Anda mungkin juga menyukai
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)Dari EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Penilaian: 4.5 dari 5 bintang4.5/5 (119)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaDari EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaPenilaian: 4.5 dari 5 bintang4.5/5 (265)
- The Little Book of Hygge: Danish Secrets to Happy LivingDari EverandThe Little Book of Hygge: Danish Secrets to Happy LivingPenilaian: 3.5 dari 5 bintang3.5/5 (399)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryDari EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryPenilaian: 3.5 dari 5 bintang3.5/5 (231)
- Grit: The Power of Passion and PerseveranceDari EverandGrit: The Power of Passion and PerseverancePenilaian: 4 dari 5 bintang4/5 (587)
- Never Split the Difference: Negotiating As If Your Life Depended On ItDari EverandNever Split the Difference: Negotiating As If Your Life Depended On ItPenilaian: 4.5 dari 5 bintang4.5/5 (838)
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeDari EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifePenilaian: 4 dari 5 bintang4/5 (5794)
- Rise of ISIS: A Threat We Can't IgnoreDari EverandRise of ISIS: A Threat We Can't IgnorePenilaian: 3.5 dari 5 bintang3.5/5 (137)
- Team of Rivals: The Political Genius of Abraham LincolnDari EverandTeam of Rivals: The Political Genius of Abraham LincolnPenilaian: 4.5 dari 5 bintang4.5/5 (234)
- Shoe Dog: A Memoir by the Creator of NikeDari EverandShoe Dog: A Memoir by the Creator of NikePenilaian: 4.5 dari 5 bintang4.5/5 (537)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyDari EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyPenilaian: 3.5 dari 5 bintang3.5/5 (2219)
- The Emperor of All Maladies: A Biography of CancerDari EverandThe Emperor of All Maladies: A Biography of CancerPenilaian: 4.5 dari 5 bintang4.5/5 (271)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreDari EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You ArePenilaian: 4 dari 5 bintang4/5 (1090)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersDari EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersPenilaian: 4.5 dari 5 bintang4.5/5 (344)
- Her Body and Other Parties: StoriesDari EverandHer Body and Other Parties: StoriesPenilaian: 4 dari 5 bintang4/5 (821)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceDari EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RacePenilaian: 4 dari 5 bintang4/5 (894)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureDari EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FuturePenilaian: 4.5 dari 5 bintang4.5/5 (474)
- Physics 11 by NelsonDokumen588 halamanPhysics 11 by NelsonGreycia Karyl CabangonBelum ada peringkat
- The Unwinding: An Inner History of the New AmericaDari EverandThe Unwinding: An Inner History of the New AmericaPenilaian: 4 dari 5 bintang4/5 (45)
- The Yellow House: A Memoir (2019 National Book Award Winner)Dari EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Penilaian: 4 dari 5 bintang4/5 (98)
- On Fire: The (Burning) Case for a Green New DealDari EverandOn Fire: The (Burning) Case for a Green New DealPenilaian: 4 dari 5 bintang4/5 (73)
- (Context and Commentary) J. A. V Chapple (Auth.) - Science and Literature in The Nineteenth Century (1986, Macmillan Education UK)Dokumen206 halaman(Context and Commentary) J. A. V Chapple (Auth.) - Science and Literature in The Nineteenth Century (1986, Macmillan Education UK)AmalH.IssaBelum ada peringkat
- Academic ReadingDokumen8 halamanAcademic ReadingjugoslavijaBelum ada peringkat
- Four Concepts of Social StructureDokumen17 halamanFour Concepts of Social Structureshd9617100% (1)
- STS ReviewerDokumen5 halamanSTS ReviewerRain AguasBelum ada peringkat
- Gilbert - From Postgraduate To Social Scientist Project Management - 2006 PDFDokumen239 halamanGilbert - From Postgraduate To Social Scientist Project Management - 2006 PDFworstwardhoBelum ada peringkat
- Name of The Presentators: Faraz Usmani Syed Sanan Ali Maira Fatima Wajiha Naqvi Zahra MohsinDokumen13 halamanName of The Presentators: Faraz Usmani Syed Sanan Ali Maira Fatima Wajiha Naqvi Zahra MohsinMohammadBelum ada peringkat
- RadiationDokumen39 halamanRadiationMichelle PomidaBelum ada peringkat
- Politics and GovernanceDokumen3 halamanPolitics and GovernanceMichelle PomidaBelum ada peringkat
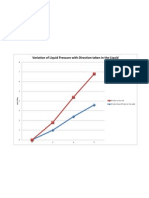
- Variation of Liquid Pressure With Direction Taken in The LiquidDokumen1 halamanVariation of Liquid Pressure With Direction Taken in The LiquidMichelle PomidaBelum ada peringkat
- Variation of Liquid Pressure With DepthDokumen1 halamanVariation of Liquid Pressure With DepthMichelle PomidaBelum ada peringkat
- History of Criminal Justice in the PhilippinesDokumen29 halamanHistory of Criminal Justice in the PhilippinesMichelle Pomida100% (1)
- Early Origins of Table TennisDokumen4 halamanEarly Origins of Table TennisMichelle PomidaBelum ada peringkat
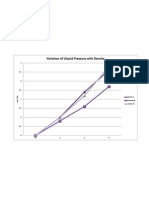
- Variation of Lliquid Pressure With DensityDokumen1 halamanVariation of Lliquid Pressure With DensityMichelle PomidaBelum ada peringkat
- EconomicsDokumen23 halamanEconomicsMichelle PomidaBelum ada peringkat
- Japanese PoemsDokumen2 halamanJapanese PoemsMichelle PomidaBelum ada peringkat
- Technological University of The Philippines National Service Training Program Civil Welfare Training ProgramDokumen3 halamanTechnological University of The Philippines National Service Training Program Civil Welfare Training ProgramMichelle PomidaBelum ada peringkat
- Basis Gift Giving Monitoring Requiremen TS Propos AL Making Specific Compliance Remark S Comple TE Incomple TEDokumen4 halamanBasis Gift Giving Monitoring Requiremen TS Propos AL Making Specific Compliance Remark S Comple TE Incomple TEMichelle PomidaBelum ada peringkat
- Basis Gift Giving Monitoring Requirements Proposal Making Specific Compliance Remarks Complete IncompleteDokumen4 halamanBasis Gift Giving Monitoring Requirements Proposal Making Specific Compliance Remarks Complete IncompleteMichelle PomidaBelum ada peringkat
- Basis Gift Giving Monitoring Requiremen TS Propos AL Making Specific Compliance Remark S Comple TE Incomple TEDokumen4 halamanBasis Gift Giving Monitoring Requiremen TS Propos AL Making Specific Compliance Remark S Comple TE Incomple TEMichelle PomidaBelum ada peringkat
- Technological University of The Philippines National Service Training Program Civil Welfare Training ProgramDokumen3 halamanTechnological University of The Philippines National Service Training Program Civil Welfare Training ProgramMichelle PomidaBelum ada peringkat
- Anthropometry Lab Report 1Dokumen4 halamanAnthropometry Lab Report 1MD Al-AminBelum ada peringkat
- Statistical Tools Thesis SampleDokumen5 halamanStatistical Tools Thesis Sampleqfsimwvff100% (1)
- Ch04 DistributionsDokumen121 halamanCh04 DistributionsalikazimovazBelum ada peringkat
- OKelly Primary Science and Creativity Strange BedfellowsDokumen6 halamanOKelly Primary Science and Creativity Strange BedfellowsJoseph ClementsBelum ada peringkat
- Freudian Revolution - DisplacementDokumen2 halamanFreudian Revolution - DisplacementHarvey PontillaBelum ada peringkat
- SSP Reflection Paper - MANLUCOB, Lyra Kaye B.Dokumen6 halamanSSP Reflection Paper - MANLUCOB, Lyra Kaye B.LYRA KAYE MANLUCOBBelum ada peringkat
- Jamshedpur Women'S College Examination Schedule 1 and 2 End Semester Exam of Mba TIME: 11.00 A.M. TO 2.00 P.MDokumen5 halamanJamshedpur Women'S College Examination Schedule 1 and 2 End Semester Exam of Mba TIME: 11.00 A.M. TO 2.00 P.MSumit DhimanBelum ada peringkat
- Development of Society in India: An Overview of Early StudiesDokumen235 halamanDevelopment of Society in India: An Overview of Early StudiesheretostudyBelum ada peringkat
- Experiment No. 6Dokumen9 halamanExperiment No. 6Neeraj TamboliBelum ada peringkat
- Campus North Central Employee Compensation Report 2014Dokumen60 halamanCampus North Central Employee Compensation Report 2014stephenb4k3rBelum ada peringkat
- Brief Achievements UAFDokumen5 halamanBrief Achievements UAFWaqar Akbar KhanBelum ada peringkat
- Role of Reasoning in Research MethodologyDokumen7 halamanRole of Reasoning in Research MethodologyDr.Ramanath PandeyBelum ada peringkat
- 10 Validation Verification ReassessmentDokumen56 halaman10 Validation Verification Reassessmentahmadgalal74Belum ada peringkat
- Chuong 2Dokumen28 halamanChuong 2Mỹ HuyềnBelum ada peringkat
- EE 213: Electrical Instrumentation & measurement (2 Credit HoursDokumen24 halamanEE 213: Electrical Instrumentation & measurement (2 Credit Hoursrafey amerBelum ada peringkat
- LIC - Home Science PDFDokumen628 halamanLIC - Home Science PDFRahul ChaudharyBelum ada peringkat
- Pursuing Higher Education Abroad: Opportunities Are Not Gifted, They Are Created !!!Dokumen53 halamanPursuing Higher Education Abroad: Opportunities Are Not Gifted, They Are Created !!!Muhammad WaqarBelum ada peringkat
- Thesis Template Melbourne UniversityDokumen5 halamanThesis Template Melbourne Universityafbwrszxd100% (2)
- Driskell, Copper&Moran 1994Dokumen12 halamanDriskell, Copper&Moran 1994Catherine BouthilletteBelum ada peringkat
- A Level Physics Flying Start GuideDokumen9 halamanA Level Physics Flying Start GuideNiall QuadrosBelum ada peringkat
- Article 2022,2023 About ICTDokumen30 halamanArticle 2022,2023 About ICTAisyah Mardhiyah SBelum ada peringkat
- All Planet Research ProjectsDokumen9 halamanAll Planet Research Projectsapi-489862967Belum ada peringkat
- Scientific Method and Measuring MagnitudesDokumen20 halamanScientific Method and Measuring MagnitudesS APBelum ada peringkat