Anda mungkin juga menyukai
- Pilot ViewDokumen2 halamanPilot ViewJad RabhiBelum ada peringkat
- 4-10 Api S 620: Group IDokumen1 halaman4-10 Api S 620: Group ISudarshan GopalBelum ada peringkat
- ASEREP v5.2.0.0Dokumen1 halamanASEREP v5.2.0.0Ali EscobarBelum ada peringkat
- Thermometers: Name: Date: Class: TeacherDokumen2 halamanThermometers: Name: Date: Class: TeacherkulsumBelum ada peringkat
- Konsep Design Rumah 6 X 17-2Dokumen2 halamanKonsep Design Rumah 6 X 17-2anonymoussatu1993Belum ada peringkat
- Air Change Required Per Hour: Whisper SeriesDokumen1 halamanAir Change Required Per Hour: Whisper Seriessuan170Belum ada peringkat
- Bell 206L3 CabinaDokumen1 halamanBell 206L3 CabinajldzombieBelum ada peringkat
- Peta Kontur GemaDokumen1 halamanPeta Kontur Gemavorda buaymadangBelum ada peringkat
- Kaca Wajik - 40cmDokumen1 halamanKaca Wajik - 40cmAdhifian Narendra PutraBelum ada peringkat
- Thermometers: Name: Date: Class: TeacherDokumen2 halamanThermometers: Name: Date: Class: TeacherkulsumBelum ada peringkat
- Tauane Raizila Ferreira Dos Santos-Tauane Raizila Ferreira Dos Santos MandDokumen5 halamanTauane Raizila Ferreira Dos Santos-Tauane Raizila Ferreira Dos Santos Mandtauaneraizila15Belum ada peringkat
- Grade 3 Reading Thermometer BDokumen2 halamanGrade 3 Reading Thermometer BSergio AñoBelum ada peringkat
- Mapa Topografico Nina BolivarDokumen1 halamanMapa Topografico Nina BolivarCamata Flores JesusBelum ada peringkat
- Peta DasarDokumen1 halamanPeta DasarAlfina TrisnawatiBelum ada peringkat
- Sc1-380a, 170608Dokumen1 halamanSc1-380a, 170608fonpereiraBelum ada peringkat
- Contour map of eastern BorneoDokumen1 halamanContour map of eastern Borneovorda buaymadangBelum ada peringkat
- Grade 2 Reading A Thermometer ADokumen2 halamanGrade 2 Reading A Thermometer Ayao shengbangBelum ada peringkat
- Coronavirus - Treatment, Prognosis, Precautions - Handout AtfDokumen1 halamanCoronavirus - Treatment, Prognosis, Precautions - Handout AtfJuan Manuel Tapia AlzateBelum ada peringkat
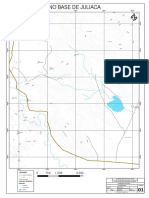
- Plano Base JuliacaDokumen1 halamanPlano Base JuliacaWilliams Nuñez EspetiaBelum ada peringkat
- Schedule of ColumnsDokumen1 halamanSchedule of ColumnsAllan Añavisa Ostique Jr.Belum ada peringkat
- Searchlight Sonar: ModelDokumen4 halamanSearchlight Sonar: Modelsyarifahdwi92Belum ada peringkat
- Spend AnalyticsDokumen14 halamanSpend AnalyticsijjiBelum ada peringkat
- BATIMETRI BITUNG B New-1 PDFDokumen1 halamanBATIMETRI BITUNG B New-1 PDFChristo YakobusBelum ada peringkat
- Manpower-Histogram - Crude Oil Tank - 20-May-2017-1Dokumen1 halamanManpower-Histogram - Crude Oil Tank - 20-May-2017-1sunjeyBelum ada peringkat
- Characteristic Curves UL Listed: Molded Case Circuit BreakersDokumen2 halamanCharacteristic Curves UL Listed: Molded Case Circuit BreakersRodel D DosanoBelum ada peringkat
- Temperatures This WeekDokumen1 halamanTemperatures This WeekMarianela AcebedoBelum ada peringkat
- Comple, Soares, 2019Dokumen11 halamanComple, Soares, 2019SOBelum ada peringkat
- Tables of Noise Transfer Function (Susp Booming Noise)Dokumen11 halamanTables of Noise Transfer Function (Susp Booming Noise)arunapriya soundarBelum ada peringkat
- Monte Carlo Simulations Using Matlab: Vincent Leclercq, Application Engineer Email: Vincent - Leclercq@Dokumen29 halamanMonte Carlo Simulations Using Matlab: Vincent Leclercq, Application Engineer Email: Vincent - Leclercq@Shan DevaBelum ada peringkat
- Grade 3 Reading Thermometer ADokumen2 halamanGrade 3 Reading Thermometer ASergio AñoBelum ada peringkat
- Grade 3 Reading Thermometer ADokumen2 halamanGrade 3 Reading Thermometer ADANA FE RAGATBelum ada peringkat
- STARLINE SELECTION CHARTDokumen99 halamanSTARLINE SELECTION CHARTJohn SmithBelum ada peringkat
- Window design dimensions and specificationsDokumen1 halamanWindow design dimensions and specificationsMeylan SariBelum ada peringkat
- LTAIDokumen104 halamanLTAICihat NuroğluBelum ada peringkat
- Analysis of permeability, porosity and water saturation data from three wellsDokumen755 halamanAnalysis of permeability, porosity and water saturation data from three wellsJean Carlos Quispe De La CruzBelum ada peringkat
- Document with lines, angles, and sheet detailsDokumen1 halamanDocument with lines, angles, and sheet detailsFlonie DensingBelum ada peringkat
- Graphics Plate 1 LINES PDFDokumen1 halamanGraphics Plate 1 LINES PDFFlonie DensingBelum ada peringkat
- SALD-2300: Laser Diffraction Particle Size AnalyzerDokumen20 halamanSALD-2300: Laser Diffraction Particle Size AnalyzerAwais RiazBelum ada peringkat
- Code Tree Occupancy Vs Available HSDPA CodesDokumen2 halamanCode Tree Occupancy Vs Available HSDPA CodesallieBelum ada peringkat
- Asignación de Persinal Y Curva "S"Dokumen2 halamanAsignación de Persinal Y Curva "S"RoberChavarríaCastañedaBelum ada peringkat
- Drawings - ENYAU BRIDGE 2-15mDokumen10 halamanDrawings - ENYAU BRIDGE 2-15mSolomon AhimbisibweBelum ada peringkat
- ANEXO 2 Delimitacion - CajamarquinoDokumen1 halamanANEXO 2 Delimitacion - Cajamarquinovictor chuquiruna bardalesBelum ada peringkat
- 1 - Southern Cross - Iso Pump - 50 X 32 - 160 - 1410-2880 RPM PDFDokumen1 halaman1 - Southern Cross - Iso Pump - 50 X 32 - 160 - 1410-2880 RPM PDFIra LtrBelum ada peringkat
- SEO-Optimized Medical Record TitleDokumen1 halamanSEO-Optimized Medical Record TitleDraDayane RibeiroBelum ada peringkat
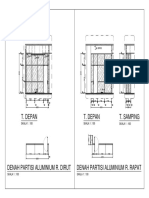
- T. Depan T. Depan T. Samping: SKALA 1: 100 SKALA 1: 100 SKALA 1: 100Dokumen1 halamanT. Depan T. Depan T. Samping: SKALA 1: 100 SKALA 1: 100 SKALA 1: 100Rafik FadlullohBelum ada peringkat
- Print On Paper Type 1 vs. ISO12647-2 Papertype 1 BBDokumen50 halamanPrint On Paper Type 1 vs. ISO12647-2 Papertype 1 BBJorge Luis VelezBelum ada peringkat
- DPSH-P1 M-1, 1 GS ChartReportDokumen1 halamanDPSH-P1 M-1, 1 GS ChartReportJuan Jose Magne ParicolloBelum ada peringkat
- ScritDokumen1 halamanScritYamili BaezBelum ada peringkat
- Delimitación de La Cuenca Yanahuanga: El Ga RRODokumen1 halamanDelimitación de La Cuenca Yanahuanga: El Ga RROJose100% (1)
- Long-term radial velocity variations of solar-type starsDokumen1 halamanLong-term radial velocity variations of solar-type starsPierre-Cécil KönigBelum ada peringkat
- Zechmeister Et Al. 2013 Page 22Dokumen1 halamanZechmeister Et Al. 2013 Page 22Pierre-Cécil KönigBelum ada peringkat
- FOX3-4G Series Flyer v1.1.1Dokumen2 halamanFOX3-4G Series Flyer v1.1.1Tk RachidBelum ada peringkat
- Echipa 4: Efectul cadmiului asupra semințelor de secarăDokumen1 halamanEchipa 4: Efectul cadmiului asupra semințelor de secarăNastasă Diana MădălinaBelum ada peringkat
- 6155 RD Gardi Ujjain 16.02.2024 5Dokumen9 halaman6155 RD Gardi Ujjain 16.02.2024 5ganjtallakeBelum ada peringkat
- Edexcel S1 Revision SheetsDokumen9 halamanEdexcel S1 Revision SheetsBooksBelum ada peringkat
- Grain Size Distribution Graph Aggregate GradationDokumen1 halamanGrain Size Distribution Graph Aggregate GradationchrishoppepeBelum ada peringkat
- 5G Bandwise Throught TrendDokumen6 halaman5G Bandwise Throught TrendabhineetkumarBelum ada peringkat
- Sample Solution Manual For Orbital Mechanics For Engineer 3rd CurtisDokumen16 halamanSample Solution Manual For Orbital Mechanics For Engineer 3rd CurtisSumon SwiftBelum ada peringkat
- Guatemala 2020 Human Rights Report SummaryDokumen35 halamanGuatemala 2020 Human Rights Report SummarySumon SwiftBelum ada peringkat
- Nunavut's Infrastructure GapDokumen259 halamanNunavut's Infrastructure GapNunatsiaqNewsBelum ada peringkat
- ReportDokumen45 halamanReportSumon SwiftBelum ada peringkat
- ElementaryFrenchtheEssentialsofFrenchGrammarWithExercises 10037063Dokumen550 halamanElementaryFrenchtheEssentialsofFrenchGrammarWithExercises 10037063Aryaveer KumarBelum ada peringkat
- A PRIMER ON LIFE IN NUNAVUTDokumen46 halamanA PRIMER ON LIFE IN NUNAVUTSumon SwiftBelum ada peringkat
- Guatemala 2021 Human Rights Report Highlights Widespread ImpunityDokumen46 halamanGuatemala 2021 Human Rights Report Highlights Widespread ImpunitySumon SwiftBelum ada peringkat
- Major Natural Resources of Sylhet Region and Their Economic ImportanceDokumen10 halamanMajor Natural Resources of Sylhet Region and Their Economic ImportanceSumon SwiftBelum ada peringkat
- Dudgeon Asian RiversDokumen27 halamanDudgeon Asian RiversSumon SwiftBelum ada peringkat
- 2022 Sylhet and Habiganj Talent Pool Scholarship RecipientsDokumen79 halaman2022 Sylhet and Habiganj Talent Pool Scholarship RecipientsSumon SwiftBelum ada peringkat
- Theatrein SylhetDokumen7 halamanTheatrein SylhetSumon SwiftBelum ada peringkat
- 19.3.14LargerAsianrivers-Impactsfromhumanactivitiesandclimatechange QI JiangTDokumen5 halaman19.3.14LargerAsianrivers-Impactsfromhumanactivitiesandclimatechange QI JiangTSumon SwiftBelum ada peringkat
- SSC 2019 ScholaDokumen66 halamanSSC 2019 ScholaSumon SwiftBelum ada peringkat
- Final SSC 2018 PDFDokumen70 halamanFinal SSC 2018 PDFWar slashBelum ada peringkat
- A Study On Cadets' EFL Learning Styles Preferences The Case of Sylhet Cadet CollegeDokumen14 halamanA Study On Cadets' EFL Learning Styles Preferences The Case of Sylhet Cadet CollegeSumon SwiftBelum ada peringkat
- Additive Transversality of Fractal Sets in The Reals and The IntegersDokumen51 halamanAdditive Transversality of Fractal Sets in The Reals and The IntegersSumon SwiftBelum ada peringkat
- SIR38 Bridge Planning Design and ConstructionDokumen30 halamanSIR38 Bridge Planning Design and ConstructionSumon SwiftBelum ada peringkat
- MDRBD002FRDokumen13 halamanMDRBD002FRSumon SwiftBelum ada peringkat
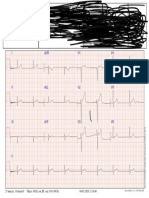
- Jub EcgDokumen1 halamanJub EcgSumon SwiftBelum ada peringkat
- Flood Knowledge and Management in Bangladesh IncreDokumen19 halamanFlood Knowledge and Management in Bangladesh IncreSumon SwiftBelum ada peringkat
- NASA 147432main Hurr Fact SheetDokumen4 halamanNASA 147432main Hurr Fact SheetNASAdocumentsBelum ada peringkat
- Imm5257e PDFDokumen1 halamanImm5257e PDFSumon SwiftBelum ada peringkat
- InvariantDokumen145 halamanInvariantSumon SwiftBelum ada peringkat
- Self-Assessment Program QualityDokumen116 halamanSelf-Assessment Program QualitySumon SwiftBelum ada peringkat
- Sumit KumarDokumen28 halamanSumit KumarSumon SwiftBelum ada peringkat
- Regular If The Following Two Conditions Hold : 1 2 N 1 Ďiďjďn Ij I J IjDokumen23 halamanRegular If The Following Two Conditions Hold : 1 2 N 1 Ďiďjďn Ij I J IjSumon SwiftBelum ada peringkat
- 2007 04290Dokumen89 halaman2007 04290Sumon SwiftBelum ada peringkat
- Cox's Bazar: at A GlanceDokumen2 halamanCox's Bazar: at A GlanceSumon SwiftBelum ada peringkat
- Jub Ecg PDFDokumen1 halamanJub Ecg PDFSumon SwiftBelum ada peringkat
- 981 BangladeshDokumen116 halaman981 BangladeshRashedul Islam RanaBelum ada peringkat
- 2nd Six Weeks Calendar PLCDokumen2 halaman2nd Six Weeks Calendar PLCapi-291820023Belum ada peringkat
- Assignment 2 Kowsika C 19BCS4063Dokumen6 halamanAssignment 2 Kowsika C 19BCS4063KOWSIKA CHANDRANBelum ada peringkat
- Signals and Systems by K. Deergha RaoDokumen434 halamanSignals and Systems by K. Deergha RaoJorge Marcillo100% (1)
- Non Linear Optimization in EENG Lecture - 00Dokumen18 halamanNon Linear Optimization in EENG Lecture - 00Michael Zontche BernardBelum ada peringkat
- StartupML 05-12-2016 Justin Lent PPT SlidesDokumen35 halamanStartupML 05-12-2016 Justin Lent PPT SlidesankiosaBelum ada peringkat
- Ai - Session 1Dokumen40 halamanAi - Session 1arunaradhiBelum ada peringkat
- Practice Final Examination: Final Exam: Tuesday, June 12th, 8:30am-11:30amDokumen11 halamanPractice Final Examination: Final Exam: Tuesday, June 12th, 8:30am-11:30amDaniel NaroditskyBelum ada peringkat
- Lab Sheet 04Dokumen2 halamanLab Sheet 04Hansana RanaweeraBelum ada peringkat
- 2007 YJC Paper 2solDokumen10 halaman2007 YJC Paper 2solYudi KhoBelum ada peringkat
- PRNN P S Sastry Lec 1Dokumen177 halamanPRNN P S Sastry Lec 1Sumit KumarBelum ada peringkat
- Ucs551 Group Project Instructions (Dec 2023)Dokumen7 halamanUcs551 Group Project Instructions (Dec 2023)nur ashfaralianaBelum ada peringkat
- Exam3 SolutionDokumen6 halamanExam3 Solutionowronrawan74Belum ada peringkat
- Topical Test Chapter 1-2 Form 3Dokumen8 halamanTopical Test Chapter 1-2 Form 3Muhammad Hanif Zol Hamidy25% (4)
- Grammar and Machine Transforms: Zeph GrunschlagDokumen93 halamanGrammar and Machine Transforms: Zeph Grunschlagmansha99Belum ada peringkat
- Correlation and RegressionDokumen8 halamanCorrelation and RegressionMD AL-AMINBelum ada peringkat
- Evolutionary Checkers Using Genetic AlgorithmDokumen6 halamanEvolutionary Checkers Using Genetic AlgorithmChirag ThakerBelum ada peringkat
- Generative Pretraining From Pixels V2Dokumen12 halamanGenerative Pretraining From Pixels V2Zaka UllahBelum ada peringkat
- Acceptance Sampling - AttributesDokumen10 halamanAcceptance Sampling - AttributessajinirajithBelum ada peringkat
- PII - Numerical Analysis II - Iserles (2005) 61pg PDFDokumen61 halamanPII - Numerical Analysis II - Iserles (2005) 61pg PDFfdsdsfsdfmgBelum ada peringkat
- Bitcoin ScroogeCoin transactionsDokumen3 halamanBitcoin ScroogeCoin transactionsAnil ShekarBelum ada peringkat
- UVic CS 349A Midterm Exam Mar 11 2019Dokumen4 halamanUVic CS 349A Midterm Exam Mar 11 2019Malcolm FenelonBelum ada peringkat
- Lab4 RBM DBN Extra SlidesDokumen31 halamanLab4 RBM DBN Extra SlidesPrem NathBelum ada peringkat
- Activity 2 - Inventory ManagementDokumen2 halamanActivity 2 - Inventory ManagementfayesandigBelum ada peringkat
- Cracking of DESDokumen7 halamanCracking of DESDeepak MBelum ada peringkat
- Optimize Queries on University DatabaseDokumen4 halamanOptimize Queries on University DatabaseDivyanshu BoseBelum ada peringkat
- MEC4418 - Assignment 1 - SolutionDokumen6 halamanMEC4418 - Assignment 1 - Solutionsamuel_parsooramenBelum ada peringkat
- Statistics 351 Lecture 7: Functions of Multivariate Random VariablesDokumen3 halamanStatistics 351 Lecture 7: Functions of Multivariate Random VariablesmohamedBelum ada peringkat
- Multilabel Classification Problem Analysis Metrics and Techniques PDFDokumen200 halamanMultilabel Classification Problem Analysis Metrics and Techniques PDFiamadnanBelum ada peringkat
- Java BookDokumen148 halamanJava Bookapi-3836128100% (1)
- AC Servo Motor Speed and Position Control Using PSODokumen7 halamanAC Servo Motor Speed and Position Control Using PSONoel BinoyBelum ada peringkat