Anda mungkin juga menyukai
- Aula Matlab 2Dokumen81 halamanAula Matlab 2Analista Jeanka RojasBelum ada peringkat
- Power de Nitrato de SodioDokumen13 halamanPower de Nitrato de SodioDaniel CruzBelum ada peringkat
- 01la040030 - Nitrato de SodioDokumen2 halaman01la040030 - Nitrato de SodioManuel Linarez OcminBelum ada peringkat
- Weka AlgoritmosDokumen6 halamanWeka AlgoritmosjhymermartinezBelum ada peringkat
- Presentacion 2Dokumen20 halamanPresentacion 2WilliamsBorgesBelum ada peringkat
- Coaquira Rosas Marino Luis PDFDokumen184 halamanCoaquira Rosas Marino Luis PDFJuna DeivisBelum ada peringkat
- Graficar 3d MatlabDokumen42 halamanGraficar 3d Matlabdilor19Belum ada peringkat
- Selección de Método de MinadoDokumen25 halamanSelección de Método de MinadoJorge EnriquezBelum ada peringkat
- Ejemplo de Red Neural Con MatlabDokumen12 halamanEjemplo de Red Neural Con Matlabjavier_valdivia_42Belum ada peringkat
- Expo PervolDokumen22 halamanExpo PervolAntony AVBelum ada peringkat
- Aplicaciones de La Geometría Analítica en La VidaDokumen15 halamanAplicaciones de La Geometría Analítica en La VidaMarilenny M. GuzmánBelum ada peringkat
- Sesión 10 IzajeDokumen28 halamanSesión 10 IzajeSebastian Rodrigo Vilca GonzalesBelum ada peringkat
- Manual Bizagi StudioDokumen21 halamanManual Bizagi StudioCristian BacaBelum ada peringkat
- Weka PDFDokumen43 halamanWeka PDFCristian CortesBelum ada peringkat
- Pervol 2-TeDokumen8 halamanPervol 2-TeJorge Luis CJviba Vizarres BarrenacheaBelum ada peringkat
- Método de Cubicación Room and PillarDokumen5 halamanMétodo de Cubicación Room and PillarNiki GTBelum ada peringkat
- ppt12 Perceptron Multicapa Cont PDFDokumen16 halamanppt12 Perceptron Multicapa Cont PDFAnonymous 1dVLJSVhtrBelum ada peringkat
- Introducción Redes Neuronales ArtificialesMFMDokumen10 halamanIntroducción Redes Neuronales ArtificialesMFMJulio Montes de OcaBelum ada peringkat
- Patrones-Codigo de Colores (1) - para Planos GeologicosDokumen4 halamanPatrones-Codigo de Colores (1) - para Planos GeologicosCristian QuilicheBelum ada peringkat
- Trabajo de Investigacion de OperacionesDokumen10 halamanTrabajo de Investigacion de OperacionesAngel Ticona ArpiBelum ada peringkat
- Contactores de MembranaDokumen16 halamanContactores de MembranaMajo27Belum ada peringkat
- Analisis Multivariante Definicion Objetivos Tipos Variables - 2Dokumen13 halamanAnalisis Multivariante Definicion Objetivos Tipos Variables - 2Angeles Jiménez DuhartBelum ada peringkat
- Energia de ExploDokumen35 halamanEnergia de ExploAlex SxeBelum ada peringkat
- Anexo 4 - Planos Pampa San Miguel PDFDokumen29 halamanAnexo 4 - Planos Pampa San Miguel PDFEduardo CalizayaBelum ada peringkat
- Proced Remediacion LBDokumen16 halamanProced Remediacion LBMarisabel MaidanaBelum ada peringkat
- Seguridad en Minería SuperficialDokumen14 halamanSeguridad en Minería SuperficialSusy Serrano FlawersBelum ada peringkat
- Termoquímica de Los Explosivos AL-ANFODokumen3 halamanTermoquímica de Los Explosivos AL-ANFOAbdel Huaman MolinaBelum ada peringkat
- Balance de OxigenoDokumen15 halamanBalance de OxigenoHugo BanegasBelum ada peringkat
- Diseño y Construcción de Un Sistema de Mediciones Biomédicas para Un Laboratorio de ElectrofisiolDokumen198 halamanDiseño y Construcción de Un Sistema de Mediciones Biomédicas para Un Laboratorio de ElectrofisiolRomario RodriguezBelum ada peringkat
- Tipos de Dinamita FinalDokumen14 halamanTipos de Dinamita FinalGuiss BenavidesBelum ada peringkat
- Redes Neuronales PDFDokumen8 halamanRedes Neuronales PDFronny vcBelum ada peringkat
- E. FinalDokumen2 halamanE. FinalAntonio TineoBelum ada peringkat
- La DinamitaDokumen6 halamanLa DinamitaMacarena MBBelum ada peringkat
- La Eliminación de ParafinaDokumen2 halamanLa Eliminación de ParafinaAna GamasBelum ada peringkat
- Series de RazonesDokumen8 halamanSeries de RazonesMath Digital100% (1)
- Reputación EmpresarialDokumen2 halamanReputación EmpresarialChuchoJr martinezBelum ada peringkat
- Trabajo Final - Comercio - Exterior PDFDokumen25 halamanTrabajo Final - Comercio - Exterior PDFjohntarazona9422Belum ada peringkat
- Mantenimiento Mina Yauricocha CentrominDokumen47 halamanMantenimiento Mina Yauricocha Centrominslider100% (1)
- Histogramas en ExcelDokumen1 halamanHistogramas en ExcelVíctor González Fernández100% (1)
- SucamecDokumen21 halamanSucamecEtel Enriquez Buleje100% (2)
- Izaje 1Dokumen15 halamanIzaje 1Wilber PongoBelum ada peringkat
- Modulo de Ingenieria de ExplosivosDokumen45 halamanModulo de Ingenieria de ExplosivosFernando Terán ToledoBelum ada peringkat
- Estructuración e Integración de Una Red de TelemedicinaDokumen16 halamanEstructuración e Integración de Una Red de TelemedicinaNayath RodriguezBelum ada peringkat
- MATLAB Ejemplos de Gráficas en Dos y Tres Dimensiones MedianteDokumen13 halamanMATLAB Ejemplos de Gráficas en Dos y Tres Dimensiones MedianteLeo BurbanoBelum ada peringkat
- 4 PC Superficial Vicente PieroDokumen5 halaman4 PC Superficial Vicente Pieropiero vicente palaciosBelum ada peringkat
- Regresion e Interpolacion PDFDokumen16 halamanRegresion e Interpolacion PDFCami ElianaBelum ada peringkat
- Introducción A Octave Parte 2Dokumen5 halamanIntroducción A Octave Parte 2luis yoBelum ada peringkat
- INFORME 1-López Lazo Bruno-17190158Dokumen26 halamanINFORME 1-López Lazo Bruno-17190158BruNo LopezBelum ada peringkat
- Taylor For JavaDokumen72 halamanTaylor For Javaeric723Belum ada peringkat
- Interpolación PolinomialDokumen14 halamanInterpolación PolinomialLlocclla Ccasani GloriaBelum ada peringkat
- Trabajo No. 2 Parra - VeraDokumen26 halamanTrabajo No. 2 Parra - VeraDaniela VeraBelum ada peringkat
- Guia MatlabDokumen14 halamanGuia MatlabAnchonyBelum ada peringkat
- Trabajo Práctico 2 Algoritmos Con ScilabDokumen4 halamanTrabajo Práctico 2 Algoritmos Con ScilabAndres RaggiBelum ada peringkat
- Guía de Laboratorio 10 Metodos NumericosDokumen2 halamanGuía de Laboratorio 10 Metodos NumericosWalter CarvajalBelum ada peringkat
- Informe 1Dokumen32 halamanInforme 1CarlaMuñozPescoránBelum ada peringkat
- Metodo de MontecarloDokumen12 halamanMetodo de MontecarloYuki Mendoza ZaaBelum ada peringkat
- Gutierrez Ayala Diego 16190162 PRACTICA 1 - Procesamiento de Señales Periódicas y Funciones MatemáticasDokumen20 halamanGutierrez Ayala Diego 16190162 PRACTICA 1 - Procesamiento de Señales Periódicas y Funciones MatemáticasDiego Gutierrez AyalaBelum ada peringkat
- Laboratorio 2 Señales y SistemasDokumen19 halamanLaboratorio 2 Señales y SistemasDaniel ParraBelum ada peringkat
- L2 MeNuDokumen6 halamanL2 MeNuYurivilca Yurivilca GianmarcoBelum ada peringkat
- Geometric modeling in computer: Aided geometric designDari EverandGeometric modeling in computer: Aided geometric designBelum ada peringkat
- InterferometriaDokumen51 halamanInterferometriaAlejandro LizárragaBelum ada peringkat
- Cur Sode Ulti Board 9Dokumen45 halamanCur Sode Ulti Board 9urbano46190bisBelum ada peringkat
- Radiometría y FotometríaDokumen5 halamanRadiometría y Fotometría7779578Belum ada peringkat
- Cálculo de Engranajes CilíndricosDokumen65 halamanCálculo de Engranajes CilíndricosLeslie Colina - Yeye100% (1)
- Analísis de Situación - Control de CalidadDokumen11 halamanAnalísis de Situación - Control de CalidadAlejandro LizárragaBelum ada peringkat
- Práctica 2 Instrumentación Electrónica: Escalar Una SeñalDokumen7 halamanPráctica 2 Instrumentación Electrónica: Escalar Una SeñalAlejandro LizárragaBelum ada peringkat
- Tarea SimulaciónDokumen9 halamanTarea SimulaciónGrecia MaldonadoBelum ada peringkat
- 05 04 Diferencia Entre Herencia, Interface y Composición en JavaDokumen4 halaman05 04 Diferencia Entre Herencia, Interface y Composición en JavaJESUSBelum ada peringkat
- Teoría de Colas 2018Dokumen88 halamanTeoría de Colas 2018David LopezBelum ada peringkat
- Práctica Calificada 12Dokumen8 halamanPráctica Calificada 12Alex Caruajulca Tiglla100% (1)
- Examen 4Dokumen2 halamanExamen 4CINDY ESTEFANIA PESANTES PALMABelum ada peringkat
- Funciones de Distribución y Cuantil VANEDokumen2 halamanFunciones de Distribución y Cuantil VANEjonaBelum ada peringkat
- Riiaa 2018 Programa v11Dokumen5 halamanRiiaa 2018 Programa v11JaeN_ProgrammerBelum ada peringkat
- Tarea 2 Juan Chávez OrozcoDokumen7 halamanTarea 2 Juan Chávez OrozcoJuan Chavez OrozcoBelum ada peringkat
- Herencia y RelacionesDokumen78 halamanHerencia y RelacionesJULIAN EDUARDO CALLEJAS ERAZOBelum ada peringkat
- Tema 06Dokumen44 halamanTema 06Carlos FaundesBelum ada peringkat
- LR-Binomial Negativa PDFDokumen7 halamanLR-Binomial Negativa PDFFabrizio LópezBelum ada peringkat
- Prueba Chi Cuadrado x2Dokumen21 halamanPrueba Chi Cuadrado x2Ivan Felipe Erazo CeronBelum ada peringkat
- Formulario-De Modelos de ProbabilidadDokumen2 halamanFormulario-De Modelos de ProbabilidadEnrique EnriqueBelum ada peringkat
- Unidad 2 Fase 3 Automata de Pila 0910219Dokumen28 halamanUnidad 2 Fase 3 Automata de Pila 0910219YinethZMBelum ada peringkat
- Mpro2 U1 Ea V1 AnomDokumen18 halamanMpro2 U1 Ea V1 AnomAna Yansy Olarte MendozaBelum ada peringkat
- Listado de Actividades de Const.Dokumen30 halamanListado de Actividades de Const.MiriamBelum ada peringkat
- Trabajo 1 Estadistica Computacional PDFDokumen39 halamanTrabajo 1 Estadistica Computacional PDFFrancisco Calderón PozoBelum ada peringkat
- Practica N°3 Calculos para La Distribucion Normal Estadar (Z)Dokumen6 halamanPractica N°3 Calculos para La Distribucion Normal Estadar (Z)Ana Ysabel Guzman MercadoBelum ada peringkat
- Semana 04 Distribuciones Probabilidad Discreta2Dokumen38 halamanSemana 04 Distribuciones Probabilidad Discreta2Deivid ZambranoBelum ada peringkat
- Distribuciones ContinuasDokumen50 halamanDistribuciones ContinuasMaricel Parra Osorio0% (3)
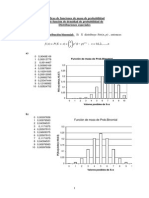
- Gráficas de FMP y de FDPDokumen8 halamanGráficas de FMP y de FDPHugoAlexanderTorresMantillaBelum ada peringkat
- Clase 10 Invope IDokumen33 halamanClase 10 Invope ILuis Zárate PretelBelum ada peringkat
- Modelos Probabilísticos de Eventos MáximosDokumen5 halamanModelos Probabilísticos de Eventos MáximosJUSTOBelum ada peringkat
- Distribucion PoissonDokumen10 halamanDistribucion PoissonwendyBelum ada peringkat
- Actividad9 10Dokumen7 halamanActividad9 10Daneil RobledoBelum ada peringkat
- Problemas 7, 20, 33, 46, 59, 72, 85. (S) PDFDokumen8 halamanProblemas 7, 20, 33, 46, 59, 72, 85. (S) PDFHHurinBelum ada peringkat
- S10 - Programación Orientada A Objetos - Herencia y PolimorfismoDokumen11 halamanS10 - Programación Orientada A Objetos - Herencia y PolimorfismoAndres panoca romeroBelum ada peringkat
- Mpro2 U1 EaDokumen21 halamanMpro2 U1 EaRicardo DiazBelum ada peringkat
- Estadistica Variable AleatoriaDokumen5 halamanEstadistica Variable AleatoriaLuis Nexon GrandeBelum ada peringkat
- Clase1 UmlDokumen73 halamanClase1 UmlJuan Carlos Gallardo SaavedraBelum ada peringkat