Anda mungkin juga menyukai
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeDari EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifePenilaian: 4 dari 5 bintang4/5 (5794)
- 2013 SSAR MembershipDokumen3 halaman2013 SSAR MembershipAnonymous OYCf2UkBelum ada peringkat
- The Little Book of Hygge: Danish Secrets to Happy LivingDari EverandThe Little Book of Hygge: Danish Secrets to Happy LivingPenilaian: 3.5 dari 5 bintang3.5/5 (399)
- Solfegietto: at Vance D'après JS Bach Only HumansDokumen4 halamanSolfegietto: at Vance D'après JS Bach Only HumansAnonymous OYCf2UkBelum ada peringkat
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryDari EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryPenilaian: 3.5 dari 5 bintang3.5/5 (231)
- Guitar Pro 5.2Dokumen1 halamanGuitar Pro 5.2DanProdanBelum ada peringkat
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceDari EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RacePenilaian: 4 dari 5 bintang4/5 (894)
- An Uros Vered As EstimatesDokumen2 halamanAn Uros Vered As EstimatesAnonymous OYCf2UkBelum ada peringkat
- The Yellow House: A Memoir (2019 National Book Award Winner)Dari EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Penilaian: 4 dari 5 bintang4/5 (98)
- Lista Herpeto E.mimosaDokumen1 halamanLista Herpeto E.mimosaAnonymous OYCf2UkBelum ada peringkat
- Shoe Dog: A Memoir by the Creator of NikeDari EverandShoe Dog: A Memoir by the Creator of NikePenilaian: 4.5 dari 5 bintang4.5/5 (537)
- 2009-Guimarães Etal - Relevo Digital Dos Municípios BrasileirosDokumen8 halaman2009-Guimarães Etal - Relevo Digital Dos Municípios BrasileirosAnonymous OYCf2UkBelum ada peringkat
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureDari EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FuturePenilaian: 4.5 dari 5 bintang4.5/5 (474)
- Haddad & Prado 2005 - Reproductive ModesDokumen11 halamanHaddad & Prado 2005 - Reproductive ModesAnonymous OYCf2UkBelum ada peringkat
- Never Split the Difference: Negotiating As If Your Life Depended On ItDari EverandNever Split the Difference: Negotiating As If Your Life Depended On ItPenilaian: 4.5 dari 5 bintang4.5/5 (838)
- 2012-Strussmann Etal - Geographic Distribution E.magnusDokumen4 halaman2012-Strussmann Etal - Geographic Distribution E.magnusAnonymous OYCf2UkBelum ada peringkat
- Grit: The Power of Passion and PerseveranceDari EverandGrit: The Power of Passion and PerseverancePenilaian: 4 dari 5 bintang4/5 (587)
- 2011-Strussman Etal. Herpetofauna PantanalDokumen25 halaman2011-Strussman Etal. Herpetofauna PantanalAnonymous OYCf2UkBelum ada peringkat
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaDari EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaPenilaian: 4.5 dari 5 bintang4.5/5 (265)
- Importance of Stupidity in ScienceDokumen1 halamanImportance of Stupidity in ScienceFlyingAxe100% (2)
- Dr. Morse's Herbal Formulation ListDokumen10 halamanDr. Morse's Herbal Formulation ListTom50% (2)
- EstomagoDokumen43 halamanEstomagoTanya FigueroaBelum ada peringkat
- The Emperor of All Maladies: A Biography of CancerDari EverandThe Emperor of All Maladies: A Biography of CancerPenilaian: 4.5 dari 5 bintang4.5/5 (271)
- Systematic BotanyDokumen358 halamanSystematic Botanyrandel100% (3)
- On Fire: The (Burning) Case for a Green New DealDari EverandOn Fire: The (Burning) Case for a Green New DealPenilaian: 4 dari 5 bintang4/5 (73)
- Lighthouse International - Effective Color ContrastDokumen5 halamanLighthouse International - Effective Color ContrastVaishnavi JayakumarBelum ada peringkat
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersDari EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersPenilaian: 4.5 dari 5 bintang4.5/5 (344)
- Assess Patient Data Such As Vital Signs, Laboratory Values, and Allergies Before Preparing and Administering Medications by InjectionDokumen12 halamanAssess Patient Data Such As Vital Signs, Laboratory Values, and Allergies Before Preparing and Administering Medications by InjectionLRBBelum ada peringkat
- Team of Rivals: The Political Genius of Abraham LincolnDari EverandTeam of Rivals: The Political Genius of Abraham LincolnPenilaian: 4.5 dari 5 bintang4.5/5 (234)
- Respiration Course ObjectivesDokumen8 halamanRespiration Course Objectivesjoshy220996Belum ada peringkat
- Methods, Method Verification and ValidationDokumen14 halamanMethods, Method Verification and Validationjljimenez1969100% (16)
- Aquaponics ProjectDokumen5 halamanAquaponics Projectキャベ ジョセルBelum ada peringkat
- Rise of ISIS: A Threat We Can't IgnoreDari EverandRise of ISIS: A Threat We Can't IgnorePenilaian: 3.5 dari 5 bintang3.5/5 (137)
- Budget of Work Science Grade 3Dokumen1 halamanBudget of Work Science Grade 3Mary Chovie BacusBelum ada peringkat
- 1 Bio400 Sept 2018 Lecture 1 Introduction Sept 3Dokumen89 halaman1 Bio400 Sept 2018 Lecture 1 Introduction Sept 3The seriBelum ada peringkat
- The Unwinding: An Inner History of the New AmericaDari EverandThe Unwinding: An Inner History of the New AmericaPenilaian: 4 dari 5 bintang4/5 (45)
- Types of COVID VaccinesDokumen1 halamanTypes of COVID VaccinesEmre ÇELİKBelum ada peringkat
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyDari EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyPenilaian: 3.5 dari 5 bintang3.5/5 (2219)
- Udc Vol 1Dokumen921 halamanUdc Vol 1Dani TrashBelum ada peringkat
- Application of Edible Films and Coatings On MeatsDokumen2 halamanApplication of Edible Films and Coatings On MeatsAnasZeidBelum ada peringkat
- Phyllodes Tumors of The Breast UpToDateDokumen22 halamanPhyllodes Tumors of The Breast UpToDateSean SialanaBelum ada peringkat
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreDari EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You ArePenilaian: 4 dari 5 bintang4/5 (1090)
- Acute Effects of Ayahuasca in A Juvenile Non-Human Primate Model of DepressionDokumen9 halamanAcute Effects of Ayahuasca in A Juvenile Non-Human Primate Model of DepressionGonzaloBimonteBelum ada peringkat
- Atheena Milagi Pandian. SDokumen3 halamanAtheena Milagi Pandian. SAtheena PandianBelum ada peringkat
- Cucumber Seed Germination: Effect and After-Effect of Temperature TreatmentsDokumen7 halamanCucumber Seed Germination: Effect and After-Effect of Temperature Treatmentsprotap uddin PolenBelum ada peringkat
- DMT of MNDDokumen39 halamanDMT of MNDthelegend 2022Belum ada peringkat
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)Dari EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Penilaian: 4.5 dari 5 bintang4.5/5 (119)
- To Study The Quantity Case in Present in Different Sample of MilkDokumen7 halamanTo Study The Quantity Case in Present in Different Sample of Milkbelly4u100% (2)
- Gen Bio 1 Module 1Dokumen30 halamanGen Bio 1 Module 1Louise Gabriel Lozada100% (1)
- Artificial Immunity Vs Natural ImmunityDokumen87 halamanArtificial Immunity Vs Natural ImmunityromeoqfacebookBelum ada peringkat
- Exampro GCSE Biology: B2.5 InheritanceDokumen35 halamanExampro GCSE Biology: B2.5 InheritanceMeera ParaBelum ada peringkat
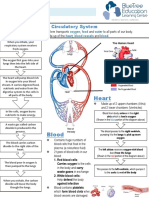
- Circulatory System Notes SLDokumen1 halamanCirculatory System Notes SLRathna PalaniappanBelum ada peringkat
- P - Science - 5 - Worksheets - Unit 1Dokumen18 halamanP - Science - 5 - Worksheets - Unit 1Jaishree Rathi80% (5)
- Paul White - The Secrets of Toth and The Keys of EnochDokumen3 halamanPaul White - The Secrets of Toth and The Keys of EnochДанијела ВукмировићBelum ada peringkat
- Coccon Jacket Pattern A4 PDFDokumen16 halamanCoccon Jacket Pattern A4 PDFdaisy22Belum ada peringkat
- Revised TERM PAPERDokumen19 halamanRevised TERM PAPERVikal RajputBelum ada peringkat
- Fphar 12 741623Dokumen17 halamanFphar 12 741623Hendri AldratBelum ada peringkat
- Answer Key Nat ReviewerDokumen19 halamanAnswer Key Nat ReviewerBASAY, HANNA RICA P.Belum ada peringkat
- Life Cycles of Parasites: Bsiop 4-1DDokumen11 halamanLife Cycles of Parasites: Bsiop 4-1DPetunia PoggendorfBelum ada peringkat
- Her Body and Other Parties: StoriesDari EverandHer Body and Other Parties: StoriesPenilaian: 4 dari 5 bintang4/5 (821)