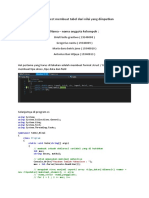
Anda mungkin juga menyukai
- ISYS6513 TK3 W8 S12 R0 NurdinDokumen5 halamanISYS6513 TK3 W8 S12 R0 NurdinArsyadani LuthfiBelum ada peringkat
- Pemrograman Berorientasi Objek dengan Visual C#Dari EverandPemrograman Berorientasi Objek dengan Visual C#Penilaian: 3.5 dari 5 bintang3.5/5 (6)
- Bab 9 Interactive QueryingDokumen87 halamanBab 9 Interactive QueryingyifanBelum ada peringkat
- ArrayDokumen12 halamanArraydefiBelum ada peringkat
- Laporan Praktikum 5 & 6 P WebDokumen7 halamanLaporan Praktikum 5 & 6 P Webdwi saputraBelum ada peringkat
- Laporan MysqlDokumen6 halamanLaporan Mysqldeeta8Belum ada peringkat
- Data WranglingDokumen12 halamanData Wranglingdefi rayadiBelum ada peringkat
- Code Block LatihanDokumen16 halamanCode Block LatihanArfaq Fauqi RomadlonBelum ada peringkat
- Bab 19Dokumen7 halamanBab 19Syifa Rifda SayyidahBelum ada peringkat
- 2122 Comp6118036 Tdca TK2-W4-S6-R1 Team6Dokumen11 halaman2122 Comp6118036 Tdca TK2-W4-S6-R1 Team6Didi LeonaldyBelum ada peringkat
- Laporan Pertemuan Ke-8 Sistem Basis DataDokumen5 halamanLaporan Pertemuan Ke-8 Sistem Basis DataMukhammad Luthfi Widiatmoko100% (1)
- Aplikasi Bahasa Pemrograman R Dalam Ilmu IklimDokumen16 halamanAplikasi Bahasa Pemrograman R Dalam Ilmu IklimRahmad Auliya Tri PutraBelum ada peringkat
- 04 View TriggerDokumen20 halaman04 View Triggercathy_vanchaBelum ada peringkat
- Data Preprocessing in SparkDokumen9 halamanData Preprocessing in SparkfalahrohmawanBelum ada peringkat
- AyamDokumen11 halamanAyamaulia sindi regita pramestiBelum ada peringkat
- Laporan Akhir Praktikum 2 Ranny Vania HastutiDokumen11 halamanLaporan Akhir Praktikum 2 Ranny Vania HastutiRanny Vania HastutiBelum ada peringkat
- Modul Struktur DataDokumen39 halamanModul Struktur DataobiebaeBelum ada peringkat
- Laporan Jobsheet4 Rizky Andika Putra 22343011Dokumen11 halamanLaporan Jobsheet4 Rizky Andika Putra 22343011rizkyandika691Belum ada peringkat
- CCS120 7541 092018 Modul Struktur DataDokumen39 halamanCCS120 7541 092018 Modul Struktur DataSyarifBelum ada peringkat
- Array 6.2Dokumen8 halamanArray 6.2anggiadwi1907Belum ada peringkat
- Perintah MySQL Berhubungan Dengan Tanggal Dan WaktuDokumen13 halamanPerintah MySQL Berhubungan Dengan Tanggal Dan WaktuAbdurrahman DzakiyBelum ada peringkat
- Chapter 7Dokumen10 halamanChapter 7Dinar SalihinBelum ada peringkat
- Modul ArrayDokumen7 halamanModul ArrayFerdi ArdiansyahBelum ada peringkat
- Array C++Dokumen9 halamanArray C++Mutiara Afilia Primadhani RahmatillahBelum ada peringkat
- Membuat File JavaScript Flash Pada Macromedia Dreamweaver 8.Dokumen18 halamanMembuat File JavaScript Flash Pada Macromedia Dreamweaver 8.Dicky SugaraBelum ada peringkat
- Praktikum 7Dokumen16 halamanPraktikum 7Hyureka SilverStone100% (1)
- Ahmadfauzi x5h PboDokumen4 halamanAhmadfauzi x5h PboIndah NovianahBelum ada peringkat
- #7 Menampilkan Data Dan InsertDokumen7 halaman#7 Menampilkan Data Dan InsertFaqih harun5Belum ada peringkat
- Tugas Struktur DataDokumen7 halamanTugas Struktur DataTegar WibowoBelum ada peringkat
- Pertemuan Stored-Procedure+triggerDokumen44 halamanPertemuan Stored-Procedure+triggerEva RohmaniyahBelum ada peringkat
- Pertemuan V 2Dokumen16 halamanPertemuan V 2Rifky RaymondBelum ada peringkat
- Modul Stored ProcedureDokumen7 halamanModul Stored ProcedureWahyu FajarBelum ada peringkat
- Fungsi Date and TimeDokumen7 halamanFungsi Date and Timesdaripadadicintai_frBelum ada peringkat
- Tugas Project Membuat Tabel Dari Nilai Yang DiinputkanDokumen6 halamanTugas Project Membuat Tabel Dari Nilai Yang DiinputkanAntonius Bun WijayaBelum ada peringkat
- Manipulasi Data (Fungsi)Dokumen9 halamanManipulasi Data (Fungsi)M.Hafizh Syah Utama 12Belum ada peringkat
- Soal Responsi 2015Dokumen5 halamanSoal Responsi 2015exztlineBelum ada peringkat
- Tugas Advance Java WebDokumen21 halamanTugas Advance Java WebTiko FridayantoBelum ada peringkat
- Modul Praktikum Algoritma Dan Struktur DataDokumen49 halamanModul Praktikum Algoritma Dan Struktur DataTeukuAldi GamingsBelum ada peringkat
- Pengantar Soal MySQL Via XAMPPDokumen11 halamanPengantar Soal MySQL Via XAMPPnapsterzalBelum ada peringkat
- Fadhl Nostra Illyasa X-9 - 11.ipynb - Colaboratory)Dokumen11 halamanFadhl Nostra Illyasa X-9 - 11.ipynb - Colaboratory)Fadhl N。IBelum ada peringkat
- P A 5Dokumen21 halamanP A 5ArdiBelum ada peringkat
- Webgis Mapserver OpenlayersDokumen12 halamanWebgis Mapserver Openlayerssonyhartono100% (1)
- CRUD NetbeansDokumen16 halamanCRUD NetbeansAndi ApriatnaBelum ada peringkat
- Buat Database Dan Tabel Menggunakan Perintah SQL Dengan Struktur BerikutDokumen3 halamanBuat Database Dan Tabel Menggunakan Perintah SQL Dengan Struktur BerikutAfriza Eka SavinaBelum ada peringkat
- File DataDokumen23 halamanFile DataOndra PutraBelum ada peringkat
- BUNDEL SOAL Tgkat 2Dokumen75 halamanBUNDEL SOAL Tgkat 2Warw1cKBelum ada peringkat
- Struktur Data - 50 Soal Pointer, Sorting Dan Searching - IsiDokumen36 halamanStruktur Data - 50 Soal Pointer, Sorting Dan Searching - IsiImam Ciptarjo100% (2)
- STRUKTURDokumen10 halamanSTRUKTURRahmad Hafiz AssegafBelum ada peringkat
- Modul 1 - Array Dan StructDokumen8 halamanModul 1 - Array Dan StructMuh Milky Yudha PratamaBelum ada peringkat
- Week 9 ArrayDokumen38 halamanWeek 9 ArrayEricBelum ada peringkat
- ReferensiDokumen48 halamanReferensiAnonymous 6zc3bijuy8Belum ada peringkat
- Membuat Combo Box Bertingkat Dengan Plugin Select 2 Pada Codeigniter 3Dokumen8 halamanMembuat Combo Box Bertingkat Dengan Plugin Select 2 Pada Codeigniter 3Kecamatan TakisungBelum ada peringkat
- Pertemuan 2 - Array+manipulasi StringDokumen9 halamanPertemuan 2 - Array+manipulasi Stringdidi dididamhuri100% (1)
- Laporan Praktikum VI ARRAYDokumen40 halamanLaporan Praktikum VI ARRAYFYBRIANTIKA67% (6)
- Fundamental SQL With SELECT StatementDokumen25 halamanFundamental SQL With SELECT StatementHendrayana FauziBelum ada peringkat
- Laporan Jobsheet3 Rizky Andika Putra 22343011Dokumen12 halamanLaporan Jobsheet3 Rizky Andika Putra 22343011rizkyandika691Belum ada peringkat
- Bab 6Dokumen7 halamanBab 6wkkwBelum ada peringkat
- Week 13 - IoT IndustrialDokumen5 halamanWeek 13 - IoT IndustrialwkkwBelum ada peringkat
- Materi 3 IoT GatewayDokumen12 halamanMateri 3 IoT GatewaywkkwBelum ada peringkat
- 1497 MaterialsDokumen9 halaman1497 MaterialswkkwBelum ada peringkat
- NgetehDokumen15 halamanNgetehwkkwBelum ada peringkat
- PENDIDIKAN PANCASILA (BAB V) - DikonversiDokumen63 halamanPENDIDIKAN PANCASILA (BAB V) - DikonversiSari Dwi OktariBelum ada peringkat
- Ilham Ridha Putra 200911035 JurnalDokumen19 halamanIlham Ridha Putra 200911035 JurnalwkkwBelum ada peringkat
- 1 PBDokumen6 halaman1 PBHendri NurbeniBelum ada peringkat
- WKKWDokumen1 halamanWKKWwkkwBelum ada peringkat
- WKKWDokumen1 halamanWKKWwkkwBelum ada peringkat
- WKKWDokumen1 halamanWKKWwkkwBelum ada peringkat