Anda mungkin juga menyukai
- One Dimensional Arrays in C# (34Dokumen8 halamanOne Dimensional Arrays in C# (34EdrianCliffDelPilarBelum ada peringkat
- INFO 136 Session 2 SlidesDokumen20 halamanINFO 136 Session 2 SlidesClassic KachereBelum ada peringkat
- Bucket Sort, Radix Sort and Counting SortDokumen9 halamanBucket Sort, Radix Sort and Counting SortZoya AmaanBelum ada peringkat
- Array - 13 - 7 - 22Dokumen40 halamanArray - 13 - 7 - 22Safalya PanBelum ada peringkat
- Week 4.0 - ArrayListVector PDFDokumen37 halamanWeek 4.0 - ArrayListVector PDFJillian Callo SaldoBelum ada peringkat
- 6 Arrays.Dokumen8 halaman6 Arrays.ApoyyyBelum ada peringkat
- Data Structures Using C++ RakeshDokumen7 halamanData Structures Using C++ RakeshRakesh KumarBelum ada peringkat
- Arrays: Int New IntDokumen3 halamanArrays: Int New IntHimraj BachooBelum ada peringkat
- ArrayDokumen10 halamanArrayrohitthebestplayerBelum ada peringkat
- Counting Sort - GoodDokumen8 halamanCounting Sort - Goodyt peekBelum ada peringkat
- Introduction to ArraysDokumen38 halamanIntroduction to ArraysTanishq SinghalBelum ada peringkat
- Bucket Sort AlgorithmDokumen4 halamanBucket Sort AlgorithmSUCHARIKA MAHATBelum ada peringkat
- Unit 2 ArrayDokumen38 halamanUnit 2 ArrayParshotam PalBelum ada peringkat
- Chapter 2 Array, Function and StringDokumen20 halamanChapter 2 Array, Function and StringdamayantiBelum ada peringkat
- Declaration and Allocation of Memory For Arrays: Arrays: What's An Array?Dokumen6 halamanDeclaration and Allocation of Memory For Arrays: Arrays: What's An Array?giri_772Belum ada peringkat
- Q7) Write A C++ Program Using Types of Sorting.: 1. Bubble Sort 2. Insertion SortDokumen19 halamanQ7) Write A C++ Program Using Types of Sorting.: 1. Bubble Sort 2. Insertion SortAyush JadhavBelum ada peringkat
- Unit-3: ArraysDokumen36 halamanUnit-3: ArraysChinnari ChinnuBelum ada peringkat
- Unit-2 ArraysDokumen22 halamanUnit-2 Arraysmanvenderapathak165Belum ada peringkat
- Module3 Chapter1Dokumen27 halamanModule3 Chapter1padmBelum ada peringkat
- Chapter Six: Introduction To Arrays, String and PointersDokumen44 halamanChapter Six: Introduction To Arrays, String and PointerslalisaBelum ada peringkat
- ArrayDokumen172 halamanArrayMahh AngleBelum ada peringkat
- Dsa-Unit 2Dokumen42 halamanDsa-Unit 2devisht nayyarBelum ada peringkat
- Data Structures and Algorithms ArraysDokumen53 halamanData Structures and Algorithms ArraysSafder Khan BabarBelum ada peringkat
- Bucket Sort AlgorithmDokumen8 halamanBucket Sort Algorithmkarthik gundaBelum ada peringkat
- All DS Questions GEEKYDokumen255 halamanAll DS Questions GEEKYPawan KumarBelum ada peringkat
- C Unit 3Dokumen21 halamanC Unit 3mallajasmitha7Belum ada peringkat
- ArrayListDokumen12 halamanArrayListVISHNU SHANKAR SINGHBelum ada peringkat
- 1.2 ArrayDokumen53 halaman1.2 ArrayVivek PandeyBelum ada peringkat
- Python ArraysDokumen18 halamanPython ArraysAZM academyBelum ada peringkat
- ArrayListDokumen11 halamanArrayListSaiBelum ada peringkat
- Lab04 ArraysDokumen7 halamanLab04 ArraysVăn Hiếu TrầnBelum ada peringkat
- Basic Algorithms Explained in PseudocodeDokumen4 halamanBasic Algorithms Explained in PseudocodeSofi ArdhanBelum ada peringkat
- Ho 49 Array ListDokumen6 halamanHo 49 Array ListBapudayroBelum ada peringkat
- Pascal - ArraysDokumen3 halamanPascal - ArraysAndrewBelum ada peringkat
- 6 - ArraysDokumen40 halaman6 - ArraysHend TalafhaBelum ada peringkat
- Main PDF Lesson 2Dokumen27 halamanMain PDF Lesson 2onecarloscruz111Belum ada peringkat
- Chapter FourarrayprintedDokumen13 halamanChapter Fourarrayprintedhiwot kebedeBelum ada peringkat
- CollectionsDokumen6 halamanCollectionsiamsonalBelum ada peringkat
- Dsa Unit II NotesDokumen26 halamanDsa Unit II NotesKadam SupriyaBelum ada peringkat
- 5 ArraysDokumen11 halaman5 ArraysDominador PanolinBelum ada peringkat
- Lab04 ArraysDokumen6 halamanLab04 ArraysT CBelum ada peringkat
- Java Collections - List Set Map: BoxingDokumen11 halamanJava Collections - List Set Map: BoxingJunior Klinsman Diaz VallejosBelum ada peringkat
- Collections List Set MapDokumen9 halamanCollections List Set Mapapi-3698654Belum ada peringkat
- Java - The Vector Class: Difference Between Array and VectorDokumen5 halamanJava - The Vector Class: Difference Between Array and VectorMeetendra SinghBelum ada peringkat
- Java Collection Framework: ArrayList, HashTable, HashMap, HashSet, LinkedListDokumen11 halamanJava Collection Framework: ArrayList, HashTable, HashMap, HashSet, LinkedListIvonne MelendezBelum ada peringkat
- Sorted Array To Balanced BSTDokumen10 halamanSorted Array To Balanced BSTsandymcanBelum ada peringkat
- Array Fundamentals ExplainedDokumen13 halamanArray Fundamentals ExplainedrajanikanthBelum ada peringkat
- Basic Operations of ArrayDokumen40 halamanBasic Operations of ArrayArunachalam SelvaBelum ada peringkat
- ArraypptDokumen30 halamanArraypptkratikaBelum ada peringkat
- Unit 4: CollectionDokumen11 halamanUnit 4: CollectionpawasBelum ada peringkat
- Q, 6 Part ADokumen4 halamanQ, 6 Part Agulzar ahmadBelum ada peringkat
- Programming in Java: Topic: ArraylistDokumen11 halamanProgramming in Java: Topic: ArraylistAman ChaudharyBelum ada peringkat
- Lab04 ArraysDokumen6 halamanLab04 ArraysHồ NamBelum ada peringkat
- C++ Plus Data Structures Chapter on Sorting and Searching AlgorithmsDokumen79 halamanC++ Plus Data Structures Chapter on Sorting and Searching AlgorithmsArial96Belum ada peringkat
- Chapter 5Dokumen48 halamanChapter 5mehari kirosBelum ada peringkat
- Data StructuresDokumen12 halamanData StructureswalneBelum ada peringkat
- Declaring An Array Variable in JavaDokumen19 halamanDeclaring An Array Variable in JavaRicard AltamirBelum ada peringkat
- ALGO COMPLEXITY MODULE 3 Lesson 5 and 6Dokumen6 halamanALGO COMPLEXITY MODULE 3 Lesson 5 and 6cil dacaymatBelum ada peringkat
- Sorting, Searching, and The ComplexityDokumen41 halamanSorting, Searching, and The ComplexityEva UliaBelum ada peringkat
- RT32043042016 PDFDokumen8 halamanRT32043042016 PDFHARIKRISHNA PONNAMBelum ada peringkat
- Algorithms Illuminated: Part 3: Greedy Algorithms and Dynamic Programming Tim RoughgardenDokumen43 halamanAlgorithms Illuminated: Part 3: Greedy Algorithms and Dynamic Programming Tim RoughgardenMaxITDBelum ada peringkat
- Graphing Linear Inequalities Practice WorksheetDokumen1 halamanGraphing Linear Inequalities Practice WorksheetRusherBelum ada peringkat
- Unit II: Computer ArithmeticDokumen23 halamanUnit II: Computer ArithmeticMeenakshi PatelBelum ada peringkat
- A Hyperparameter Optimization For Galaxy ClassificationDokumen14 halamanA Hyperparameter Optimization For Galaxy Classification胡浩Belum ada peringkat
- Travelling Salesman ProblemDokumen27 halamanTravelling Salesman ProblemAdeel DurraniBelum ada peringkat
- Reinforcement Learning: 1 Updated Lecture Slides of Machine Learning Textbook, C Tom M. Mitchell, Mcgraw Hill, 1997Dokumen20 halamanReinforcement Learning: 1 Updated Lecture Slides of Machine Learning Textbook, C Tom M. Mitchell, Mcgraw Hill, 1997Rıfat ÇakırBelum ada peringkat
- Ee6403 DTSSP Even QB PDFDokumen51 halamanEe6403 DTSSP Even QB PDFPoorni JayaramanBelum ada peringkat
- Non-Parametric Spectrum Estimation (Chapter 8.2) : Statistical Digtal Signal Processing (EE4C03)Dokumen35 halamanNon-Parametric Spectrum Estimation (Chapter 8.2) : Statistical Digtal Signal Processing (EE4C03)NoahArayaBelum ada peringkat
- ML Important TopicDokumen13 halamanML Important TopicYt FanfestBelum ada peringkat
- Keys stored in chained hash table questionsDokumen11 halamanKeys stored in chained hash table questionsHarshit SinhaBelum ada peringkat
- Multilayer Perceptron PDFDokumen5 halamanMultilayer Perceptron PDFAquacypressBelum ada peringkat
- Chapter 8 - HeapsDokumen41 halamanChapter 8 - HeapsNguyễn Thanh LinhBelum ada peringkat
- Lecture 4Dokumen75 halamanLecture 4abdala sabryBelum ada peringkat
- Significant FiguesDokumen12 halamanSignificant FiguesShravani RautBelum ada peringkat
- A Novel DOA Estimation Method For Wideband Sources Based On Fuzzy SystemsDokumen9 halamanA Novel DOA Estimation Method For Wideband Sources Based On Fuzzy SystemsOugraz hassanBelum ada peringkat
- Assignment#2 Image ProcessingDokumen5 halamanAssignment#2 Image Processingpradeep GBelum ada peringkat
- Digital Signal Processing - S. Salivahanan, A. Vallavaraj and C. GnanapriyaDokumen68 halamanDigital Signal Processing - S. Salivahanan, A. Vallavaraj and C. GnanapriyaMallik KglBelum ada peringkat
- Fast Fourier TransformDokumen10 halamanFast Fourier TransformAnonymous sDiOXHwPPjBelum ada peringkat
- Optimize Assignment Problem LPP Hungarian MethodDokumen32 halamanOptimize Assignment Problem LPP Hungarian MethodHritika Reddy100% (1)
- Top 50 DSA - Cantilever Labs - (Toolkit 4)Dokumen18 halamanTop 50 DSA - Cantilever Labs - (Toolkit 4)Pragya KumariBelum ada peringkat
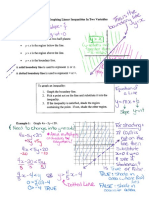
- 6.1 Graphing Linear Inequalities in Two Variables PDFDokumen4 halaman6.1 Graphing Linear Inequalities in Two Variables PDFcandelanibalBelum ada peringkat
- Speech Enhancement Using LPC Analysis-A ReviewDokumen6 halamanSpeech Enhancement Using LPC Analysis-A ReviewInternational Journal of Application or Innovation in Engineering & ManagementBelum ada peringkat
- Global Convergence of Trust-Region Algorithms For Convex Constrained Minimization Without DerivativesDokumen7 halamanGlobal Convergence of Trust-Region Algorithms For Convex Constrained Minimization Without DerivativesEmerson ButynBelum ada peringkat
- MCQ DC PPT 5Dokumen44 halamanMCQ DC PPT 5Shayaan PappathiBelum ada peringkat
- Asymptotic Notation PDFDokumen22 halamanAsymptotic Notation PDFRohulhuda AfghanBelum ada peringkat
- Credit Card Checker: Article About Setting Up A Text Editor For Web Development Article On Installing Node DownloadDokumen4 halamanCredit Card Checker: Article About Setting Up A Text Editor For Web Development Article On Installing Node DownloadKvaserickBelum ada peringkat
- Numerical ODE Solutions Methods for Engineering ProblemsDokumen2 halamanNumerical ODE Solutions Methods for Engineering ProblemsPrashant KulkarniBelum ada peringkat
- Planning Problem StripsDokumen16 halamanPlanning Problem StripsRaghu SomuBelum ada peringkat
- Adaptive Channel Equalization For NonlinearChannels Using Signed Regressor FLANNDokumen5 halamanAdaptive Channel Equalization For NonlinearChannels Using Signed Regressor FLANNIDESBelum ada peringkat