Anda mungkin juga menyukai
- Classification Using RDokumen9 halamanClassification Using RsaurabhBelum ada peringkat
- Module V 1Dokumen7 halamanModule V 1Animesh MandalBelum ada peringkat
- Nomor 3 UtsDokumen6 halamanNomor 3 UtsNita FerdianaBelum ada peringkat
- BRM FileDokumen20 halamanBRM FilegarvbarrejaBelum ada peringkat
- Stats Lab1Dokumen11 halamanStats Lab1Chetan CherryBelum ada peringkat
- C1S1 Statistics PacketDokumen24 halamanC1S1 Statistics PacketPrathyusha KorrapatiBelum ada peringkat
- Introduction to R for Data AnalysisDokumen37 halamanIntroduction to R for Data AnalysisDIVYANSH GAUR (RA2011027010090)Belum ada peringkat
- Materi PraktikumDokumen7 halamanMateri PraktikumNurulRahmaBelum ada peringkat
- Advanced R Data Analysis Training PDFDokumen72 halamanAdvanced R Data Analysis Training PDFAnonymous NoermyAEpdBelum ada peringkat
- Stat HandoutDokumen7 halamanStat HandoutJenrick DimayugaBelum ada peringkat
- BIOSTATISTICSDokumen14 halamanBIOSTATISTICSSuhail KhanBelum ada peringkat
- Cluster Analysis in R TMLDokumen5 halamanCluster Analysis in R TMLRajyaLakshmiBelum ada peringkat
- Sta NotesDokumen44 halamanSta NotesManshal BrohiBelum ada peringkat
- Math Written Reportgroup 4 PDFDokumen18 halamanMath Written Reportgroup 4 PDFJaynerale EnriquezBelum ada peringkat
- Data Mining Graded Assignment AnalysisDokumen39 halamanData Mining Graded Assignment Analysisrakesh sandhyapogu100% (3)
- Data Visualization Notes-2Dokumen223 halamanData Visualization Notes-2luckykaushal2018Belum ada peringkat
- Business Report Predicts Voter BehaviorDokumen77 halamanBusiness Report Predicts Voter BehaviorRupesh GaurBelum ada peringkat
- 7 QC ToolsDokumen14 halaman7 QC ToolsshashikantjoshiBelum ada peringkat
- Toaz - Info Ge 4 Topic 2 Statistics PRDokumen11 halamanToaz - Info Ge 4 Topic 2 Statistics PRMyname IsBelum ada peringkat
- Ge 4 Topic 2-StatisticsDokumen11 halamanGe 4 Topic 2-StatisticsAthena Pacaña67% (3)
- Lab Plan 5: Statistics and Probability - Describing a Single Set of DataDokumen19 halamanLab Plan 5: Statistics and Probability - Describing a Single Set of DataSteffen ColeBelum ada peringkat
- TutorialsDokumen10 halamanTutorialsGutaBelum ada peringkat
- 41 Perusse Alexander Aperusse PDFDokumen7 halaman41 Perusse Alexander Aperusse PDFAnurita MathurBelum ada peringkat
- KVA Anusha - PGP12021 - BADokumen8 halamanKVA Anusha - PGP12021 - BAAditi Pareek100% (1)
- R Tutorial: K-Means Cluster Analysis of Iris Data SetDokumen8 halamanR Tutorial: K-Means Cluster Analysis of Iris Data SetPalash SarowareBelum ada peringkat
- Basic Stats ConceptsDokumen5 halamanBasic Stats Conceptssantosh raazBelum ada peringkat
- Calculating Standard Error Bars For A GraphDokumen6 halamanCalculating Standard Error Bars For A GraphKona MenyongaBelum ada peringkat
- Algoritma Academy: Practical Statistics: BackgroundDokumen19 halamanAlgoritma Academy: Practical Statistics: BackgrounddamarbrianBelum ada peringkat
- Pacific Southbay College statistics moduleDokumen10 halamanPacific Southbay College statistics moduleAron AdarsonBelum ada peringkat
- Probability and Stochastic Process-5Dokumen19 halamanProbability and Stochastic Process-5Neha NadeemBelum ada peringkat
- Exploratory Data Analysis, Variation, Missing Values, CovariationDokumen22 halamanExploratory Data Analysis, Variation, Missing Values, CovariationkeexuepinBelum ada peringkat
- Illustration of Using Excel To Find Maximum Likelihood EstimatesDokumen14 halamanIllustration of Using Excel To Find Maximum Likelihood EstimatesRustam MuhammadBelum ada peringkat
- BSChem-Statistics in Chemical Analysis PDFDokumen6 halamanBSChem-Statistics in Chemical Analysis PDFKENT BENEDICT PERALESBelum ada peringkat
- DSUR Chapter 04 Web MaterialDokumen19 halamanDSUR Chapter 04 Web MaterialAlice SwanBelum ada peringkat
- Lect6 - Data Handling-2-20Dokumen19 halamanLect6 - Data Handling-2-20Mitesh BhagwatBelum ada peringkat
- Central Tendancy Mac1Dokumen7 halamanCentral Tendancy Mac1api-289683243Belum ada peringkat
- Project in DSA JavaDokumen5 halamanProject in DSA JavaHitesh ReddyBelum ada peringkat
- 08 Decision - TreeDokumen9 halaman08 Decision - TreeGabriel GheorgheBelum ada peringkat
- Statistical Analysis and Software ApplicationDokumen11 halamanStatistical Analysis and Software ApplicationDan Edriel RonabioBelum ada peringkat
- Statistics Definitions And ExamplesDokumen10 halamanStatistics Definitions And ExamplesMary Grace MoralBelum ada peringkat
- Data Cleansing Using RDokumen10 halamanData Cleansing Using RDaniel N Sherine Foo0% (1)
- IT0089 TB391 Decision Tree RABEDokumen6 halamanIT0089 TB391 Decision Tree RABEKim VincereBelum ada peringkat
- Lesson 7 - Measure of Central TendencyDokumen11 halamanLesson 7 - Measure of Central TendencyriniBelum ada peringkat
- Notes On Data Processing, Analysis, PresentationDokumen63 halamanNotes On Data Processing, Analysis, Presentationjaneth pallangyoBelum ada peringkat
- Sentiment Analysis of Movie Reviews Using Bag of WordsDokumen11 halamanSentiment Analysis of Movie Reviews Using Bag of Wordsudhai170819Belum ada peringkat
- Introduction to basic statistics conceptsDokumen11 halamanIntroduction to basic statistics conceptsrssarmaBelum ada peringkat
- Summarizing DataDokumen13 halamanSummarizing DataNitish RavuvariBelum ada peringkat
- 4 - Statistik DeskriptifDokumen33 halaman4 - Statistik DeskriptifDhe NurBelum ada peringkat
- VectorsDokumen11 halamanVectorsNur SyazlianaBelum ada peringkat
- Report Stats PDFDokumen23 halamanReport Stats PDFSid Ra RajpootBelum ada peringkat
- Lesson 3 EdtechDokumen8 halamanLesson 3 Edtechapi-268563289Belum ada peringkat
- Introduction To StatsDokumen13 halamanIntroduction To StatsMuhammad Moazzam FaizBelum ada peringkat
- Evaluating Analytical ChemistryDokumen4 halamanEvaluating Analytical ChemistryArjune PantallanoBelum ada peringkat
- Assignment 1 MidtermDokumen5 halamanAssignment 1 MidtermPatricia Jane CabangBelum ada peringkat
- Standard Deviation FormulasDokumen10 halamanStandard Deviation FormulasDhaval ShahBelum ada peringkat
- Smda Unit IIIDokumen80 halamanSmda Unit IIIRagha RamojuBelum ada peringkat
- Linear Regression Chp1Dokumen102 halamanLinear Regression Chp1thermopolis3012Belum ada peringkat
- Data Mining Project DSBA PCA Report FinalDokumen21 halamanData Mining Project DSBA PCA Report Finalindraneel120Belum ada peringkat
- Introduction To Business Statistics Through R Software: SoftwareDari EverandIntroduction To Business Statistics Through R Software: SoftwareBelum ada peringkat
- S Ved Ka Data DictionaryDokumen1 halamanS Ved Ka Data DictionaryNabanita GhoshBelum ada peringkat
- Notes On Cluster AnalysisDokumen15 halamanNotes On Cluster AnalysisNabanita GhoshBelum ada peringkat
- Proctor & GambleDokumen9 halamanProctor & GambleevomainaBelum ada peringkat
- Introduction To Data Analysis: Professor David Richardson IIT Stuart School of BusinessDokumen31 halamanIntroduction To Data Analysis: Professor David Richardson IIT Stuart School of BusinessNabanita GhoshBelum ada peringkat
- BBBC Presntation PDFDokumen51 halamanBBBC Presntation PDFNabanita Ghosh100% (1)
- MacPherson RefrigerationDokumen1 halamanMacPherson RefrigerationNabanita GhoshBelum ada peringkat
- ABB Electric Segmentation Case TEAM 4Dokumen11 halamanABB Electric Segmentation Case TEAM 4Rohini Runfola0% (1)
- MacPherson RefrigerationDokumen1 halamanMacPherson RefrigerationNabanita GhoshBelum ada peringkat
- Inspired Endeavors S19Dokumen1 halamanInspired Endeavors S19Nabanita GhoshBelum ada peringkat
- ABB Electric Segmentation Case TEAM 4Dokumen91 halamanABB Electric Segmentation Case TEAM 4Nabanita GhoshBelum ada peringkat
- MacPherson Refrigeration GuidelinesDokumen2 halamanMacPherson Refrigeration GuidelinesNabanita GhoshBelum ada peringkat
- Red Brand Canners CaseDokumen4 halamanRed Brand Canners CaseNabanita GhoshBelum ada peringkat
- Group Members:-Imran Rashid Riya Kumari Nabanita Ghosh Samrat GhoshDokumen22 halamanGroup Members:-Imran Rashid Riya Kumari Nabanita Ghosh Samrat GhoshNabanita GhoshBelum ada peringkat
- Introduction To R - Lecture 1Dokumen22 halamanIntroduction To R - Lecture 1Nabanita GhoshBelum ada peringkat
- Syllabus - Economics, Summer Session1 2017-1Dokumen4 halamanSyllabus - Economics, Summer Session1 2017-1Nabanita GhoshBelum ada peringkat
- Projects Infosys CCGC April 2013Dokumen6 halamanProjects Infosys CCGC April 2013Nabanita GhoshBelum ada peringkat
- ABB Electric Segmentation Case TEAM 4Dokumen11 halamanABB Electric Segmentation Case TEAM 4Rohini Runfola0% (1)
- Yesterday's RoutineDokumen1 halamanYesterday's RoutineNabanita GhoshBelum ada peringkat
- Group Members:-Imran Rashid Riya Kumari Nabanita Ghosh Samrat GhoshDokumen22 halamanGroup Members:-Imran Rashid Riya Kumari Nabanita Ghosh Samrat GhoshNabanita GhoshBelum ada peringkat
- CSCE 3110 Data Structures & Algorithm Analysis: Rada MihalceaDokumen18 halamanCSCE 3110 Data Structures & Algorithm Analysis: Rada MihalceaVicky ButtBelum ada peringkat
- Johnny Appleseed - Apple Life Cycle Lesson PlanDokumen3 halamanJohnny Appleseed - Apple Life Cycle Lesson Planapi-267446628Belum ada peringkat
- N-Series For 802.1x and Dynamic ACL Scenario With Cisco ISEDokumen6 halamanN-Series For 802.1x and Dynamic ACL Scenario With Cisco ISEnestelBelum ada peringkat
- Reference-6 2 0-1Dokumen1.885 halamanReference-6 2 0-1Chigo AryaBelum ada peringkat
- Translating English Words Into Algebraic ExpressionsDokumen2 halamanTranslating English Words Into Algebraic ExpressionsShendy L. TamayoBelum ada peringkat
- Differential Calculus Unit III - Beta and Gamma FunctionsDokumen27 halamanDifferential Calculus Unit III - Beta and Gamma FunctionsSatuluri Satyanagendra RaoBelum ada peringkat
- MAPEHDokumen1 halamanMAPEHPrincess haifa MustaphaBelum ada peringkat
- RPP Sebelum Plan Advanced English Grammar PrepositionsDokumen2 halamanRPP Sebelum Plan Advanced English Grammar PrepositionsRafli NurusyaikaBelum ada peringkat
- Revised - Common and Proper Nouns - AnjaliDokumen4 halamanRevised - Common and Proper Nouns - AnjaliAstro28Belum ada peringkat
- PRACTICE TEST 6 - Bài LàmDokumen8 halamanPRACTICE TEST 6 - Bài LàmLê Quốc KhánhBelum ada peringkat
- Web Lecture # 3 (Javascript Introduction)Dokumen28 halamanWeb Lecture # 3 (Javascript Introduction)Raja DaniyalBelum ada peringkat
- Snee Snoo Snake Game Turbo Pascal CodeDokumen28 halamanSnee Snoo Snake Game Turbo Pascal CodebruesBelum ada peringkat
- M.Khorasani Consulting & Publishing: Persian Swords in The State Hermitage Museum (Saint Petersburg 2015)Dokumen14 halamanM.Khorasani Consulting & Publishing: Persian Swords in The State Hermitage Museum (Saint Petersburg 2015)Deakin DailBelum ada peringkat
- Printed Aids: Miss Nekha Rani P.B.B.SC (N) StudentDokumen11 halamanPrinted Aids: Miss Nekha Rani P.B.B.SC (N) StudentNeha Verma100% (1)
- Deconstructing The RavenDokumen8 halamanDeconstructing The RavenRaisa HateganBelum ada peringkat
- ESOL 100 Intro. To ESOL 100 Grammar ComponentDokumen36 halamanESOL 100 Intro. To ESOL 100 Grammar Componentezramaecacacho20Belum ada peringkat
- Model for calculating sag and tension of composite conductorsDokumen4 halamanModel for calculating sag and tension of composite conductorsDayan YasarangaBelum ada peringkat
- My Mother Loves MeDokumen4 halamanMy Mother Loves MeYasmin Yacob67% (3)
- Veeam Backup ToolDokumen18 halamanVeeam Backup ToolPriyanka JhaBelum ada peringkat
- Raqeeb - Rasheed.msthesis 2007Dokumen106 halamanRaqeeb - Rasheed.msthesis 2007Keka MiraBelum ada peringkat
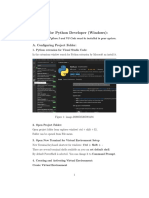
- VSCode Setup For PythonDokumen10 halamanVSCode Setup For PythonKeya GhoshBelum ada peringkat
- JCHAT JchatboxDokumen89 halamanJCHAT JchatboxvamseekrishnakothaBelum ada peringkat
- PERFECT NUMBERS: A HISTORYDokumen11 halamanPERFECT NUMBERS: A HISTORYNikolaj MihaljcisinBelum ada peringkat
- Debating PhrasebankDokumen3 halamanDebating Phrasebankandrew100% (1)
- Precedence. The Personal Pronoun He and The Definite Article The Combined WithDokumen6 halamanPrecedence. The Personal Pronoun He and The Definite Article The Combined WithЮлияBelum ada peringkat
- Action VerbsDokumen19 halamanAction VerbsOrangeSister100% (17)
- Lesson Plan ReadingDokumen4 halamanLesson Plan ReadingnelieltuodeshvankBelum ada peringkat
- Sage TutorialDokumen103 halamanSage TutorialLucian Cionca100% (1)
- Nonfiction Reading Test 3 CastlesDokumen33 halamanNonfiction Reading Test 3 CastlestulipBelum ada peringkat
- Knotter Kabbalah-TheArtofJewishMysticism2018 PDFDokumen33 halamanKnotter Kabbalah-TheArtofJewishMysticism2018 PDFFrancesco67Belum ada peringkat
- J. W. Von Goethe. Wilhelm Meister's ApprenticeshipDokumen337 halamanJ. W. Von Goethe. Wilhelm Meister's ApprenticeshipArturoFrancoRomoBelum ada peringkat