Arm Cache
Diunggah oleh
Loriana SanabriaDeskripsi Asli:
Hak Cipta
Format Tersedia
Bagikan dokumen Ini
Apakah menurut Anda dokumen ini bermanfaat?
Apakah konten ini tidak pantas?
Laporkan Dokumen IniHak Cipta:
Format Tersedia
Arm Cache
Diunggah oleh
Loriana SanabriaHak Cipta:
Format Tersedia
Datorarkitektur Fö 2 - 1 Datorarkitektur Fö 2 - 2
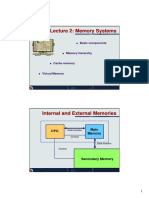
Components of the Memory System
The Memory System
• Main memory: fast, random access, expensive,
located close (but not inside) the CPU.
Is used to store program and data which are
1. Components of the Memory System
currently manipulated by the CPU.
2. The Memory Hierarchy
3. Cache Memories
• Secondary memory: slow, cheap, direct access,
4. Cache Organization located remotely from the CPU.
5. Replacement Algorithms
6. Write Strategies
7. Virtual Memory
Petru Eles, IDA, LiTH Petru Eles, IDA, LiTH
Datorarkitektur Fö 2 - 3 Datorarkitektur Fö 2 - 4
Problems with the Memory System A Solution
What do we need?
We need memory to fit very large programs and to It is possible to build a composite memory system
work at a speed comparable to that of the which combines a small, fast memory and a large
microprocessors. slow main memory and which behaves (most of the
time) like a large fast memory.
Main problem:
- microprocessors are working at a very high rate The two level principle above can be extended into a
and they need large memories; hierarchy of many levels including the secondary
memory (disk store).
- memories are much slower than microproces-
sors;
The effectiveness of such a memory hierarchy is based
Facts: on property of programs called the principle of locality
(see slide 10).
- the larger a memory, the slower it is;
- the faster the memory, the greater the cost/bit.
Petru Eles, IDA, LiTH Petru Eles, IDA, LiTH
Datorarkitektur Fö 2 - 5 Datorarkitektur Fö 2 - 6
The Memory Hierarchy The Memory Hierarchy (cont’d)
Some typical characteristics:
increasing capacity
1. Processor registers:
increasing access time
- 32 registers of 32 bits each = 128 bytes
- access time = few nanoseconds
increasing cost/bit
Register
Cache 2. On-chip cache memory:
- capacity = 8 to 32 Kbytes
- access time = ~10 nanoseconds
Main memory
3. Off-chip cache memory:
Magnetic Disk - capacity = few hundred Kbytes
- access time = tens of nanoseconds
Magnetic Tape & Optical Disk
4. Main memory:
- capacity = hundreds of Mbytes
- access time = ~100 nanoseconds
5. Hard disk:
- capacity = tens of Gbytes
- access time = tens of milliseconds
Petru Eles, IDA, LiTH Petru Eles, IDA, LiTH
Datorarkitektur Fö 2 - 7 Datorarkitektur Fö 2 - 8
The Memory Hierarchy (cont’d) Cache Memory
• A cache memory is a small, very fast memory that
retains copies of recently used information from
The key to the success of a memory hierarchy is if data main memory. It operates transparently to the
and instructions can be distributed across the memory programmer, automatically deciding which values
so that most of the time they are available, when needed, to keep and which to overwrite.
on the top levels of the hierarchy.
• The data which is held in the registers is under the processor memory
direct control of the compiler or of the assembler
programmer. registers
instructions
• The contents of the other levels of the hierarchy are
managed automatically:
- migration of data/instructions to and from address instructions
caches is performed under hardware control; and data
- migration between main memory and backup
copies of address
store is controlled by the operating system (with data
hardware support). instructions
copies
of data
instructions
cache and data
Petru Eles, IDA, LiTH Petru Eles, IDA, LiTH
Datorarkitektur Fö 2 - 9 Datorarkitektur Fö 2 - 10
Cache Memory (cont’d) Cache Memory (cont’d)
• Cache space (~KBytes) is much smaller than main
• The processor operates at its high clock rate only memory (~MBytes);
when the memory items it requires are held in the
cache.
Items have to be placed in the cache so that they
are available there when (and possibly only when)
The overall system performance depends strongly they are needed.
on the proportion of the memory accesses which
can be satisfied by the cache
• How can this work?
• An access to an item which is in the cache: hit
The answer is: locality
An access to an item which is not in the cache: miss.
During execution of a program, memory references
The proportion of all memory accesses that are by the processor, for both instructions and data,
satisfied by the cache: hit rate tend to cluster: once an area of the program is
entered, there are repeated references to a small
The proportion of all memory accesses that are not set of instructions (loop, subroutine) and data
satisfied by the cache: miss rate (components of a data structure, local variables or
parameters on the stack).
• The miss rate of a well-designed cache: few % Temporal locality (locality in time): If an item is
referenced, it will tend to be referenced again soon.
Spacial locality (locality in space): If an item is
referenced, items whose addresses are close by
will tend to be referenced soon.
Petru Eles, IDA, LiTH Petru Eles, IDA, LiTH
Datorarkitektur Fö 2 - 11 Datorarkitektur Fö 2 - 12
Cache Memory (cont’d) Separate Data and Instruction Caches
Problems concerning cache memories: • The figure on slide 8 shows an architecture with a
unified instruction and data cache.
• It is common also to split the cache into one dedi-
cated to instructions and one dedicated to data.
• How many caches?
instruction memory
• How to determine at a read if we have a miss or hit? cache
address
• If there is a miss and there is no place for a new slot copies of
in the cache which information should be replaced? instructions
instructions
instructions
• How to preserve consistency between cache and
main memory at write? address instructions
processor
registers
address data data
address
copies
of data
data
data cache
Petru Eles, IDA, LiTH Petru Eles, IDA, LiTH
Datorarkitektur Fö 2 - 13 Datorarkitektur Fö 2 - 14
Cache Organization
Separate Data and Instruction Caches (cont’d) Example:
• a cache of 64 Kbytes
• data transfer between cache and main memory is
in blocks of 4 bytes;
• Advantages of unified caches: we say the cache is organized in lines of 4 bytes;
- they are able to better balance the load be- • a main memory of 16 Mbytes; each byte is
tween instruction and data fetches depending addressable by a 24-bit address (224=16M)
on the dynamics of the program execution;
- design and implementation are cheaper.
- the cache consists of 214 (16K) lines
• Advantages of split caches (Harvard Architectures) - the main memory consists of 222 (4M) blocks
- competition for the cache between instruction
processing and execution units is eliminated ⇒
instruction fetch can proceed in parallel with
Questions:
memory access from the execution unit.
- when we bring a block from main memory into
the cache where (in which line) do we put it?
- when we look for the content of a certain mem-
ory address
- in which cache line do we look for it?
- how do we know if we have found the right
information (hit) or not (miss)?
Petru Eles, IDA, LiTH Petru Eles, IDA, LiTH
Datorarkitektur Fö 2 - 15 Datorarkitektur Fö 2 - 16
Direct Mapping
Direct Mapping (cont’d)
8bit 14bit 2bit
memory • A memory block is mapped into a unique cache
4bytes line, depending on the memory address of the
Block 0 respective block.
cache Block 1
8bit 4bytes • A memory address is considered to be composed
Line 0 of three fields:
Line 1 1. the least significant bits (2 in our example)
identify the byte within the block;
2. the rest of the address (22 bits in our example)
identify the block in main memory;
Line 214-1 Block 222-1 for the cache logic, this part is interpreted as
tag two fields:
2a. the least significant bits (14 in our exam-
cmp ple) specify the cache line;
2b. the most significant bits (8 in our exam-
hit miss ple) represent the tag, which is stored in
if hit
if miss the cache together with the line.
• Tags are stored in the cache in order to distinguish
• If we had a miss, the block will be placed in the among blocks which fit into the same cache line.
cache line which corresponds to the 14 bits field in
the memory address of the respective block:
8bit 14bit
Petru Eles, IDA, LiTH Petru Eles, IDA, LiTH
Datorarkitektur Fö 2 - 17 Datorarkitektur Fö 2 - 18
Direct Mapping (cont’d) Set Associative Mapping
Advantages: Two-way set associative cache
• simple and cheap; 9bit 13bit 2bit
• the tag field is short; only those bits have to be
stored which are not used to address the cache memory
(compare with the following approaches); 4bytes
• access is very fast. Block 0
cache Block 1
9bit 4bytes
Set 0
Disadvantage:
• a given block fits into a fixed cache location ⇒ a
given cache line will be replaced whenever there is Block 222-1
a reference to another memory block which fits to Set 213-1
the same line, regardless what the status of the tag
other cache lines is.
cmp
if miss
This can produce a low hit ratio, even if only a very if hit
small part of the cache is effectively used. miss hit
• If we had a miss, the block will be placed in one of
the two cache lines belonging to that set which cor-
responds to the 13 bits field in the memory address.
The replacement algorithm decides which line to
use.
Petru Eles, IDA, LiTH Petru Eles, IDA, LiTH
Datorarkitektur Fö 2 - 19 Datorarkitektur Fö 2 - 20
Set Associative Mapping (cont’d) Set Associative Mapping (cont’d)
• A memory block is mapped into any of the lines of a • Set associative mapping keeps most of the
set. The set is determined by the memory address, advantages of direct mapping:
but the line inside the set can be any one. - short tag field
- fast access
• If a block has to be placed in the cache the - relatively simple
particular line of the set will be determined
according to a replacement algorithm.
• Set associative mapping tries to eliminate the main
shortcoming of direct mapping; a certain flexibility is
• The memory address is interpreted as three fields given concerning the line to be replaced when a
by the cache logic, similar to direct mapping. new block is read into the cache.
However, a smaller number of bits (13 in our
example) are used to identify the set of lines in the
cache; correspondingly, the tag field will be larger • Cache hardware is more complex for set
(9 bits in our example). associative mapping than for direct mapping.
• Several tags (corresponding to all lines in the set)
have to be checked in order to determine if we have • In practice 2 and 4-way set associative mapping are
a hit or miss. If we have a hit, the cache logic finally used with very good results. Larger sets do not pro-
points to the actual line in the cache. duce further significant performance improvement.
• The number of lines in a set is determined by the • if a set consists of a single line ⇒ direct mapping;
designer;
2 lines/set: two-way set associative mapping If there is one single set consisting of all lines ⇒
4 lines/set: four-way set associative mapping associative mapping.
Petru Eles, IDA, LiTH Petru Eles, IDA, LiTH
Datorarkitektur Fö 2 - 21 Datorarkitektur Fö 2 - 22
Associative Mapping Associative Mapping (cont’d)
• A memory block can be mapped to any cache line.
• If a block has to be placed in the cache the
22 bit 2bit particular line will be determined according to a
replacement algorithm.
memory
4bytes • The memory address is interpreted as two fields by
Bl. 0 the cache logic.
cache Bl. 1 The lest significant bits (2 in our example) identify
4bytes the byte within the block;
22 bit All the rest of the address (22 bits in our example)
Line 0 is interpreted by the cache logic as a tag.
Line 1
• All tags, corresponding to every line in the cache
memory, have to be checked in order to determine
Line 214-1 Bl. 222-1 if we have a hit or miss. If we have a hit, the cache
tag logic finally points to the actual line in the cache.
The cache line is retrieved based on a portion of its
cmp content (the tag field) rather than its address. Such
a memory structure is called associative memory.
if hit
miss hit if miss
• If we had a miss, the block will be placed in one of
the 214 cache lines. The replacement algorithm
decides which line to use.
Petru Eles, IDA, LiTH Petru Eles, IDA, LiTH
Datorarkitektur Fö 2 - 23 Datorarkitektur Fö 2 - 24
Replacement Algorithms
Associative Mapping (cont’d)
When a new block is to be placed into the cache, the
Advantages: block stored in one of the cache lines has to be replaced.
• associative mapping provides the highest flexibility
concerning the line to be replaced when a new - With direct mapping there is no choice.
block is read into the cache.
- With associative or set-associative mapping a replace-
ment algorithm is needed in order to determine which
Disadvantages: block to replace (and, implicitly, in which cache line to
place the block);
• complex • with set-associative mapping, the candidate lines
• the tag field is long are those in the selected set;
• fast access can be achieved only using high • with associative mapping, all lines of the cache are
potential candidates;
performance associative memories for the cache,
which is difficult and expansive.
Petru Eles, IDA, LiTH Petru Eles, IDA, LiTH
Datorarkitektur Fö 2 - 25 Datorarkitektur Fö 2 - 26
Replacement Algorithms (cont’d)
Replacement Algorithms (cont’d)
• Random replacement:
One of the candidate lines is selected
randomly.
• Replacement algorithms for cache management
have to be implemented in hardware in order to be
All the other policies are based on information effective.
concerning the usage history of the blocks in the cache.
• LRU is the most efficient: relatively simple to
implement and good results.
• Least recently used (LRU):
The candidate line is selected which holds • FIFO is simple to implement.
the block that has been in the cache the • Random replacement is the simplest to implement
longest without being referenced. and results are surprisingly good.
• First-in-first-out (FIFO):
The candidate line is selected which holds
the block that has been in the cache the
longest.
• Least frequently used (LFU):
The candidate line is selected which holds
the block that has got the fewest references.
Petru Eles, IDA, LiTH Petru Eles, IDA, LiTH
Datorarkitektur Fö 2 - 27 Datorarkitektur Fö 2 - 28
Write Strategies
Write Strategies (cont’d)
The problem: • Write-through with buffered write
How to keep cache content and the content of main The same as write-through, but instead of slowing
memory consistent without losing too much the processor down by writing directly to main
performance? memory, the write address and data are stored in a
high-speed write buffer; the write buffer transfers
Problems arise when a write is issued to a memory data to main memory while the processor continues
address, and the content of the respective address it’s task.
is potentially changed.
higher speed, more complex hardware
• Copy-back
Write operations update only the cache memory
• Write-through which is not kept coherent with main memory;
All write operations are passed to main memory; if cache lines have to remember if they have been
the addressed location is currently hold in the updated; if such a line is replaced from the cache,
cache, the cache is updated so that it is coherent its content has to be copied back to memory.
with the main memory.
good performance (usually several writes are
For writes, the processor always slows down to performed on a cache line before it is replaced and
main memory speed. has to be copied into main memory), complex
hardware
Cache coherence problems are very complex and
difficult to solve in multiprocessor systems.
Petru Eles, IDA, LiTH Petru Eles, IDA, LiTH
Datorarkitektur Fö 2 - 29 Datorarkitektur Fö 2 - 30
Some Cache Architectures
Some Architectures (cont’d)
Intel 80486
- a single on-chip cache of 8 Kbytes
- line size: 16 bytes PowerPC 604
- 4-way set associative organization - two on-chip caches, for data and instructions
- each cache: 16 Kbytes
Pentium - line size: 32 bytes
- two on-chip caches, for data and instructions. - 4-way set associative organization
- each cache: 8 Kbytes
- line size: 32 bytes (64 bytes in Pentium 4)
- 2-way set associative organization PowerPC 620
(4-way in Pentium 4)
- two on-chip caches, for data and instructions
- each cache: 32 Kbytes
- line size: 64 bytes
PowerPC 601
- 8-way set associative organization
- a single on-chip cache of 32 Kbytes
- line size: 32 bytes
- 8-way set associative organization
PowerPC 603
- two on-chip caches, for data and instructions
- each cache: 8 Kbytes
- line size: 32 bytes
- 2-way set associative organization
(simpler cache organization than the 601 but
stronger processor)
Petru Eles, IDA, LiTH Petru Eles, IDA, LiTH
Datorarkitektur Fö 2 - 31 Datorarkitektur Fö 2 - 32
Pentium 4 Cache Organization Pentium 4 Cache Organization (cont’d)
• L1 data cache:
16KB, line size: 64 bytes, 4-way set associative.
System Bus/External Memory Copy-back policy
• The Pentium 4 L1 instruction cache (150 KB) is
often called trace cache.
Execution L1 instruction Instruction
control cache (150KB) fetch/decode - The Pentium 4 fetches groups of x86 instruc-
tions from the L2 cache, decodes them into
strings of microoperations (traces), and stores
L3 cache the traces into the L1 instruction cache.
(1MB) - The instructions in the cache are already de-
Integer & FP register files coded and, for execution, they only are fetched
from the cache. Thus, decoding is done only
once, even if the instruction is executed several
times (e.g. in loops).
Functional units - The fetch unit also preforms address calcula-
(ALUs, Load&Store units) L2 cache tion and branch prediction when constructing
(512KB) the traces to be stored in the cache (See Fö 4,
slides 3 and 8).
L1 data cache (16KB) • L2 cache:
512 KB, line size: 128 bytes, 8-way set associative.
• L3 cache:
1 MB, line size: 128 bytes, 8-way set associative.
• The L2 and L3 cache are unified instruction/data
caches.
• Instruction/data are fetched from external main
memory only if absent from L1, L2, and L3 cache.
Petru Eles, IDA, LiTH Petru Eles, IDA, LiTH
Datorarkitektur Fö 2 - 33 Datorarkitektur Fö 2 - 34
ARM Cache Organization Virtual memory
• ARM3 and ARM 6 had a 4KB unified cache. The address space needed and seen by programs is
• ARM 7 has a 8 KB unified cache. usually much larger than the available main memory.
• Starting with ARM9 there are separate data/instr.
caches:
- ARM9, ARM10, ARM11, Cortex: up to Only one part of the program fits into main memory; the
128/128KB instruction and data cache. rest is stored on secondary memory (hard disk).
- StrongARM: 16/16KB instruction and data
cache. • In order to be executed or data to be accessed, a
- Xscale: 32/32KB instruction and data cache. certain segment of the program has to be first
loaded into main memory; in this case it has to
replace another segment already in memory.
• Line size: 8 (32bit) words,
except ARM7 and StrongArm with 4 words.
• Movement of programs and data, between main
memory and secondary storage, is performed
• Set associative:
automatically by the operating system. These
- 4-way: ARM7, ARM9E, ARM10EJ-S, ARM11 techniques are called virtual-memory techniques.
- 64-way: ARM9T, ARM10E
- 32-way: StrongARM, Xscale • The binary address issued by the processor is a
- various options: Cortex virtual (logical) address; it considers a virtual
address space, much larger than the physical one
available in main memory.
• With the Cortex, an L2 internal cache is introduced
• Write strategy: write through with buffered write
Petru Eles, IDA, LiTH Petru Eles, IDA, LiTH
Datorarkitektur Fö 2 - 35 Datorarkitektur Fö 2 - 36
Virtual memory (cont’d) Virtual Memory Organization - Demand Paging
Processor
• The virtual programme space (instructions + data)
data/instructions
virtual address is divided into equal, fixed-size chunks called pages.
• Physical main memory is organized as a sequence
MMU of frames; a page can be assigned to an available
frame in order to be stored (page size = frame size).
physical address • The page is the basic unit of information which is
moved between main memory and disk by the
Cache virtual memory system.
physical address • Common page sizes are: 2 - 16Kbytes.
data/instructions
Main memory
Demand Paging
transfer if • The program consists of a large amount of pages
reference not in which are stored on disk; at any one time, only a
physical memory few pages have to be stored in main memory.
• The operating system is responsible for loading/
Disk replacing pages so that the number of page faults is
storage minimized.
• If a virtual address refers to a part of program or • We have a page fault when the CPU refers to a
data that is currently in the physical memory location in a page which is not in main memory; this
(cache, main memory), then the appropriate page has then to be loaded and, if there is no
location is accessed immediately using the available frame, it has to replace a page which
respective physical address; if this is not the case, previously was in memory.
the respective program/data has to be transferred
first from secondary memory.
• A special hardware unit, Memory Management Unit
(MMU), translates virtual addresses into physical ones.
Petru Eles, IDA, LiTH Petru Eles, IDA, LiTH
Datorarkitektur Fö 2 - 37 Datorarkitektur Fö 2 - 38
Demand Paging (cont’d) Address Translation
• Accessing a word in memory involves the
translation of a virtual address into a physical one:
- virtual address: page number + offset
- physical address: frame number + offset
• Address translation is performed by the MMU using
a page table.
pages
Example:
• Virtual memory space: 2 Gbytes
(31 address bits; 231 = 2 G)
frames in main • Physical memory space: 16 Mbytes (224=16M)
memory • Page length: 2Kbytes (211 = 2K)
pages on the disk
Total number of pages: 220 = 1M
Total number of frames: 213 = 8K
Petru Eles, IDA, LiTH Petru Eles, IDA, LiTH
Datorarkitektur Fö 2 - 39 Datorarkitektur Fö 2 - 40
Address Translation (cont’d) The Page Table
virtual address • The page table has one entry for each page of the
virtual memory space.
20bit 11bit
page nmbr. offset 13bit 11bit
• Each entry of the page table holds the address of
frame nr offset
the memory frame which stores the respective
physical address page, if that page is in main memory.
page table
Ctrl frame nr main memory
• Each entry of the page table also includes some
bits in mem. 2 Kbytes
control bits which describe the status of the page:
Entry 0 Frame 0 - whether the page is actually loaded into main
Entry 1 Frame 1 memory or not;
- if since the last loading the page has been
modified;
- information concerning the frequency of
access, etc.
Entry 220-1 Frame 213-1
If page fault
then OS is
activated in
order to load
missed page
Petru Eles, IDA, LiTH Petru Eles, IDA, LiTH
Datorarkitektur Fö 2 - 41 Datorarkitektur Fö 2 - 42
The Page Table (cont’d) Memory Reference with Virtual Memory and TLB
request access to
Problems: virtual address
- The page table is very large (number of pages Check TLB
in virtual memory space is very large).
- Access to the page table has to be very fast ⇒
the page table has to be stored in very fast
memory, on chip. Page table Yes
entry in (pages surely in
TLB? main memory)
No
Access page table
• A special cache is used for page table entries, (if entry not in
called translation lookaside buffer (TLB); it works in main memory, a
the same way as an ordinary memory cache and page fault is
produced and OS
contains those page table entries which have been loads missed part
most recently used. of the page table)
• The page table is often too large to be stored in
main memory. Virtual memory techniques are used
to store the page table itself ⇒ only part of the No
Page in
page table is stored in main memory at a given main
(page fault) memory?
moment.
OS activated:
- loads missed Yes
page into main update TLB
The page table itself is distributed along the memory;
memory hierarchy: - if memory is generate physical
- TLB (cache) full, replaces address
an "old" page;
- main memory
- updates page access cache
- disk table and, if miss,
main memory
Petru Eles, IDA, LiTH Petru Eles, IDA, LiTH
Datorarkitektur Fö 2 - 43 Datorarkitektur Fö 2 - 44
Page Replacement
Memory Reference with Virtual Memory and TLB • When a new page is loaded into main memory and
(cont’d) there is no free memory frame, an existing page
has to be replaced.
The decision on which page to replace is based on
the same speculations like those for replacement of
blocks in cache memory (see slide 24).
• Memory access is solved by hardware except the LRU strategy is often used to decide on which page
page fault sequence which is executed by the OS to replace.
software.
• The hardware unit which is responsible for • When the content of a page, which is loaded into
translation of a virtual address into a physical one is main memory, has been modified as result of a
the Memory Management Unit (MMU). write, it has to be written back on the disk after its
replacement.
One of the control bits in the page table is used in
order to signal that the page has been modified.
Petru Eles, IDA, LiTH Petru Eles, IDA, LiTH
Datorarkitektur Fö 2 - 45
Summary
• A memory system has to fit very large programs
and still to provide fast access.
• A hierarchical memory system can provide needed
performance, based on the locality of reference.
• Cache memory is an essential component of the
memory system; it can be a single cache or
organized as separate data and instruction caches.
• Cache memories can be organized with direct
mapping, set associative mapping, and associative
mapping
• When a new block is brought into the cache,
another one has to be replaced; in order to decide
on which one to replace different strategies can be
used: random, LRU, FIFO, LFU, etc.
• In order to keep the content of the cache coherent
with main memory, certain write strategies have to
be used: write-through, write-through with buffered
write, copy-back.
• The address space seen by programs is a virtual one
and is much larger than the available physical space.
• Demand paging is based on the idea that only a
part of the pages is in main memory at a certain
moment; the OS loads pages into memory when
needed.
• The MMU translates a virtual address into a
physical one; this is solved using the page table.
• The page table itself is distributed along the
memory hierarchy: TLB (cache), main memory, disk.
Petru Eles, IDA, LiTH
Anda mungkin juga menyukai
- 01 - Memory System PDFDokumen11 halaman01 - Memory System PDFRajesh cBelum ada peringkat
- Computer MemoryDokumen6 halamanComputer Memoryjolob61618Belum ada peringkat
- UNIT 3 Computer MemoryDokumen13 halamanUNIT 3 Computer MemoryRussel RosagaranBelum ada peringkat
- Memory Hierarchy Design and Its Characteristics - GeeksforGeeksDokumen1 halamanMemory Hierarchy Design and Its Characteristics - GeeksforGeeksshruti11091Belum ada peringkat
- Memory in Computer ArchitectureDokumen24 halamanMemory in Computer ArchitectureIshanviBelum ada peringkat
- Memory StructureDokumen15 halamanMemory StructureDlool ALmutawaBelum ada peringkat
- Lec2 PDFDokumen21 halamanLec2 PDFRabia ChaudharyBelum ada peringkat
- Lecture 7 Memory 2021Dokumen64 halamanLecture 7 Memory 2021KANZA AKRAMBelum ada peringkat
- Unit 1 The Memory System: Structure Page NosDokumen102 halamanUnit 1 The Memory System: Structure Page NosGurmeet SinghBelum ada peringkat
- Sistem & Arsitektur Komputer IF-5010 Kuliah#2Dokumen17 halamanSistem & Arsitektur Komputer IF-5010 Kuliah#2Hidayaturrahman HRBelum ada peringkat
- Memory Organization Memory Hierarchy 2.2.1Dokumen3 halamanMemory Organization Memory Hierarchy 2.2.1Arjun NainBelum ada peringkat
- Computer Architecture and Organization: Chapter ThreeDokumen26 halamanComputer Architecture and Organization: Chapter ThreeGebrie BeleteBelum ada peringkat
- Coa 2..2Dokumen42 halamanCoa 2..2Raman Ray 105Belum ada peringkat
- 1.2 Worksheet 1Dokumen5 halaman1.2 Worksheet 1Lin Latt Wai AlexaBelum ada peringkat
- Memory TrendsDokumen6 halamanMemory Trendsapi-3701346Belum ada peringkat
- Cache Memory ADokumen62 halamanCache Memory ARamiz KrasniqiBelum ada peringkat
- Computer Organization and Architecture: Chapter FiveDokumen23 halamanComputer Organization and Architecture: Chapter FiveZerihun BekeleBelum ada peringkat
- Computer Architecture 1: Memory SystemsDokumen14 halamanComputer Architecture 1: Memory SystemsAruna TurayBelum ada peringkat
- Unit 3 - COMPUTER MEMORYDokumen16 halamanUnit 3 - COMPUTER MEMORYmartinjrmwewaBelum ada peringkat
- UNIT 3 - Computer MemoryDokumen16 halamanUNIT 3 - Computer MemoryComputer100% (3)
- "Cache Memory" in (Microprocessor and Assembly Language) : Lecture-20Dokumen19 halaman"Cache Memory" in (Microprocessor and Assembly Language) : Lecture-20MUHAMMAD ABDULLAHBelum ada peringkat
- Memor y Architecture Chapter SixDokumen24 halamanMemor y Architecture Chapter SixbalalasBelum ada peringkat
- Memory Management: Fred Kuhns Department of Computer Science and Engineering Washington University in St. LouisDokumen34 halamanMemory Management: Fred Kuhns Department of Computer Science and Engineering Washington University in St. LouisMadhur shailesh Dwivedi100% (1)
- Memory CacheDokumen18 halamanMemory CacheFunsuk VangduBelum ada peringkat
- The Challenges of Measuring Persistent Memory Performance: Eduardo Berrocal, Keith OrsakDokumen19 halamanThe Challenges of Measuring Persistent Memory Performance: Eduardo Berrocal, Keith Orsak邱宇弟Belum ada peringkat
- Assignment-Operating System 5014533Dokumen2 halamanAssignment-Operating System 5014533عبدالرحمن يحي صلحBelum ada peringkat
- L1-Introduction To CDokumen48 halamanL1-Introduction To CDev KumarBelum ada peringkat
- Unit 2 Storage Organisation: 2.0 IntroductionDokumen27 halamanUnit 2 Storage Organisation: 2.0 IntroductionsadafmirzaBelum ada peringkat
- Memory Subsystem: Dr. Gayathri Sivakumar Assistant Professor (SG-I) School of Electronics VIT, ChennaiDokumen16 halamanMemory Subsystem: Dr. Gayathri Sivakumar Assistant Professor (SG-I) School of Electronics VIT, ChennaiNeel RavalBelum ada peringkat
- Data Storage HierarchyDokumen14 halamanData Storage HierarchyLogeswari GovindarajuBelum ada peringkat
- Chapter 2 - Computer OrganizationDokumen30 halamanChapter 2 - Computer Organizationadhasbdi2e98qy928eBelum ada peringkat
- Unit - 2Dokumen27 halamanUnit - 2spacpostBelum ada peringkat
- Memory Hierarchy Gilbert Ogechi University of Science and Technology Jaramogi Oginga Odinga Univeristy of Science and Technology 10/02/2019Dokumen3 halamanMemory Hierarchy Gilbert Ogechi University of Science and Technology Jaramogi Oginga Odinga Univeristy of Science and Technology 10/02/2019Gilbert OgechiBelum ada peringkat
- Week6 SlidesDokumen18 halamanWeek6 SlidesVansh JainBelum ada peringkat
- Week 2 - The Memory System and Instruction Set ArchitectureDokumen19 halamanWeek 2 - The Memory System and Instruction Set ArchitectureGame AccountBelum ada peringkat
- Co2 Ppt-Part2Dokumen38 halamanCo2 Ppt-Part2Pradeep TataBelum ada peringkat
- Memory (Unit-3) : 6.1 Main Memory, Secondary Memory and Backup MemoryDokumen8 halamanMemory (Unit-3) : 6.1 Main Memory, Secondary Memory and Backup MemoryvimalBelum ada peringkat
- Chapter 3 P1Dokumen57 halamanChapter 3 P1Phạm Tiến AnhBelum ada peringkat
- Memory Hierarchy Design and Its CharacteristicsDokumen3 halamanMemory Hierarchy Design and Its Characteristicsdilame bereketBelum ada peringkat
- Computer Hardware Review: ProcessorsDokumen8 halamanComputer Hardware Review: Processorsanggit julianingsihBelum ada peringkat
- Chapter 2 Memory HierachyDokumen8 halamanChapter 2 Memory HierachyMwaura NjugiBelum ada peringkat
- Computer CH 2Dokumen7 halamanComputer CH 2PISD DohaBelum ada peringkat
- What Is Memory HierarchyDokumen4 halamanWhat Is Memory HierarchyO Level Study AddaBelum ada peringkat
- Co2 Ppt-Part2Dokumen38 halamanCo2 Ppt-Part2SWAMI AYYAPPABelum ada peringkat
- Controller. This Is The Part of The System That, Well, Controls The Memory. ItDokumen3 halamanController. This Is The Part of The System That, Well, Controls The Memory. ItIsuru KasthurirathneBelum ada peringkat
- Looking Inside A Computer NotesDokumen2 halamanLooking Inside A Computer NotesMeileen Dela RosaBelum ada peringkat
- Computer Architecture: Memory HierarchyDokumen42 halamanComputer Architecture: Memory HierarchyElisée NdjabuBelum ada peringkat
- Components of The Memory SystemDokumen11 halamanComponents of The Memory Systemdeepthikompella9Belum ada peringkat
- Computer Memory: Rovelito I. NavarraDokumen26 halamanComputer Memory: Rovelito I. NavarraCelestial Manikan Cangayda-AndradaBelum ada peringkat
- Digital Design and Computer Architecture, 2: EditionDokumen87 halamanDigital Design and Computer Architecture, 2: EditionСергей КапустаBelum ada peringkat
- CS6461 - Computer Architecture Fall 2016 Morris Lancaster - Memory SystemsDokumen66 halamanCS6461 - Computer Architecture Fall 2016 Morris Lancaster - Memory Systems闫麟阁Belum ada peringkat
- Computer Organization and Architecture Chapter 7 Large and Fast ExploitingDokumen32 halamanComputer Organization and Architecture Chapter 7 Large and Fast Exploitingtazusamamiya2Belum ada peringkat
- Database Indexing and TuningDokumen168 halamanDatabase Indexing and TuningRenuja De CostaBelum ada peringkat
- MemoryDokumen125 halamanMemoryprjtBelum ada peringkat
- R4 Ookwb 2 C 3 U PDo HL NZrsDokumen15 halamanR4 Ookwb 2 C 3 U PDo HL NZrsShuvomoy rayBelum ada peringkat
- On Memory: By-Jesmin Akhter Lecturer, IIT, Jahangirnagar UniversityDokumen21 halamanOn Memory: By-Jesmin Akhter Lecturer, IIT, Jahangirnagar Universitymedgeek nmeBelum ada peringkat
- Chapter 3Dokumen16 halamanChapter 3fyza emyBelum ada peringkat
- 04 Cache Memory ComparcDokumen47 halaman04 Cache Memory ComparcMekonnen WubshetBelum ada peringkat
- Cache 1 54Dokumen54 halamanCache 1 54thk jainBelum ada peringkat
- PlayStation 2 Architecture: Architecture of Consoles: A Practical Analysis, #12Dari EverandPlayStation 2 Architecture: Architecture of Consoles: A Practical Analysis, #12Belum ada peringkat
- Engr. Maryam Khaliq M.SC (Hones) .Engineering: PersonalDokumen3 halamanEngr. Maryam Khaliq M.SC (Hones) .Engineering: PersonalMaryum KhaliqBelum ada peringkat
- Lab Exercise 2Dokumen3 halamanLab Exercise 2khairitkrBelum ada peringkat
- Cognos RS - Functions - 18Dokumen5 halamanCognos RS - Functions - 18Harry KonnectBelum ada peringkat
- FortiOS v400 Release NotesDokumen32 halamanFortiOS v400 Release NotesWho Am IBelum ada peringkat
- Bofan - PT502Dokumen18 halamanBofan - PT502Jaime Alejandro Gajardo QuirozBelum ada peringkat
- CEGP019671: Human Computer InteractionDokumen4 halamanCEGP019671: Human Computer InteractionDevika RankhambeBelum ada peringkat
- Hsi Ashimedic Ebook 062118Dokumen8 halamanHsi Ashimedic Ebook 062118Anthony DinicolantonioBelum ada peringkat
- Hpe Arcsight Esm STDokumen47 halamanHpe Arcsight Esm STHitesh RahangdaleBelum ada peringkat
- Facility ManagementDokumen3 halamanFacility ManagementMohamed Aboobucker Mohamed IrfanBelum ada peringkat
- Dirichlet Problem With SeriesDokumen4 halamanDirichlet Problem With SeriesDiegoBelum ada peringkat
- CS CH7 High Low Level LanguagesDokumen6 halamanCS CH7 High Low Level LanguagesGiga ChadBelum ada peringkat
- Linear Programming Models in ServicesDokumen14 halamanLinear Programming Models in ServicesHarsh GuptaBelum ada peringkat
- Crystal Report 8.5 For Visual - 89028Dokumen8 halamanCrystal Report 8.5 For Visual - 89028dsadsadBelum ada peringkat
- Lab - 1 - 2 - 6 Connecting Router LAN Interfaces (CISCO SYSTEMS)Dokumen2 halamanLab - 1 - 2 - 6 Connecting Router LAN Interfaces (CISCO SYSTEMS)Abu AsimBelum ada peringkat
- PP NVPAPI DeveloperGuideDokumen266 halamanPP NVPAPI DeveloperGuideflabbyfatnes5Belum ada peringkat
- Isodraft User Guide PDFDokumen137 halamanIsodraft User Guide PDFPolarogramaBelum ada peringkat
- O365 Online Archive Setting Retention PoliciesDokumen3 halamanO365 Online Archive Setting Retention PoliciesRaja ChinnaduraiBelum ada peringkat
- Change ManagementDokumen2 halamanChange ManagementJiNay ShAhBelum ada peringkat
- Maui Remote Control and Automation ManualDokumen402 halamanMaui Remote Control and Automation ManualLalit DaniBelum ada peringkat
- Cheat Sheet Hibernate Performance Tuning PDFDokumen6 halamanCheat Sheet Hibernate Performance Tuning PDFdanielisozaki100% (1)
- Assembly Programming PDFDokumen446 halamanAssembly Programming PDFPopescu Misu100% (4)
- Cse 1st Sem Result PDFDokumen3 halamanCse 1st Sem Result PDFrahulyadav957181Belum ada peringkat
- ID of PG-2nd Year Student For Scholarship-9th September 2013Dokumen18 halamanID of PG-2nd Year Student For Scholarship-9th September 2013nira365Belum ada peringkat
- Qualitative Data AnalysisDokumen12 halamanQualitative Data AnalysisHaneef MohamedBelum ada peringkat
- Action Plan ISO 45001Dokumen3 halamanAction Plan ISO 45001Ankur0% (1)
- Bridging The Gap Between Theory and Practice in Maintenance: D.N.P. (Pra) MURTHYDokumen50 halamanBridging The Gap Between Theory and Practice in Maintenance: D.N.P. (Pra) MURTHYDinesh Kumar MaliBelum ada peringkat
- 4th Quarter Tle 6Dokumen9 halaman4th Quarter Tle 6Jorry Pavo NepalBelum ada peringkat
- Coverage and Profiling For Real-Time Tiny KernelsDokumen6 halamanCoverage and Profiling For Real-Time Tiny Kernelsanusree_bhattacharjeBelum ada peringkat
- 2009 Ncta Technical Papers PDFDokumen250 halaman2009 Ncta Technical Papers PDFmohitkalraBelum ada peringkat
- Multicore Processor ReportDokumen19 halamanMulticore Processor ReportDilesh Kumar100% (1)