Anda mungkin juga menyukai
- Hadoop Trainting in Hyderabad@KellyTechnologiesDokumen23 halamanHadoop Trainting in Hyderabad@KellyTechnologieskellytechnologiesBelum ada peringkat
- Hadoop Trainting in Hyderabad@KellyTechnologiesDokumen23 halamanHadoop Trainting in Hyderabad@KellyTechnologieskellytechnologiesBelum ada peringkat
- Hadoop Training in HyderabadDokumen49 halamanHadoop Training in HyderabadkellytechnologiesBelum ada peringkat
- Hadoop Training Institutes in HyderabadDokumen55 halamanHadoop Training Institutes in HyderabadkellytechnologiesBelum ada peringkat
- Hadoop Training in Hyderabad@KellyTechnologiesDokumen48 halamanHadoop Training in Hyderabad@KellyTechnologieskellytechnologiesBelum ada peringkat
- Hadoop Training in Hyderabad@kellytechnologiesDokumen47 halamanHadoop Training in Hyderabad@kellytechnologieskellytechnologiesBelum ada peringkat
- Data Science Institutes in HyderabadDokumen18 halamanData Science Institutes in HyderabadkellytechnologiesBelum ada peringkat
- Hadoop Training in HyderabadDokumen40 halamanHadoop Training in HyderabadkellytechnologiesBelum ada peringkat
- Hadoop Training Institutes in Hyderabad@KellytechnologiesDokumen26 halamanHadoop Training Institutes in Hyderabad@KellytechnologieskellytechnologiesBelum ada peringkat
- Data Science Training Institute in HyderabadDokumen14 halamanData Science Training Institute in HyderabadkellytechnologiesBelum ada peringkat
- Hadoop Training in BangaloreDokumen1 halamanHadoop Training in BangalorekellytechnologiesBelum ada peringkat
- Hadoop Training in Hyderabad - Hadoop File SystemDokumen5 halamanHadoop Training in Hyderabad - Hadoop File SystemkellytechnologiesBelum ada peringkat
- Data Science Training in HyderabadDokumen24 halamanData Science Training in HyderabadkellytechnologiesBelum ada peringkat
- Hadoop Training Institute in BangaloreDokumen36 halamanHadoop Training Institute in BangalorekellytechnologiesBelum ada peringkat
- Hadoop Training in BangaloreDokumen8 halamanHadoop Training in BangalorekellytechnologiesBelum ada peringkat
- Hadoop Institutes in HyderabadDokumen51 halamanHadoop Institutes in HyderabadkellytechnologiesBelum ada peringkat
- Apache Hadoop Training in HyderabadDokumen6 halamanApache Hadoop Training in HyderabadkellytechnologiesBelum ada peringkat
- Oracle Training Institutes in HyderabadDokumen31 halamanOracle Training Institutes in HyderabadkellytechnologiesBelum ada peringkat
- SAS Training in HyderabadDokumen27 halamanSAS Training in HyderabadkellytechnologiesBelum ada peringkat
- Hadoop Training in BangaloreDokumen1 halamanHadoop Training in BangalorekellytechnologiesBelum ada peringkat
- Hadoop Training Institute in BangaloreDokumen36 halamanHadoop Training Institute in BangalorekellytechnologiesBelum ada peringkat
- Oracle Training Institute in HyderabadDokumen46 halamanOracle Training Institute in HyderabadkellytechnologiesBelum ada peringkat
- Hadoop Training in Bangalore-KellytechnologiesDokumen17 halamanHadoop Training in Bangalore-KellytechnologieskellytechnologiesBelum ada peringkat
- Hadoop Training in BangaloreDokumen38 halamanHadoop Training in BangalorekellytechnologiesBelum ada peringkat
- Hadoop Training in BangaloreDokumen6 halamanHadoop Training in BangalorekellytechnologiesBelum ada peringkat
- Websphere MB Training in HyderabadDokumen2 halamanWebsphere MB Training in HyderabadkellytechnologiesBelum ada peringkat
- Salesforce CRM Training in BangaloreDokumen2 halamanSalesforce CRM Training in BangalorekellytechnologiesBelum ada peringkat
- Hadoop Training Institutes in BangaloreDokumen21 halamanHadoop Training Institutes in BangalorekellytechnologiesBelum ada peringkat
- Shoe Dog: A Memoir by the Creator of NikeDari EverandShoe Dog: A Memoir by the Creator of NikePenilaian: 4.5 dari 5 bintang4.5/5 (537)
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeDari EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifePenilaian: 4 dari 5 bintang4/5 (5794)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceDari EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RacePenilaian: 4 dari 5 bintang4/5 (890)
- The Yellow House: A Memoir (2019 National Book Award Winner)Dari EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Penilaian: 4 dari 5 bintang4/5 (98)
- The Little Book of Hygge: Danish Secrets to Happy LivingDari EverandThe Little Book of Hygge: Danish Secrets to Happy LivingPenilaian: 3.5 dari 5 bintang3.5/5 (399)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryDari EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryPenilaian: 3.5 dari 5 bintang3.5/5 (231)
- Never Split the Difference: Negotiating As If Your Life Depended On ItDari EverandNever Split the Difference: Negotiating As If Your Life Depended On ItPenilaian: 4.5 dari 5 bintang4.5/5 (838)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureDari EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FuturePenilaian: 4.5 dari 5 bintang4.5/5 (474)
- Rise of ISIS: A Threat We Can't IgnoreDari EverandRise of ISIS: A Threat We Can't IgnorePenilaian: 3.5 dari 5 bintang3.5/5 (137)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersDari EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersPenilaian: 4.5 dari 5 bintang4.5/5 (344)
- Grit: The Power of Passion and PerseveranceDari EverandGrit: The Power of Passion and PerseverancePenilaian: 4 dari 5 bintang4/5 (587)
- On Fire: The (Burning) Case for a Green New DealDari EverandOn Fire: The (Burning) Case for a Green New DealPenilaian: 4 dari 5 bintang4/5 (73)
- The Emperor of All Maladies: A Biography of CancerDari EverandThe Emperor of All Maladies: A Biography of CancerPenilaian: 4.5 dari 5 bintang4.5/5 (271)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaDari EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaPenilaian: 4.5 dari 5 bintang4.5/5 (265)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreDari EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You ArePenilaian: 4 dari 5 bintang4/5 (1090)
- Team of Rivals: The Political Genius of Abraham LincolnDari EverandTeam of Rivals: The Political Genius of Abraham LincolnPenilaian: 4.5 dari 5 bintang4.5/5 (234)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyDari EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyPenilaian: 3.5 dari 5 bintang3.5/5 (2219)
- The Unwinding: An Inner History of the New AmericaDari EverandThe Unwinding: An Inner History of the New AmericaPenilaian: 4 dari 5 bintang4/5 (45)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)Dari EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Penilaian: 4.5 dari 5 bintang4.5/5 (119)
- Her Body and Other Parties: StoriesDari EverandHer Body and Other Parties: StoriesPenilaian: 4 dari 5 bintang4/5 (821)
- Noise Pollution Control Policy IndiaDokumen10 halamanNoise Pollution Control Policy IndiaAllu GiriBelum ada peringkat
- UT Dallas Syllabus For Chem2323.001.10s Taught by Sergio Cortes (Scortes)Dokumen9 halamanUT Dallas Syllabus For Chem2323.001.10s Taught by Sergio Cortes (Scortes)UT Dallas Provost's Technology GroupBelum ada peringkat
- ICE Professional Review GuidanceDokumen23 halamanICE Professional Review Guidancerahulgehlot2008Belum ada peringkat
- Conduct effective meetings with the right typeDokumen5 halamanConduct effective meetings with the right typeRio AlbaricoBelum ada peringkat
- VET PREVENTIVE MEDICINE EXAMDokumen8 halamanVET PREVENTIVE MEDICINE EXAMashish kumarBelum ada peringkat
- Week 10 8th Grade Colonial America The Southern Colonies Unit 2Dokumen4 halamanWeek 10 8th Grade Colonial America The Southern Colonies Unit 2santi marcucciBelum ada peringkat
- SOP For Storage of Temperature Sensitive Raw MaterialsDokumen3 halamanSOP For Storage of Temperature Sensitive Raw MaterialsSolomonBelum ada peringkat
- Literature Circles Secondary SolutionsDokumen2 halamanLiterature Circles Secondary Solutionsapi-235368198Belum ada peringkat
- 28 Nakshatras - The Real Secrets of Vedic Astrology (An E-Book)Dokumen44 halaman28 Nakshatras - The Real Secrets of Vedic Astrology (An E-Book)Karthik Balasundaram88% (8)
- Registration Form: Advancement in I.C.Engine and Vehicle System"Dokumen2 halamanRegistration Form: Advancement in I.C.Engine and Vehicle System"Weld TechBelum ada peringkat
- Remotely Operated Underwater Vehicle With 6DOF Robotic ArmDokumen14 halamanRemotely Operated Underwater Vehicle With 6DOF Robotic ArmMethun RajBelum ada peringkat
- Guidance for Processing SushiDokumen24 halamanGuidance for Processing SushigsyaoBelum ada peringkat
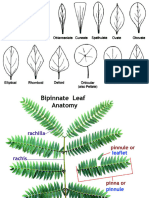
- Types, Shapes and MarginsDokumen10 halamanTypes, Shapes and MarginsAkhil KanukulaBelum ada peringkat
- 09 User Guide Xentry Diagnosis Kit 4 enDokumen118 halaman09 User Guide Xentry Diagnosis Kit 4 enDylan DY100% (2)
- Ariston Oven ManualDokumen16 halamanAriston Oven ManualJoanne JoanneBelum ada peringkat
- Revised Organizational Structure of Railway BoardDokumen4 halamanRevised Organizational Structure of Railway BoardThirunavukkarasu ThirunavukkarasuBelum ada peringkat
- Value Creation-How-Can-The-Semiconductor-Industry-Keep-Outperforming-FinalDokumen7 halamanValue Creation-How-Can-The-Semiconductor-Industry-Keep-Outperforming-FinalJoão Vitor RibeiroBelum ada peringkat
- BiOWiSH Crop OverviewDokumen2 halamanBiOWiSH Crop OverviewBrian MassaBelum ada peringkat
- Test Initial Engleza A 8a Cu Matrice Si BaremDokumen4 halamanTest Initial Engleza A 8a Cu Matrice Si BaremTatiana BeileșenBelum ada peringkat
- Integrative Paper Unfolding The SelfDokumen11 halamanIntegrative Paper Unfolding The SelfTrentox XXXBelum ada peringkat
- Schneider Electric Strategy PresentationDokumen10 halamanSchneider Electric Strategy PresentationDeepie KaurBelum ada peringkat
- Talha Farooqi - Assignment 01 - Overview of Bond Sectors and Instruments - Fixed Income Analysis PDFDokumen4 halamanTalha Farooqi - Assignment 01 - Overview of Bond Sectors and Instruments - Fixed Income Analysis PDFMohammad TalhaBelum ada peringkat
- MS0800288 Angh enDokumen5 halamanMS0800288 Angh enSeason AkhirBelum ada peringkat
- 11th House of IncomeDokumen9 halaman11th House of IncomePrashanth Rai0% (1)
- A.A AntagonismDokumen19 halamanA.A Antagonismjraj030_2k6Belum ada peringkat
- FAQs MHA RecruitmentDokumen6 halamanFAQs MHA RecruitmentRohit AgrawalBelum ada peringkat
- Jeff Roth CVDokumen3 halamanJeff Roth CVJoseph MooreBelum ada peringkat
- Bill of QuantitiesDokumen25 halamanBill of QuantitiesOrnelAsperas100% (2)
- Christian Ministry Books: 00-OrientationGuideDokumen36 halamanChristian Ministry Books: 00-OrientationGuideNessieBelum ada peringkat
- IFM Goodweek Tires, Inc.Dokumen2 halamanIFM Goodweek Tires, Inc.Desalegn Baramo GEBelum ada peringkat