Hoi QuyDokumen15 halamanVAR - Analysis - Phan Tich Tu Hoi QuybacchinhBelum ada peringkat
- SVAR Model BreakdownDokumen31 halamanSVAR Model BreakdownEddie Barrionuevo100% (1)
- Thermal Fit of Hollow DiskDokumen15 halamanThermal Fit of Hollow DiskFlynn GouldBelum ada peringkat
- TensorsDokumen46 halamanTensorsfoufou200350% (2)
- N-R BasicsDokumen46 halamanN-R BasicsHossain 'Soroosh' MohammadiBelum ada peringkat
- Mechanics of Solids Week 6 LecturesDokumen8 halamanMechanics of Solids Week 6 LecturesFlynn GouldBelum ada peringkat
- Ee602 Ac CircuitDokumen26 halamanEe602 Ac CircuitArryshah DahmiaBelum ada peringkat
- EE369 Power Flow Analysis LectureDokumen33 halamanEE369 Power Flow Analysis LectureAnikendu MaitraBelum ada peringkat
- Classnotes For Classical Control Theory: I. E. K Ose Dept. of Mechanical Engineering Bo Gazici UniversityDokumen51 halamanClassnotes For Classical Control Theory: I. E. K Ose Dept. of Mechanical Engineering Bo Gazici UniversityGürkan YamanBelum ada peringkat
- LAPLACE TRANSFORM CIRCUIT ANALYSISDokumen56 halamanLAPLACE TRANSFORM CIRCUIT ANALYSISSando CrisiasaBelum ada peringkat
- EMSD CH 1'2.tensor CalcDokumen50 halamanEMSD CH 1'2.tensor CalcOsama HassanBelum ada peringkat
- AC Circuit AnalysisDokumen45 halamanAC Circuit Analysissodapop1999Belum ada peringkat
- DRM SolutionsDokumen116 halamanDRM SolutionsCésar TapiaBelum ada peringkat
- Two-Dimensional Elasticity Theories and Plane ProblemsDokumen18 halamanTwo-Dimensional Elasticity Theories and Plane ProblemsHk Lorilla QuongBelum ada peringkat
- Chap 1 Preliminary Concepts: Nkim@ufl - EduDokumen20 halamanChap 1 Preliminary Concepts: Nkim@ufl - Edudozio100% (1)
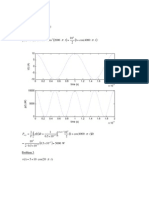
- Problem 2) 2000 Cos (10) ( : T AvgDokumen8 halamanProblem 2) 2000 Cos (10) ( : T AvgSova ŽalosnaBelum ada peringkat
- State EstimationDokumen34 halamanState EstimationFengxing ZhuBelum ada peringkat
- Divyanshu Prakash: Mewar University, ChittorgarhDokumen27 halamanDivyanshu Prakash: Mewar University, ChittorgarhsitakantasamantarayBelum ada peringkat
- ChewMA1506-14 Ch8 PDFDokumen69 halamanChewMA1506-14 Ch8 PDFalibabawalaoaBelum ada peringkat
- 3 SLAjitprasadDokumen17 halaman3 SLAjitprasadJaya JvBelum ada peringkat
- T V T Ri T DT Di L:) (: KVL Or, State Steady inDokumen23 halamanT V T Ri T DT Di L:) (: KVL Or, State Steady inPranjal BatraBelum ada peringkat
- Exam 3Dokumen8 halamanExam 3methmadBelum ada peringkat
- State Space Representation Part-1Dokumen47 halamanState Space Representation Part-1SingappuliBelum ada peringkat
- Mechanics of Solids Week 10 LecturesDokumen9 halamanMechanics of Solids Week 10 LecturesFlynn GouldBelum ada peringkat
- MODELING LINEAR SYSTEMSDokumen39 halamanMODELING LINEAR SYSTEMSFreyley LeyvaBelum ada peringkat
- C2 Sdof2 PDFDokumen20 halamanC2 Sdof2 PDFArThur BangunBelum ada peringkat
- Machine Learning Tutorial SolutionsDokumen8 halamanMachine Learning Tutorial SolutionsNguyen Tien ThanhBelum ada peringkat
- Vector Autoregression Analysis: Estimation and InterpretationDokumen36 halamanVector Autoregression Analysis: Estimation and Interpretationcharles_j_gomezBelum ada peringkat
- RT Exercises and Solutions Med TentatalDokumen264 halamanRT Exercises and Solutions Med TentatalSANA100% (1)
- Quick review of index notationDokumen5 halamanQuick review of index notationFrank SandorBelum ada peringkat
- Asset-V1 BuX+EEE321+2021 Summer+Type@Asset+Block@Fault Current Transient On Transmission LineDokumen16 halamanAsset-V1 BuX+EEE321+2021 Summer+Type@Asset+Block@Fault Current Transient On Transmission LineAbrar ChowdhuryBelum ada peringkat
- Elementary Tutorial: Fundamentals of Linear VibrationsDokumen51 halamanElementary Tutorial: Fundamentals of Linear VibrationsfujinyuanBelum ada peringkat
- Mechanics of Solids Week 5 LecturesDokumen10 halamanMechanics of Solids Week 5 LecturesFlynn GouldBelum ada peringkat
- 8.systems of Difference Equations NewDokumen2 halaman8.systems of Difference Equations NewmetaxurgioBelum ada peringkat
- Box-Jenkins ARIMA Models for Non-Seasonal Time SeriesDokumen29 halamanBox-Jenkins ARIMA Models for Non-Seasonal Time SeriesSylvia CheungBelum ada peringkat
- Full Elementary Aerodynamics Course by MITDokumen158 halamanFull Elementary Aerodynamics Course by MIT34plt34Belum ada peringkat
- References: 10m/s 60cm 60cmDokumen9 halamanReferences: 10m/s 60cm 60cmAliOucharBelum ada peringkat
- VAR Stability AnalysisDokumen11 halamanVAR Stability AnalysisCristian CernegaBelum ada peringkat
- Notes 1 - Transmission Line TheoryDokumen82 halamanNotes 1 - Transmission Line TheoryJaime MendozaBelum ada peringkat
- Cone NotesDokumen5 halamanCone NotesamirlatBelum ada peringkat
- Space Vector Definition and Projection RulesDokumen19 halamanSpace Vector Definition and Projection RulesGovor CristianBelum ada peringkat
- 2 Lyapunov Direct MethodDokumen39 halaman2 Lyapunov Direct Methodbluefantasy604Belum ada peringkat
- Typical Aircraft Open-Loop Motions - Longitudinal Modes - Impact of ActuatorsDokumen15 halamanTypical Aircraft Open-Loop Motions - Longitudinal Modes - Impact of Actuatorsgredre113Belum ada peringkat
- Lab3 v2Dokumen10 halamanLab3 v2Pranshumaan SinghBelum ada peringkat
- Power Systems With MATLABDokumen156 halamanPower Systems With MATLABJuan Alex Arequipa ChecaBelum ada peringkat
- HW 5 SolDokumen20 halamanHW 5 SolKhoa Le TienBelum ada peringkat
- Vibrations and Waves Course NotesDokumen125 halamanVibrations and Waves Course NotesMatthew BaileyBelum ada peringkat
- 1 Controllability and Observability: MAE 280 B 5 Maur Icio de OliveiraDokumen18 halaman1 Controllability and Observability: MAE 280 B 5 Maur Icio de OliveiraAshkan Nourizadeh DehkordiBelum ada peringkat
- Control of Aircraft MotionsDokumen43 halamanControl of Aircraft MotionsjameelahmadBelum ada peringkat
- Chap 1Dokumen20 halamanChap 1torinomgBelum ada peringkat
- Week 9 Labview: "Numerical Solution of A Second-Order Linear Ode"Dokumen5 halamanWeek 9 Labview: "Numerical Solution of A Second-Order Linear Ode"Michael LiBelum ada peringkat
- Ufabccapitulo 1Dokumen121 halamanUfabccapitulo 1Leonardo De Avellar FredericoBelum ada peringkat
- New EM4Dokumen28 halamanNew EM4Srinivasagopalan MadhavanBelum ada peringkat
- TimeSeriesAnalysis&ItsApplications2e Shumway PDFDokumen82 halamanTimeSeriesAnalysis&ItsApplications2e Shumway PDFClaudio Ramón Rodriguez Mondragón91% (11)
- Introductory Differential Equations: with Boundary Value Problems, Student Solutions Manual (e-only)Dari EverandIntroductory Differential Equations: with Boundary Value Problems, Student Solutions Manual (e-only)Belum ada peringkat
- Answers to Selected Problems in Multivariable Calculus with Linear Algebra and SeriesDari EverandAnswers to Selected Problems in Multivariable Calculus with Linear Algebra and SeriesPenilaian: 1.5 dari 5 bintang1.5/5 (2)
- Big Brand StrategiesDokumen33 halamanBig Brand StrategiesvmahdiBelum ada peringkat
- Commodity Price Volatility: The Impact of Commodity Index TradersDokumen30 halamanCommodity Price Volatility: The Impact of Commodity Index Tradersincrediblemind171285Belum ada peringkat
- Plugin-Modeling Case StudyDokumen2 halamanPlugin-Modeling Case StudyAnkur GoyalBelum ada peringkat
- Commodity InvestDokumen50 halamanCommodity InvestvmahdiBelum ada peringkat
- Neuro StrategyDokumen16 halamanNeuro StrategyvmahdiBelum ada peringkat