Anda mungkin juga menyukai
- Seminar On Artificial Neural Networks ReportDokumen24 halamanSeminar On Artificial Neural Networks ReportRobel AsfawBelum ada peringkat
- Reconstruction of Virtual Neural Circuits in An Insect BrainDokumen8 halamanReconstruction of Virtual Neural Circuits in An Insect BrainnithiananthiBelum ada peringkat
- Neural NetworksDokumen32 halamanNeural Networksshaik saidaBelum ada peringkat
- Neural NetworksDokumen459 halamanNeural NetworksemregncBelum ada peringkat
- Artificial Neural Networks: Part 1/3Dokumen25 halamanArtificial Neural Networks: Part 1/3Renganathan rameshBelum ada peringkat
- Artificial Neural NetworkDokumen8 halamanArtificial Neural NetworkRoyalRon Yoga PrabhuBelum ada peringkat
- Machine LearningDokumen9 halamanMachine LearningNishantRajBelum ada peringkat
- 18 - Thalamus and Limbic System (Edited)Dokumen22 halaman18 - Thalamus and Limbic System (Edited)Fotocopias LulisBelum ada peringkat
- Neural Networks and Deep LearningDokumen50 halamanNeural Networks and Deep LearningYash ChoudharyBelum ada peringkat
- Matlab Deep Learning SeriesDokumen6 halamanMatlab Deep Learning Serieszym1003Belum ada peringkat
- Understanding Activation Functions in Neural NetworksDokumen15 halamanUnderstanding Activation Functions in Neural Networkswendu felekeBelum ada peringkat
- CNN Architectures AnalyzedDokumen54 halamanCNN Architectures AnalyzedRaahul SinghBelum ada peringkat
- Machine Learning: An IntroductionDokumen23 halamanMachine Learning: An IntroductionPranjalBelum ada peringkat
- TutorialOnNeuralModelingSystems 2Dokumen10 halamanTutorialOnNeuralModelingSystems 2iky770% (1)
- Neural Network ReportDokumen27 halamanNeural Network ReportSiddharth PatelBelum ada peringkat
- Hybrid Neural Network Architecture and ApplicationsDokumen13 halamanHybrid Neural Network Architecture and ApplicationsbalashivasriBelum ada peringkat
- Unit 4 - Neural Networks PDFDokumen12 halamanUnit 4 - Neural Networks PDFflorinciriBelum ada peringkat
- Brainmachineinterfaceengineering PDFDokumen246 halamanBrainmachineinterfaceengineering PDFAndrei LazarBelum ada peringkat
- Final PPTDokumen44 halamanFinal PPTSukhwinder singhBelum ada peringkat
- Back Propagation Network Title OptimizationDokumen29 halamanBack Propagation Network Title OptimizationalvinvergheseBelum ada peringkat
- 174 The Brain From Inside Out 135: Chapter 5. Internalization of ExperienceDokumen20 halaman174 The Brain From Inside Out 135: Chapter 5. Internalization of ExperiencejuannnnBelum ada peringkat
- Basic Concepts in Information Theory ExplainedDokumen111 halamanBasic Concepts in Information Theory Explainedchintar2100% (1)
- Principles of Neural Information TheoryDokumen54 halamanPrinciples of Neural Information TheoryHalyna OliinykBelum ada peringkat
- Neural Networks Fuzzy Logic and Genetic Algorithms Synthesis and Applications EbookDokumen4 halamanNeural Networks Fuzzy Logic and Genetic Algorithms Synthesis and Applications EbookDhrubajyoti DasBelum ada peringkat
- A Guide To Convolutional Neural NetworksDokumen209 halamanA Guide To Convolutional Neural NetworksExStranger100% (1)
- Cognitive Computational NeuroscienceDokumen31 halamanCognitive Computational Neuroscienceocal maviliBelum ada peringkat
- Unsupervised LearningDokumen29 halamanUnsupervised LearningUddalak BanerjeeBelum ada peringkat
- Lecture Neural-Networks ..Dokumen114 halamanLecture Neural-Networks ..Jaya ShuklaBelum ada peringkat
- Back PropagationDokumen33 halamanBack PropagationRoots999Belum ada peringkat
- Data security methods and approaches in cloud computingDokumen3 halamanData security methods and approaches in cloud computingMahimaKadyanBelum ada peringkat
- Learning Law in Neural NetworksDokumen19 halamanLearning Law in Neural NetworksMani Singh100% (2)
- Information Theory and CodingDokumen108 halamanInformation Theory and Codingsimodeb100% (2)
- The Black Hole & Special Theory of RelativityDokumen18 halamanThe Black Hole & Special Theory of RelativitySreedev Vijayan PillaiBelum ada peringkat
- Aboul Ella Hassanien, Ahmad Taher Azar Eds. Brain-Computer Interfaces Current Trends and ApplicationsDokumen422 halamanAboul Ella Hassanien, Ahmad Taher Azar Eds. Brain-Computer Interfaces Current Trends and ApplicationsKeroppi Harry100% (5)
- Neural NetworksDokumen26 halamanNeural NetworksphreedomBelum ada peringkat
- 10 1 1 391 1581Dokumen151 halaman10 1 1 391 1581Papadakis ChristosBelum ada peringkat
- Artificial Neural NetworksDokumen13 halamanArtificial Neural NetworksMudit MisraBelum ada peringkat
- Tutorial Math Deep Learning 2018 PDFDokumen103 halamanTutorial Math Deep Learning 2018 PDFElnur ƏhmədzadəBelum ada peringkat
- Artificial Neural NetworksDokumen43 halamanArtificial Neural NetworksanqrwpoborewBelum ada peringkat
- DeepLearning CompletedDokumen136 halamanDeepLearning CompletedAram ShojaeiBelum ada peringkat
- Time Line of Quantum ComputationDokumen13 halamanTime Line of Quantum ComputationRourav BasakBelum ada peringkat
- DenseNet For Brain Tumor Classification in MRI ImagesDokumen9 halamanDenseNet For Brain Tumor Classification in MRI ImagesInternational Journal of Innovative Science and Research Technology100% (1)
- The Mostly Complete Chart of Neural NetworksDokumen19 halamanThe Mostly Complete Chart of Neural NetworksCarlos Villamizar100% (1)
- Introduction: Introduction To Soft Computing Introduction To Fuzzy Sets and Fuzzy Logic Systems IntroductionDokumen1 halamanIntroduction: Introduction To Soft Computing Introduction To Fuzzy Sets and Fuzzy Logic Systems IntroductionYaksh ShahBelum ada peringkat
- Cerebral Lateralization and Theory of MindDokumen23 halamanCerebral Lateralization and Theory of MindEdgardo100% (3)
- Neural NetworkDokumen220 halamanNeural NetworkMarcos CostaBelum ada peringkat
- Introduction To Neural NetworksDokumen25 halamanIntroduction To Neural NetworksMuhammad Tahir KhaleeqBelum ada peringkat
- Convolutional Neural Networks For Multimedia Sentiment AnalysisDokumen9 halamanConvolutional Neural Networks For Multimedia Sentiment AnalysisTamara KomnenićBelum ada peringkat
- Graph Neural Networks: A Concise IntroductionDokumen22 halamanGraph Neural Networks: A Concise IntroductionArvind RamaduraiBelum ada peringkat
- Artificial Neural Networks Architectures: Edited by Kenji SuzukiDokumen264 halamanArtificial Neural Networks Architectures: Edited by Kenji SuzukiRafael Monteiro100% (1)
- Session 1Dokumen13 halamanSession 1aditya wisnugraha0% (1)
- Jahne B., Handbook of Computer Vision and Applications Vol. 3 Systems and ApplicationsDokumen955 halamanJahne B., Handbook of Computer Vision and Applications Vol. 3 Systems and ApplicationsaDreamerBoyBelum ada peringkat
- Multiple-Layer Networks Backpropagation AlgorithmsDokumen46 halamanMultiple-Layer Networks Backpropagation AlgorithmsZa'imahPermatasariBelum ada peringkat
- 2020 Book ComputationalGeometryTopologyADokumen455 halaman2020 Book ComputationalGeometryTopologyARuixuan ZhouBelum ada peringkat
- Data Communication - NPTELDokumen1.275 halamanData Communication - NPTELnbpr100% (1)
- Brain Tumor Classification Using Machine Learning Mixed ApproachDokumen8 halamanBrain Tumor Classification Using Machine Learning Mixed ApproachIJRASETPublicationsBelum ada peringkat
- Artificial Neural NetworksDokumen14 halamanArtificial Neural NetworksprashantupadhyeBelum ada peringkat
- Artificial Neural Networks For Secondary Structure PredictionDokumen21 halamanArtificial Neural Networks For Secondary Structure PredictionKenen BhandhaviBelum ada peringkat
- SECA4002Dokumen65 halamanSECA4002SivaBelum ada peringkat
- Applicable Artificial Intelligence: Introduction To Neural NetworksDokumen36 halamanApplicable Artificial Intelligence: Introduction To Neural Networksmuhammed suhailBelum ada peringkat
- EEG-132 Pract.Dokumen63 halamanEEG-132 Pract.venkatesan4136Belum ada peringkat
- EMMI - CH 6 - 13092018 - 031526AMDokumen9 halamanEMMI - CH 6 - 13092018 - 031526AMRemix CornerBelum ada peringkat
- Gas & Dye LasersDokumen39 halamanGas & Dye LasersDivya AseejaBelum ada peringkat
- Ei 65 Unit 3Dokumen52 halamanEi 65 Unit 3karthiha12Belum ada peringkat
- Teach Slides10Dokumen43 halamanTeach Slides10Aziz JamaludinBelum ada peringkat
- Biopotential Amplifier Design and ApplicationsDokumen9 halamanBiopotential Amplifier Design and Applicationsagmnm1962Belum ada peringkat
- Biomedical Instrumentation I: DR Muhammad Arif, PHDDokumen43 halamanBiomedical Instrumentation I: DR Muhammad Arif, PHDDivya AseejaBelum ada peringkat
- Lecure-2 Sensors For Biomedical ApplicationsDokumen98 halamanLecure-2 Sensors For Biomedical ApplicationsDivya Aseeja0% (1)
- Ei 65 Unit 3Dokumen52 halamanEi 65 Unit 3karthiha12Belum ada peringkat
- LMP and Nco Psat PaperDokumen14 halamanLMP and Nco Psat PaperDivya AseejaBelum ada peringkat
- Gis Distribution SystemDokumen3 halamanGis Distribution SystemDivya AseejaBelum ada peringkat
- Imitative Learning Based Emotional Controller For Unknown Systems With Unstable EquilibriumDokumen26 halamanImitative Learning Based Emotional Controller For Unknown Systems With Unstable EquilibriumDivya AseejaBelum ada peringkat
- Hybrid GenerationDokumen14 halamanHybrid GenerationDivya AseejaBelum ada peringkat
- Imp PDFDokumen10 halamanImp PDFDivya AseejaBelum ada peringkat
- Opf1 PDFDokumen14 halamanOpf1 PDFDivya AseejaBelum ada peringkat
- Emotional Control of Inverted Pendulum System A Soft Switching From Imitative To Emotional LearningDokumen6 halamanEmotional Control of Inverted Pendulum System A Soft Switching From Imitative To Emotional LearningDivya AseejaBelum ada peringkat
- PowerpointDokumen25 halamanPowerpointBhoomika sardanaBelum ada peringkat
- Colony MorphologyDokumen9 halamanColony MorphologyKirk AdderleyBelum ada peringkat
- General Biology 2: Quarter 1 - Module 1: Recombinant DNADokumen28 halamanGeneral Biology 2: Quarter 1 - Module 1: Recombinant DNACayessier ViernesBelum ada peringkat
- Prokaryotes and EukaryotesDokumen1 halamanProkaryotes and EukaryotesconchoBelum ada peringkat
- READ How A Common Soup ThickenerDokumen4 halamanREAD How A Common Soup ThickenerOgooNkem100% (1)
- Course PlannerDokumen2 halamanCourse PlannerThilankaBelum ada peringkat
- Bruce Trigger - Archaeology and EcologyDokumen17 halamanBruce Trigger - Archaeology and EcologyArmanBelum ada peringkat
- Reaction Paper On The Real EveDokumen2 halamanReaction Paper On The Real EveJoy Marisol Flores ManiaulBelum ada peringkat
- Cobra VenomDokumen29 halamanCobra VenomJohn ShaprioBelum ada peringkat
- Science 10-Pretest Third QuarterDokumen4 halamanScience 10-Pretest Third QuarterCristian PortugalBelum ada peringkat
- OsmosisDokumen11 halamanOsmosisIscariot PriestBelum ada peringkat
- Biology Syllabus For Integrated M.SC Course - Niser Semester 1Dokumen11 halamanBiology Syllabus For Integrated M.SC Course - Niser Semester 1Samyabrata SahaBelum ada peringkat
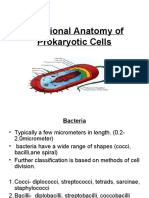
- Functional Anatomy of Prokaryotic CellsDokumen28 halamanFunctional Anatomy of Prokaryotic CellsGabz GabbyBelum ada peringkat
- Worksheet in Mitosis and MeiosisDokumen5 halamanWorksheet in Mitosis and MeiosisJudarlyn Madria0% (1)
- CAPE 2003 BiologyDokumen22 halamanCAPE 2003 BiologyTravis Satnarine33% (3)
- 4 Nucleic Acid HybridizationDokumen23 halaman4 Nucleic Acid HybridizationBalaji Paulraj100% (1)
- La Celula EstresadaDokumen9 halamanLa Celula EstresadaPedro CandelarioBelum ada peringkat
- PLOTKINDokumen6 halamanPLOTKINElPaisUyBelum ada peringkat
- Communities WorksheetDokumen2 halamanCommunities WorksheetJamie MakrisBelum ada peringkat
- Eul 0515 202 00 Covid19 Coronavirus Real Time PCR Kit IfuDokumen28 halamanEul 0515 202 00 Covid19 Coronavirus Real Time PCR Kit IfuashishvaidBelum ada peringkat
- The Clinical Potential of Senolytic DrugsDokumen5 halamanThe Clinical Potential of Senolytic DrugsAmadon FaulBelum ada peringkat
- The developmental project (Unit 1Dokumen3 halamanThe developmental project (Unit 1SKBelum ada peringkat
- Nres1dm-Chapter I and IIDokumen35 halamanNres1dm-Chapter I and IImlmmandapBelum ada peringkat
- Multiple Alleles, Incomplete Dominance, and Codominance (Article) - Khan Academy PDFDokumen13 halamanMultiple Alleles, Incomplete Dominance, and Codominance (Article) - Khan Academy PDFRechelie Alferez ParanBelum ada peringkat
- HistotechniquesDokumen9 halamanHistotechniquesDivineGloryMalbuyoBelum ada peringkat
- GASTROVASCULAR CAVITY AND DIGESTION IN CNIDARIANS AND PLATYHELMINTHESDokumen8 halamanGASTROVASCULAR CAVITY AND DIGESTION IN CNIDARIANS AND PLATYHELMINTHESRuth AsuncionBelum ada peringkat
- Bio 8Dokumen9 halamanBio 8Nazish KhanBelum ada peringkat
- AbstractDokumen4 halamanAbstractDinindu SiriwardeneBelum ada peringkat
- Exercise 8-Life ScienceDokumen2 halamanExercise 8-Life ScienceKarinaBelum ada peringkat
- 20 Soal Latihan Report Text Dalam Bahasa InggrisDokumen6 halaman20 Soal Latihan Report Text Dalam Bahasa InggrisRizkhi CliQuerz Chayanx UnGuBelum ada peringkat