Anda mungkin juga menyukai
- Tele-Communication (Telecom) Terms Glossary and DictionaryDokumen188 halamanTele-Communication (Telecom) Terms Glossary and DictionaryRaja ImranBelum ada peringkat
- Sigma Delta Modulator NutshellDokumen5 halamanSigma Delta Modulator NutshellZubair MohammedBelum ada peringkat
- Manual CN Lab 2017 PDFDokumen71 halamanManual CN Lab 2017 PDFSuhas h rBelum ada peringkat
- Integrated Service Digital Network IsdnDokumen6 halamanIntegrated Service Digital Network IsdnvahidinkormanBelum ada peringkat
- QoS LTE IEEE16mDokumen16 halamanQoS LTE IEEE16mBityong Yusuf AutaBelum ada peringkat
- Pipelining and Parallel ProcessingDokumen16 halamanPipelining and Parallel ProcessingBilgaBelum ada peringkat
- Lab 6 ADCDokumen6 halamanLab 6 ADCYaz PuteraBelum ada peringkat
- 8255 Ppi ExamplesDokumen10 halaman8255 Ppi Examplesvenky258100% (1)
- Echo Cancellation Project ProposalDokumen2 halamanEcho Cancellation Project ProposalmidhunBelum ada peringkat
- SASTRA - M.tech. ACS (Advanced Communication Systems) - SyllabusDokumen37 halamanSASTRA - M.tech. ACS (Advanced Communication Systems) - SyllabusJOHN PETER100% (1)
- DSP Processors and ArchitecturesDokumen2 halamanDSP Processors and ArchitecturesVemuganti RahulBelum ada peringkat
- Fpga ManualDokumen7 halamanFpga ManualRahul SharmaBelum ada peringkat
- Multivibrator Manual PDFDokumen73 halamanMultivibrator Manual PDFAvijitRoyBelum ada peringkat
- IP Addresses: Classless Addressing: ObjectivesDokumen65 halamanIP Addresses: Classless Addressing: ObjectivesBalram JhaBelum ada peringkat
- L-2 GEPON System (Teracom)Dokumen20 halamanL-2 GEPON System (Teracom)ashishjain_bsnl2033Belum ada peringkat
- Matlab ReportDokumen7 halamanMatlab ReportMUHAMAD_REHANBelum ada peringkat
- Peripheral Interfacing-Iii: ObjectivesDokumen22 halamanPeripheral Interfacing-Iii: ObjectivesAnkit SethiaBelum ada peringkat
- Star Topology LabDokumen3 halamanStar Topology LabBint e Farooq100% (1)
- Admission Control in GPRS-EDGEDokumen10 halamanAdmission Control in GPRS-EDGEVivek UttamBelum ada peringkat
- Performance Analysis of Spreading and Modulation in WCDMA UplinkDokumen5 halamanPerformance Analysis of Spreading and Modulation in WCDMA UplinkseventhsensegroupBelum ada peringkat
- Forouzan Chapter 1,2,3 SummaryDokumen11 halamanForouzan Chapter 1,2,3 SummaryEg LintagBelum ada peringkat
- MicroProcessor MicroController LAB MANUAL MPMC Lab ManualDokumen71 halamanMicroProcessor MicroController LAB MANUAL MPMC Lab ManualDossDossBelum ada peringkat
- RF Design ModelDokumen10 halamanRF Design Modelmathur_mayurBelum ada peringkat
- Presentation Topic: (Radio Remote Control Using DTMF)Dokumen32 halamanPresentation Topic: (Radio Remote Control Using DTMF)Gorank JoshiBelum ada peringkat
- Fiber To Home Micro ProjectDokumen17 halamanFiber To Home Micro ProjectPranil KambleBelum ada peringkat
- DSP Processor FundamentalsDokumen58 halamanDSP Processor FundamentalsSayee KrishnaBelum ada peringkat
- L-6 SatcomDokumen80 halamanL-6 SatcomKeshav KhannaBelum ada peringkat
- Online Documentation For Altium Products - ( (High Speed Design in Altium Designer) ) - AD - 2018-10-26Dokumen27 halamanOnline Documentation For Altium Products - ( (High Speed Design in Altium Designer) ) - AD - 2018-10-26Marco I100% (1)
- Minor Project On FM WirelessDokumen10 halamanMinor Project On FM Wirelesspratik sadiwalaBelum ada peringkat
- Chapter 1 - Database SystemsDokumen34 halamanChapter 1 - Database SystemsDaniel BirhanuBelum ada peringkat
- 4 - Addressing ModesDokumen91 halaman4 - Addressing ModesNoman Saleem100% (1)
- DTMF Based DC Motor Speed and Direction ControlDokumen4 halamanDTMF Based DC Motor Speed and Direction Controlsrinivas raoBelum ada peringkat
- Basic Electronic: V S Imbulpitiya Instructor (Electronic) BSC Electronic and Automation TechnologyDokumen14 halamanBasic Electronic: V S Imbulpitiya Instructor (Electronic) BSC Electronic and Automation TechnologyVindya ImbulpitiyaBelum ada peringkat
- Voice Recognition Using MATLABDokumen6 halamanVoice Recognition Using MATLABWaseem BalochBelum ada peringkat
- 3213 Final Winter2008 SolutionsDokumen17 halaman3213 Final Winter2008 SolutionsMohammedMikhaelYahyaBelum ada peringkat
- OODBMS - ConceptsDokumen9 halamanOODBMS - Conceptssmartbilal5338Belum ada peringkat
- Digital Modulation PDFDokumen41 halamanDigital Modulation PDFPabitraMandalBelum ada peringkat
- Detailed Lesson Plan-DspDokumen6 halamanDetailed Lesson Plan-DspemssietBelum ada peringkat
- Ripple Carry and Carry Lookahead Adders: 1 ObjectivesDokumen8 halamanRipple Carry and Carry Lookahead Adders: 1 ObjectivesYasser RaoufBelum ada peringkat
- Midterm Solution - COSC 3213 - Computer Networks 1Dokumen13 halamanMidterm Solution - COSC 3213 - Computer Networks 1faesalhasanBelum ada peringkat
- CDMA Basics ExplainedDokumen41 halamanCDMA Basics Explaineddainbramaged16Belum ada peringkat
- Problem Set 6 No9.e10b.2017Dokumen16 halamanProblem Set 6 No9.e10b.2017Jason FernandoBelum ada peringkat
- Difference Between PAMDokumen17 halamanDifference Between PAMultra dubsBelum ada peringkat
- Data StructuresDokumen2 halamanData StructuresRajyaLakshmi UppalaBelum ada peringkat
- 8051 Vs Motorola 68HC11Dokumen19 halaman8051 Vs Motorola 68HC11zuanne83Belum ada peringkat
- Multilevel view of a machine's architectureDokumen3 halamanMultilevel view of a machine's architectureVarsha Rani0% (1)
- Basic Shift AccumulatorDokumen4 halamanBasic Shift AccumulatorThahsin ThahirBelum ada peringkat
- EE6602 Notes PDFDokumen79 halamanEE6602 Notes PDFVijayanand SBelum ada peringkat
- Digital Signal Processors and Architectures (DSPA) Unit-2Dokumen92 halamanDigital Signal Processors and Architectures (DSPA) Unit-2Chaitanya DuggineniBelum ada peringkat
- Orthogonal Code Generator For 3G Wireless Transceivers: Boris D. Andreev, Edward L. Titlebaum, and Eby G. FriedmanDokumen4 halamanOrthogonal Code Generator For 3G Wireless Transceivers: Boris D. Andreev, Edward L. Titlebaum, and Eby G. FriedmanSrikanth ChintaBelum ada peringkat
- Mobile Radio Propagation ModelsDokumen5 halamanMobile Radio Propagation ModelsFarEast RamdzanBelum ada peringkat
- Unit-7-Wireless-Modulation-Techniques-And-Hardware Malini MamDokumen40 halamanUnit-7-Wireless-Modulation-Techniques-And-Hardware Malini MamRoopa NayakBelum ada peringkat
- Unit 3 Programmable Digital Signal ProcessorsDokumen25 halamanUnit 3 Programmable Digital Signal ProcessorsPreetham SaigalBelum ada peringkat
- Ec 2252 Communication Theory Lecture NotesDokumen120 halamanEc 2252 Communication Theory Lecture NotesChoco BoxBelum ada peringkat
- Electrical Overstress (EOS): Devices, Circuits and SystemsDari EverandElectrical Overstress (EOS): Devices, Circuits and SystemsBelum ada peringkat
- Understanding UMTS Radio Network Modelling, Planning and Automated Optimisation: Theory and PracticeDari EverandUnderstanding UMTS Radio Network Modelling, Planning and Automated Optimisation: Theory and PracticeMaciej NawrockiBelum ada peringkat
- Emerging Technologies in Information and Communications TechnologyDari EverandEmerging Technologies in Information and Communications TechnologyBelum ada peringkat
- Mathematical Theory of Connecting Networks and Telephone TrafficDari EverandMathematical Theory of Connecting Networks and Telephone TrafficBelum ada peringkat
- Charan SQLDokumen31 halamanCharan SQLNagendra KashyapBelum ada peringkat
- Design of Efficient Multiplier Using VHDLDokumen50 halamanDesign of Efficient Multiplier Using VHDLNagendra KashyapBelum ada peringkat
- Design of Efficient Multiplier Using VHDLDokumen50 halamanDesign of Efficient Multiplier Using VHDLNagendra KashyapBelum ada peringkat
- A Seminar Report Submitted in Partial Fulfillment of The Requirement For The Award of The Degree ofDokumen25 halamanA Seminar Report Submitted in Partial Fulfillment of The Requirement For The Award of The Degree ofNagendra KashyapBelum ada peringkat
- Terminals of Ecm: For M/TDokumen4 halamanTerminals of Ecm: For M/TTdco SonicoBelum ada peringkat
- Ztree 2 StataDokumen3 halamanZtree 2 StataDaniel Felipe ParraBelum ada peringkat
- MastertigACDC 2000 2500 2500W 3500W Om enDokumen33 halamanMastertigACDC 2000 2500 2500W 3500W Om enkhairy2013Belum ada peringkat
- Accidentally Pulled A Remote Branch Into Different Local Branch - How To Undo The Pull?: GitDokumen4 halamanAccidentally Pulled A Remote Branch Into Different Local Branch - How To Undo The Pull?: GitEdouard Francis Dufour DarbellayBelum ada peringkat
- Types of Wind Turbines - Horizontal Axis and Vertical Axis ComparedDokumen1 halamanTypes of Wind Turbines - Horizontal Axis and Vertical Axis Comparedmendhi123Belum ada peringkat
- 32961part Genie Z-45-22Dokumen138 halaman32961part Genie Z-45-22johanaBelum ada peringkat
- X-Arcade Tankstick Manual USADokumen13 halamanX-Arcade Tankstick Manual USAmight69Belum ada peringkat
- LRP I Approved ProjectsDokumen1 halamanLRP I Approved ProjectsTheReviewBelum ada peringkat
- StradaDokumen4 halamanStradayzk14Belum ada peringkat
- 2019 Planning OverviewDokumen7 halaman2019 Planning Overviewapi-323922022Belum ada peringkat
- SUMMER TRAINING REPORT AT Elin Electronics Ltd. Gzb.Dokumen54 halamanSUMMER TRAINING REPORT AT Elin Electronics Ltd. Gzb.Ravi Kumar100% (3)
- File 2 DATN dịch tiếng Anh sang Việt mô hình máy phát điện SEGDokumen28 halamanFile 2 DATN dịch tiếng Anh sang Việt mô hình máy phát điện SEGdangvanthanh150873Belum ada peringkat
- CSD Counter Drone Systems ReportDokumen23 halamanCSD Counter Drone Systems ReportmrkuroiBelum ada peringkat
- NT Photocurre Ed Unmultipli Primary NT Photocurre MultipliedDokumen50 halamanNT Photocurre Ed Unmultipli Primary NT Photocurre Multipliedmayuri sritharanBelum ada peringkat
- Cl60 Rooftop Iom 0213 eDokumen94 halamanCl60 Rooftop Iom 0213 emikexiiBelum ada peringkat
- Jinal Black BookDokumen7 halamanJinal Black Bookhardik patel0% (1)
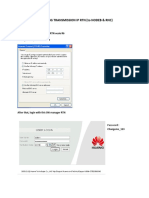
- How to ping NodeB and RNC using RTN transmission IPDokumen14 halamanHow to ping NodeB and RNC using RTN transmission IPPaulo DembiBelum ada peringkat
- Usb Modem 2Dokumen4 halamanUsb Modem 2emadBelum ada peringkat
- 1993 - Distillation Column TargetsDokumen12 halaman1993 - Distillation Column TargetsOctaviano Maria OscarBelum ada peringkat
- Manajemen Berbasis Nilai, Studi Atas Penerapan Manajemen Berbasis NilaiDokumen20 halamanManajemen Berbasis Nilai, Studi Atas Penerapan Manajemen Berbasis NilaitsfBelum ada peringkat
- High Surge Energy Non-Inductive Compact Size: U Series ResistorsDokumen2 halamanHigh Surge Energy Non-Inductive Compact Size: U Series ResistorsYouness Ben TibariBelum ada peringkat
- 3530 Nellikuppam Clarifier SpecDokumen62 halaman3530 Nellikuppam Clarifier Specgopalakrishnannrm1202100% (1)
- FrlsDokumen25 halamanFrlssudeepjosephBelum ada peringkat
- Mahindra and Mahindra PPT LibreDokumen11 halamanMahindra and Mahindra PPT LibreMeet DevganiaBelum ada peringkat
- LOR Engineering Excellence Journal 2013Dokumen77 halamanLOR Engineering Excellence Journal 2013marcinek77Belum ada peringkat
- Images and Color: Summary: SourcesDokumen18 halamanImages and Color: Summary: Sourcesethiopia hagereBelum ada peringkat
- Space Exploration-DebateDokumen2 halamanSpace Exploration-Debateadhil afsalBelum ada peringkat
- Hydraulic Excavator GuideDokumen9 halamanHydraulic Excavator Guidewritetojs100% (1)
- THE PASSION AND GLOBAL APPROACH DRIVING HONDA MOTORCYCLES TO SUCCESSDokumen11 halamanTHE PASSION AND GLOBAL APPROACH DRIVING HONDA MOTORCYCLES TO SUCCESSjatinag990Belum ada peringkat
- FC102 Pid PDFDokumen1 halamanFC102 Pid PDFKwameOpareBelum ada peringkat