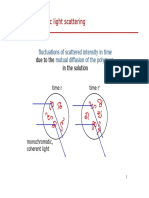
Anda mungkin juga menyukai
- 2008 FinalExam SoCN Final Master SolutionDokumen10 halaman2008 FinalExam SoCN Final Master SolutionBobby BeamanBelum ada peringkat
- 2 CPU Architecture: Fetch-Execute Cycle: 2.1 CPU, Main Memory, I/O UnitsDokumen25 halaman2 CPU Architecture: Fetch-Execute Cycle: 2.1 CPU, Main Memory, I/O UnitsVishal GuptaBelum ada peringkat
- 19 7960 07 NotesDokumen17 halaman19 7960 07 NotesMuhammad Fahmi PamungkasBelum ada peringkat
- Homework3 Solution v2Dokumen41 halamanHomework3 Solution v2razi haiderBelum ada peringkat
- Lecture 5: Memory Hierarchy and Cache Traditional Four Questions For Memory Hierarchy DesignersDokumen10 halamanLecture 5: Memory Hierarchy and Cache Traditional Four Questions For Memory Hierarchy Designersdeepu7deeptiBelum ada peringkat
- Recurrent Neural Networks: Prof. Gheith AbandahDokumen32 halamanRecurrent Neural Networks: Prof. Gheith AbandahranaBelum ada peringkat
- 1.1 Parallelism Is UbiquitousDokumen3 halaman1.1 Parallelism Is UbiquitousRajinder SanwalBelum ada peringkat
- ch09 Morris ManoDokumen15 halamanch09 Morris ManoYogita Negi RawatBelum ada peringkat
- COA NotesDokumen5 halamanCOA NotesDana JrabBelum ada peringkat
- Architectures For Parallel ComputationDokumen13 halamanArchitectures For Parallel ComputationVikas NagareBelum ada peringkat
- Thiet Ke He Thong NhungDokumen75 halamanThiet Ke He Thong NhungPhạm Trung ĐứcBelum ada peringkat
- Lec 01Dokumen2 halamanLec 01SNaveenMathewBelum ada peringkat
- Unit 1 (1) HIGH PERFORMANCE COMPUTINGDokumen54 halamanUnit 1 (1) HIGH PERFORMANCE COMPUTINGA20Gokul C SBelum ada peringkat
- Rapid Simulation of Hydraulic Fracturing Using A Planar 3D ModelDokumen26 halamanRapid Simulation of Hydraulic Fracturing Using A Planar 3D ModelManuel ChBelum ada peringkat
- Unit 5 - Pipeling and MultipoessorsDokumen74 halamanUnit 5 - Pipeling and Multipoessorsshatanand SharmaBelum ada peringkat
- Unit-III: Memory: TopicsDokumen54 halamanUnit-III: Memory: TopicsZain Shoaib MohammadBelum ada peringkat
- Os QuizDokumen5 halamanOs QuizHem RameshBelum ada peringkat
- Ractice Roblems O S: I D P: Perating Ystems Nternals and Esign Rinciples S EDokumen28 halamanRactice Roblems O S: I D P: Perating Ystems Nternals and Esign Rinciples S EHamza Asim Ghazi100% (1)
- Parallel Computing Platforms and Memory System Performance: John Mellor-CrummeyDokumen43 halamanParallel Computing Platforms and Memory System Performance: John Mellor-CrummeyaskbilladdmicrosoftBelum ada peringkat
- Discretization MethodsDokumen32 halamanDiscretization MethodsHari SimhaBelum ada peringkat
- Master SetDokumen624 halamanMaster SetEr Lokesh MahorBelum ada peringkat
- Tute AnswersDokumen11 halamanTute AnswerschulaBelum ada peringkat
- Question 1 (50 Points) PipeliningDokumen3 halamanQuestion 1 (50 Points) PipeliningMuhammad Zahid iqbalBelum ada peringkat
- Digital Design Interview Questions & AnswersDokumen5 halamanDigital Design Interview Questions & AnswersSahil KhanBelum ada peringkat
- Os MCQDokumen21 halamanOs MCQgurusodhiiBelum ada peringkat
- Interconnection Networks: Crossbar Switch, Which Can Simultaneously Connect Any Set ofDokumen11 halamanInterconnection Networks: Crossbar Switch, Which Can Simultaneously Connect Any Set ofgk_gbuBelum ada peringkat
- VLSI & ASIC Digital Design Interview QuestionsDokumen6 halamanVLSI & ASIC Digital Design Interview QuestionsRupesh Kumar DuttaBelum ada peringkat
- Assignment 1Dokumen2 halamanAssignment 1Samira YomiBelum ada peringkat
- Pc98 Lect5 Part1 SpeedupDokumen36 halamanPc98 Lect5 Part1 SpeedupDebopriyo BanerjeeBelum ada peringkat
- Compre IIsem 2003-04 SolDokumen6 halamanCompre IIsem 2003-04 SolmorigasakiBelum ada peringkat
- Multicore Challenge in Vector Pascal: P Cockshott, Y GduraDokumen29 halamanMulticore Challenge in Vector Pascal: P Cockshott, Y GduraPaul CockshottBelum ada peringkat
- Parallel Computing Platforms: Chieh-Sen (Jason) HuangDokumen21 halamanParallel Computing Platforms: Chieh-Sen (Jason) HuangBalakrishBelum ada peringkat
- Systolic Arrays & Their ApplicationsDokumen35 halamanSystolic Arrays & Their ApplicationsSp SinghBelum ada peringkat
- Vlsi Signal ProcessingDokumen455 halamanVlsi Signal ProcessingPavan TejaBelum ada peringkat
- ++probleme TotDokumen22 halaman++probleme TotRochelle ByersBelum ada peringkat
- VLSI Interview QuestionsDokumen41 halamanVLSI Interview QuestionsKarthik Real Pacifier0% (1)
- MA3004 Part 3: Computational Fluid Dynamics (CFD) : Martin SkoteDokumen46 halamanMA3004 Part 3: Computational Fluid Dynamics (CFD) : Martin SkotedavidbehBelum ada peringkat
- ArticuloDokumen7 halamanArticuloGonzalo Peñaloza PlataBelum ada peringkat
- Hls PDFDokumen68 halamanHls PDFMinu MathewBelum ada peringkat
- ECE 368 A Tour by Example of Non-Trivial Circuit Design and VHDL DescriptionDokumen23 halamanECE 368 A Tour by Example of Non-Trivial Circuit Design and VHDL DescriptionAnand ChaudharyBelum ada peringkat
- DSP-8 (DSP Processors)Dokumen8 halamanDSP-8 (DSP Processors)Sathish BalaBelum ada peringkat
- Pipelining and Vector ProcessingDokumen37 halamanPipelining and Vector ProcessingJohn DavidBelum ada peringkat
- GATE QnADokumen5 halamanGATE QnAGaurav MoreBelum ada peringkat
- Introduction To Parallel Processing: Shantanu Dutt University of Illinois at ChicagoDokumen51 halamanIntroduction To Parallel Processing: Shantanu Dutt University of Illinois at ChicagoDattatray BhateBelum ada peringkat
- CS 179: GPU Computing: Recitation 1 - 4/1/16Dokumen18 halamanCS 179: GPU Computing: Recitation 1 - 4/1/16RajulBelum ada peringkat
- Intro To Computer Arch It U Rebs Che A MeDokumen7 halamanIntro To Computer Arch It U Rebs Che A MeEric Leo AsiamahBelum ada peringkat
- Assignment: - 4: Part - ADokumen9 halamanAssignment: - 4: Part - Anikita_gupta3Belum ada peringkat
- Ca Unit 2.2Dokumen22 halamanCa Unit 2.2GuruKPO100% (2)
- ACA T1 SolutionsDokumen17 halamanACA T1 SolutionsshardapatelBelum ada peringkat
- Course Outcome 1:: 15Cs4180 - Parallel ComputingDokumen23 halamanCourse Outcome 1:: 15Cs4180 - Parallel ComputingNaveena bogalaBelum ada peringkat
- Programmer's Model: Thorne: Chapter 2 (Irvine, Edition IV: Chapter 2)Dokumen14 halamanProgrammer's Model: Thorne: Chapter 2 (Irvine, Edition IV: Chapter 2)Mafuzal HoqueBelum ada peringkat
- Introduction To MATLAB: Markus KuhnDokumen18 halamanIntroduction To MATLAB: Markus KuhnbahramrnBelum ada peringkat
- A Whirlwind Tour Through Concurrency: Kedar Namjoshi Bell LabsDokumen37 halamanA Whirlwind Tour Through Concurrency: Kedar Namjoshi Bell LabsErwin QuendanganBelum ada peringkat
- RSA 768 Bit Crypto CrackedDokumen22 halamanRSA 768 Bit Crypto CrackedHTDBelum ada peringkat
- CSE 332 L 14 Short & 15 - 24th & 26th Sep 2020Dokumen28 halamanCSE 332 L 14 Short & 15 - 24th & 26th Sep 2020Nz SaadBelum ada peringkat
- CSE302: Data Structures Using C: DR Ashok Kumar Sahoo 9810226795Dokumen27 halamanCSE302: Data Structures Using C: DR Ashok Kumar Sahoo 9810226795Priyanshu DimriBelum ada peringkat
- Three Improvements To The Reduceron: Matthew Naylor and Colin Runciman University of YorkDokumen50 halamanThree Improvements To The Reduceron: Matthew Naylor and Colin Runciman University of YorkaldeghaidyBelum ada peringkat
- Parallel ComputingDokumen30 halamanParallel ComputingMartina JanevaBelum ada peringkat
- Stud-CSA Memory Mod2-Part2 (Autosaved) (Autosaved)Dokumen48 halamanStud-CSA Memory Mod2-Part2 (Autosaved) (Autosaved)SHEENA YBelum ada peringkat
- Computational Physics Using MATLABDokumen103 halamanComputational Physics Using MATLABDini Fakhriza A67% (6)
- Composites Part B: SciencedirectDokumen9 halamanComposites Part B: SciencedirectAli HassanBelum ada peringkat
- Composites Part B: Xinfeng Zhou, Zirui Jia, Ailing Feng, Jiahao Kou, Haijie Cao, Xuehua Liu, Guanglei WuDokumen12 halamanComposites Part B: Xinfeng Zhou, Zirui Jia, Ailing Feng, Jiahao Kou, Haijie Cao, Xuehua Liu, Guanglei WuAli HassanBelum ada peringkat
- Journal Pre-Proof: Composites Part BDokumen38 halamanJournal Pre-Proof: Composites Part BAli HassanBelum ada peringkat
- Composites Part BDokumen8 halamanComposites Part BAli HassanBelum ada peringkat
- Shu 2019Dokumen12 halamanShu 2019Ali HassanBelum ada peringkat
- Questions8 081215 PDFDokumen1 halamanQuestions8 081215 PDFAli HassanBelum ada peringkat
- Questions12 190116 PDFDokumen1 halamanQuestions12 190116 PDFAli HassanBelum ada peringkat
- Chapter4 Handout PDFDokumen26 halamanChapter4 Handout PDFAli HassanBelum ada peringkat
- Questions11 120116 PDFDokumen1 halamanQuestions11 120116 PDFAli HassanBelum ada peringkat
- Questions7 011215 PDFDokumen1 halamanQuestions7 011215 PDFAli HassanBelum ada peringkat
- Chapter5 PDFDokumen18 halamanChapter5 PDFAli HassanBelum ada peringkat
- Questions9 151215 PDFDokumen1 halamanQuestions9 151215 PDFAli HassanBelum ada peringkat
- Questions6 24115 PDFDokumen1 halamanQuestions6 24115 PDFAli HassanBelum ada peringkat
- Questions5 101115 PDFDokumen1 halamanQuestions5 101115 PDFAli HassanBelum ada peringkat
- Questions4 031115 PDFDokumen1 halamanQuestions4 031115 PDFAli HassanBelum ada peringkat
- Chapter4 Handout PDFDokumen26 halamanChapter4 Handout PDFAli HassanBelum ada peringkat
- Questions3 271015 PDFDokumen1 halamanQuestions3 271015 PDFAli HassanBelum ada peringkat
- Questions2 201015 PDFDokumen1 halamanQuestions2 201015 PDFAli HassanBelum ada peringkat
- Chapter7 PDFDokumen11 halamanChapter7 PDFAli HassanBelum ada peringkat
- Chapter5 PDFDokumen22 halamanChapter5 PDFAli HassanBelum ada peringkat
- Management PriniciplesDokumen87 halamanManagement Priniciplesbusyboy_spBelum ada peringkat
- Governance Operating Model: Structure Oversight Responsibilities Talent and Culture Infrastructu REDokumen6 halamanGovernance Operating Model: Structure Oversight Responsibilities Talent and Culture Infrastructu REBob SolísBelum ada peringkat
- G.Devendiran: Career ObjectiveDokumen2 halamanG.Devendiran: Career ObjectiveSadha SivamBelum ada peringkat
- Puma PypDokumen20 halamanPuma PypPrashanshaBahetiBelum ada peringkat
- Passage To Abstract Mathematics 1st Edition Watkins Solutions ManualDokumen25 halamanPassage To Abstract Mathematics 1st Edition Watkins Solutions ManualMichaelWilliamscnot100% (50)
- 'Causative' English Quiz & Worksheet UsingEnglish ComDokumen2 halaman'Causative' English Quiz & Worksheet UsingEnglish ComINAWATI BINTI AMING MoeBelum ada peringkat
- Gas Compressor SizingDokumen1 halamanGas Compressor SizingNohemigdeliaLucenaBelum ada peringkat
- Atmel 46003 SE M90E32AS DatasheetDokumen84 halamanAtmel 46003 SE M90E32AS DatasheetNagarajBelum ada peringkat
- Statistical Process Control and Process Capability PPT EXPLANATIONDokumen2 halamanStatistical Process Control and Process Capability PPT EXPLANATIONJohn Carlo SantiagoBelum ada peringkat
- Community Profile and Baseline DataDokumen7 halamanCommunity Profile and Baseline DataEJ RaveloBelum ada peringkat
- Michael Clapis Cylinder BlocksDokumen5 halamanMichael Clapis Cylinder Blocksapi-734979884Belum ada peringkat
- Philo Q2 Lesson 5Dokumen4 halamanPhilo Q2 Lesson 5Julliana Patrice Angeles STEM 11 RUBYBelum ada peringkat
- Basic Terms/Concepts IN Analytical ChemistryDokumen53 halamanBasic Terms/Concepts IN Analytical ChemistrySheralyn PelayoBelum ada peringkat
- Hard DiskDokumen9 halamanHard DiskAmarnath SahBelum ada peringkat
- P3 Past Papers Model AnswersDokumen211 halamanP3 Past Papers Model AnswersEyad UsamaBelum ada peringkat
- KRAS QC12K-4X2500 Hydraulic Shearing Machine With E21S ControllerDokumen3 halamanKRAS QC12K-4X2500 Hydraulic Shearing Machine With E21S ControllerJohan Sneider100% (1)
- Chapter 11 AssignmentDokumen2 halamanChapter 11 AssignmentsainothegamerBelum ada peringkat
- Halloween EssayDokumen2 halamanHalloween EssayJonathan LamBelum ada peringkat
- Prediction of Compressive Strength of Research PaperDokumen9 halamanPrediction of Compressive Strength of Research PaperTaufik SheikhBelum ada peringkat
- 2.a.1.f v2 Active Matrix (AM) DTMC (Display Technology Milestone Chart)Dokumen1 halaman2.a.1.f v2 Active Matrix (AM) DTMC (Display Technology Milestone Chart)matwan29Belum ada peringkat
- "Tell Me and I Forget, Teach Me and I May Remember, Involve MeDokumen1 halaman"Tell Me and I Forget, Teach Me and I May Remember, Involve MeBesufkad Yalew YihunBelum ada peringkat
- Levels of CommunicationDokumen3 halamanLevels of CommunicationAiyaz ShaikhBelum ada peringkat
- I. Choose The Best Option (From A, B, C or D) To Complete Each Sentence: (3.0pts)Dokumen5 halamanI. Choose The Best Option (From A, B, C or D) To Complete Each Sentence: (3.0pts)thmeiz.17sBelum ada peringkat
- Unit 1 PrinciplesDokumen17 halamanUnit 1 PrinciplesRohit YadavBelum ada peringkat
- Poster-Shading PaperDokumen1 halamanPoster-Shading PaperOsama AljenabiBelum ada peringkat
- Assignment: Residual Leakage Protection Circuit Circuit DiagramDokumen2 halamanAssignment: Residual Leakage Protection Circuit Circuit DiagramShivam ShrivastavaBelum ada peringkat
- Department of Ece, Adhiparasakthi College of Engineering, KalavaiDokumen31 halamanDepartment of Ece, Adhiparasakthi College of Engineering, KalavaiGiri PrasadBelum ada peringkat
- English For Academic and Professional Purposes - ExamDokumen3 halamanEnglish For Academic and Professional Purposes - ExamEddie Padilla LugoBelum ada peringkat
- Keeping Track of Your Time: Keep Track Challenge Welcome GuideDokumen1 halamanKeeping Track of Your Time: Keep Track Challenge Welcome GuideRizky NurdiansyahBelum ada peringkat
- BSS Troubleshooting Manual PDFDokumen220 halamanBSS Troubleshooting Manual PDFleonardomarinBelum ada peringkat