Anda mungkin juga menyukai
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryDari EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryPenilaian: 3.5 dari 5 bintang3.5/5 (231)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)Dari EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Penilaian: 4.5 dari 5 bintang4.5/5 (121)
- Grit: The Power of Passion and PerseveranceDari EverandGrit: The Power of Passion and PerseverancePenilaian: 4 dari 5 bintang4/5 (588)
- Never Split the Difference: Negotiating As If Your Life Depended On ItDari EverandNever Split the Difference: Negotiating As If Your Life Depended On ItPenilaian: 4.5 dari 5 bintang4.5/5 (838)
- The Little Book of Hygge: Danish Secrets to Happy LivingDari EverandThe Little Book of Hygge: Danish Secrets to Happy LivingPenilaian: 3.5 dari 5 bintang3.5/5 (400)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaDari EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaPenilaian: 4.5 dari 5 bintang4.5/5 (266)
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeDari EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifePenilaian: 4 dari 5 bintang4/5 (5794)
- Rise of ISIS: A Threat We Can't IgnoreDari EverandRise of ISIS: A Threat We Can't IgnorePenilaian: 3.5 dari 5 bintang3.5/5 (137)
- Her Body and Other Parties: StoriesDari EverandHer Body and Other Parties: StoriesPenilaian: 4 dari 5 bintang4/5 (821)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreDari EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You ArePenilaian: 4 dari 5 bintang4/5 (1090)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyDari EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyPenilaian: 3.5 dari 5 bintang3.5/5 (2259)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersDari EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersPenilaian: 4.5 dari 5 bintang4.5/5 (345)
- Shoe Dog: A Memoir by the Creator of NikeDari EverandShoe Dog: A Memoir by the Creator of NikePenilaian: 4.5 dari 5 bintang4.5/5 (537)
- The Emperor of All Maladies: A Biography of CancerDari EverandThe Emperor of All Maladies: A Biography of CancerPenilaian: 4.5 dari 5 bintang4.5/5 (271)
- Team of Rivals: The Political Genius of Abraham LincolnDari EverandTeam of Rivals: The Political Genius of Abraham LincolnPenilaian: 4.5 dari 5 bintang4.5/5 (234)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceDari EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RacePenilaian: 4 dari 5 bintang4/5 (895)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureDari EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FuturePenilaian: 4.5 dari 5 bintang4.5/5 (474)
- On Fire: The (Burning) Case for a Green New DealDari EverandOn Fire: The (Burning) Case for a Green New DealPenilaian: 4 dari 5 bintang4/5 (74)
- The Yellow House: A Memoir (2019 National Book Award Winner)Dari EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Penilaian: 4 dari 5 bintang4/5 (98)
- National Football League FRC 2000 Sol SRGBDokumen33 halamanNational Football League FRC 2000 Sol SRGBMick StukesBelum ada peringkat
- The Unwinding: An Inner History of the New AmericaDari EverandThe Unwinding: An Inner History of the New AmericaPenilaian: 4 dari 5 bintang4/5 (45)
- 385C Waw1-Up PDFDokumen4 halaman385C Waw1-Up PDFJUNA RUSANDI SBelum ada peringkat
- TFGDokumen46 halamanTFGAlex Gigena50% (2)
- Speed, Velocity & Acceleration (Physics Report)Dokumen66 halamanSpeed, Velocity & Acceleration (Physics Report)Kristian Dave DivaBelum ada peringkat
- Hydraulic Mining ExcavatorDokumen8 halamanHydraulic Mining Excavatorasditia_07100% (1)
- Exotic DVM 11 3 CompleteDokumen12 halamanExotic DVM 11 3 CompleteLuc CardBelum ada peringkat
- NIQS BESMM 4 BillDokumen85 halamanNIQS BESMM 4 BillAliBelum ada peringkat
- Famous Little Red Book SummaryDokumen6 halamanFamous Little Red Book SummaryMatt MurdockBelum ada peringkat
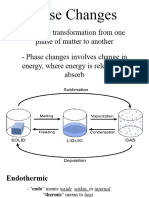
- General Chemistry 2 Q1 Lesson 5 Endothermic and Exotheric Reaction and Heating and Cooling CurveDokumen19 halamanGeneral Chemistry 2 Q1 Lesson 5 Endothermic and Exotheric Reaction and Heating and Cooling CurveJolo Allexice R. PinedaBelum ada peringkat
- Product Manual 26086 (Revision E) : EGCP-2 Engine Generator Control PackageDokumen152 halamanProduct Manual 26086 (Revision E) : EGCP-2 Engine Generator Control PackageErick KurodaBelum ada peringkat
- Data Asimilasi Untuk PemulaDokumen24 halamanData Asimilasi Untuk PemulaSii Olog-olog PlonkBelum ada peringkat
- 2016 W-2 Gross Wages CityDokumen16 halaman2016 W-2 Gross Wages CityportsmouthheraldBelum ada peringkat
- Introduction To Atomistic Simulation Through Density Functional TheoryDokumen21 halamanIntroduction To Atomistic Simulation Through Density Functional TheoryTarang AgrawalBelum ada peringkat
- Project Management TY BSC ITDokumen57 halamanProject Management TY BSC ITdarshan130275% (12)
- Chemistry Investigatory Project (R)Dokumen23 halamanChemistry Investigatory Project (R)BhagyashreeBelum ada peringkat
- Research 093502Dokumen8 halamanResearch 093502Chrlszjhon Sales SuguitanBelum ada peringkat
- Binge Eating Disorder ANNADokumen12 halamanBinge Eating Disorder ANNAloloasbBelum ada peringkat
- Mathematics Mock Exam 2015Dokumen4 halamanMathematics Mock Exam 2015Ian BautistaBelum ada peringkat
- Satish Gujral - FinalDokumen23 halamanSatish Gujral - Finalsatya madhuBelum ada peringkat
- Shelly e CommerceDokumen13 halamanShelly e CommerceVarun_Arya_8382Belum ada peringkat
- Solubility Product ConstantsDokumen6 halamanSolubility Product ConstantsBilal AhmedBelum ada peringkat
- What Is Universe?Dokumen19 halamanWhat Is Universe?Ruben M. VerdidaBelum ada peringkat
- Aditya Birla GroupDokumen21 halamanAditya Birla GroupNarendra ThummarBelum ada peringkat
- Analytical Chem Lab #3Dokumen4 halamanAnalytical Chem Lab #3kent galangBelum ada peringkat
- Surgery - 2020 With CorrectionDokumen70 halamanSurgery - 2020 With CorrectionBaraa KassisBelum ada peringkat
- Acc116 Dec 2022 - Q - Test 1Dokumen6 halamanAcc116 Dec 2022 - Q - Test 12022825274100% (1)
- SABRE MK-3 CFT Gel SpecDokumen1 halamanSABRE MK-3 CFT Gel Specseregio12Belum ada peringkat
- CH 04Dokumen19 halamanCH 04Charmaine Bernados BrucalBelum ada peringkat
- ALE Manual For LaserScope Arc Lamp Power SupplyDokumen34 halamanALE Manual For LaserScope Arc Lamp Power SupplyKen DizzeruBelum ada peringkat
- Case Study - Kelompok 2Dokumen5 halamanCase Study - Kelompok 2elida wenBelum ada peringkat