Anda mungkin juga menyukai
- COMP3308/COMP3608 Artificial Intelligence Week 10 Tutorial Exercises Support Vector Machines. Ensembles of ClassifiersDokumen3 halamanCOMP3308/COMP3608 Artificial Intelligence Week 10 Tutorial Exercises Support Vector Machines. Ensembles of ClassifiersharietBelum ada peringkat
- CP 4Dokumen2 halamanCP 4Ankita MishraBelum ada peringkat
- A Brief Introduction To Adaboost: Hongbo Deng 6 Feb, 2007Dokumen35 halamanA Brief Introduction To Adaboost: Hongbo Deng 6 Feb, 2007fsdgsgsBelum ada peringkat
- Bagging and Boosting: Amit Srinet Dave SnyderDokumen33 halamanBagging and Boosting: Amit Srinet Dave Snyderisaias.prestesBelum ada peringkat
- Classification and Clustering: CS109/Stat121/AC209/E-109 Data ScienceDokumen28 halamanClassification and Clustering: CS109/Stat121/AC209/E-109 Data ScienceMatheus SilvaBelum ada peringkat
- Classification and Clustering: CS109/Stat121/AC209/E-109 Data ScienceDokumen28 halamanClassification and Clustering: CS109/Stat121/AC209/E-109 Data ScienceMatheus SilvaBelum ada peringkat
- Exam 2011Dokumen22 halamanExam 2011Anas BachiriBelum ada peringkat
- Lec 05 RegularizationDokumen77 halamanLec 05 RegularizationMr. CoffeeBelum ada peringkat
- Ada BoostDokumen7 halamanAda BoostВалентин ПрокопецBelum ada peringkat
- MISY 631 Final Review Calculators Will Be Provided For The ExamDokumen9 halamanMISY 631 Final Review Calculators Will Be Provided For The ExamAniKelbakianiBelum ada peringkat
- Midterm Solutions PDFDokumen17 halamanMidterm Solutions PDFShayan Ali ShahBelum ada peringkat
- Linear Asymmetric Classifier For Cascade Detectors: Figure 1. Illustration of A Cascade With R NodesDokumen8 halamanLinear Asymmetric Classifier For Cascade Detectors: Figure 1. Illustration of A Cascade With R NodesArtūras KairysBelum ada peringkat
- Lecture15 RegularizationDokumen47 halamanLecture15 RegularizationemanaminBelum ada peringkat
- Adaboost With Totally Corrective Updates For Fast Face DetectionDokumen6 halamanAdaboost With Totally Corrective Updates For Fast Face DetectionNguyen Quoc TrieuBelum ada peringkat
- Training A Binary Classifier With The Quantum Adiabatic AlgorithmDokumen11 halamanTraining A Binary Classifier With The Quantum Adiabatic AlgorithmCaballero Alférez Roy TorresBelum ada peringkat
- Sample Final SolDokumen7 halamanSample Final SolAnshulBelum ada peringkat
- Assignment 2 SpecificationDokumen3 halamanAssignment 2 SpecificationRazinBelum ada peringkat
- Support Vector Machines: Javier B Ejar CbeaDokumen44 halamanSupport Vector Machines: Javier B Ejar CbeachiBelum ada peringkat
- Revisiting Revisiting Logistic Regression & Naïve Logistic Regression & Naïve Bayes BayesDokumen46 halamanRevisiting Revisiting Logistic Regression & Naïve Logistic Regression & Naïve Bayes BayesMarioMateiroMMBelum ada peringkat
- 10-701 Midterm Exam, Fall 2007 Key QuestionsDokumen25 halaman10-701 Midterm Exam, Fall 2007 Key QuestionsJuan VeraBelum ada peringkat
- 12 Deepak Fuzzy Logic SVMDokumen81 halaman12 Deepak Fuzzy Logic SVMRaj LakhaniBelum ada peringkat
- Modest AdaBoostDokumen4 halamanModest AdaBoostLucas GallindoBelum ada peringkat
- BoostDokumen43 halamanBoostGustavo ColimbaBelum ada peringkat
- Lecture 6 Raster AnalysisDokumen33 halamanLecture 6 Raster AnalysisJoseph BaruhiyeBelum ada peringkat
- Raster Analysis Techniques for Measuring, Classifying and Overlaying DataDokumen69 halamanRaster Analysis Techniques for Measuring, Classifying and Overlaying DataMoises JoseBelum ada peringkat
- 10-701/15-781 Machine Learning - Midterm Exam, Fall 2010: Aarti Singh Carnegie Mellon UniversityDokumen15 halaman10-701/15-781 Machine Learning - Midterm Exam, Fall 2010: Aarti Singh Carnegie Mellon Universityale mekeBelum ada peringkat
- Midterm 2010 FDokumen15 halamanMidterm 2010 FMuhammad MurtazaBelum ada peringkat
- Assignment 1Dokumen3 halamanAssignment 1RazinBelum ada peringkat
- Week 6 Lecture NotesDokumen9 halamanWeek 6 Lecture NotesIlhan YunusBelum ada peringkat
- DS ML CompleteSlides PDFDokumen211 halamanDS ML CompleteSlides PDFSemil ChaliawalaBelum ada peringkat
- LogregDokumen26 halamanLogregroy royBelum ada peringkat
- CSC 5825 Intro. To Machine Learning and Applications Midterm ExamDokumen13 halamanCSC 5825 Intro. To Machine Learning and Applications Midterm ExamranaBelum ada peringkat
- Boosting of Support Vector Machines With Application To EditingDokumen7 halamanBoosting of Support Vector Machines With Application To EditingMurugu Jothida NilayamBelum ada peringkat
- Lecture2 PDFDokumen111 halamanLecture2 PDFdineshBelum ada peringkat
- MT1 SP19 SolutionsDokumen14 halamanMT1 SP19 SolutionsHasimBelum ada peringkat
- Logistic+Regression - DoneDokumen41 halamanLogistic+Regression - DonePinaki Ghosh100% (1)
- cs229 Notes EnsembleDokumen7 halamancs229 Notes EnsemblebobBelum ada peringkat
- Handout5 RegularizationDokumen20 halamanHandout5 Regularizationmatthiaskoerner19Belum ada peringkat
- IIT Kanpur Machine Learning End Sem PaperDokumen10 halamanIIT Kanpur Machine Learning End Sem PaperJivnesh SandhanBelum ada peringkat
- Supervised Learning - Support Vector Machines and Feature reductionDokumen11 halamanSupervised Learning - Support Vector Machines and Feature reductionodsnetBelum ada peringkat
- The Cross Entropy Method For ClassificationDokumen8 halamanThe Cross Entropy Method For ClassificationDocente Fede TecnologicoBelum ada peringkat
- Derivada de Una NormaDokumen79 halamanDerivada de Una NormaJuan Carlos Moreno OrtizBelum ada peringkat
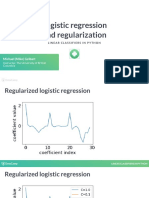
- Logistic Regression and Regularization: Michael (Mike) GelbartDokumen19 halamanLogistic Regression and Regularization: Michael (Mike) GelbartNourheneMbarekBelum ada peringkat
- CPSC 540 Assignment 1 SolutionsDokumen9 halamanCPSC 540 Assignment 1 SolutionsJohnnyDoe0x27ABelum ada peringkat
- Support Vector Machines: Review and Applications in Civil: October 2011Dokumen15 halamanSupport Vector Machines: Review and Applications in Civil: October 2011linoficBelum ada peringkat
- Summary Machine LearningDokumen15 halamanSummary Machine LearningtjBelum ada peringkat
- Rpackages Ianhowson Com Cran Qdap Man Polarity HTMLDokumen53 halamanRpackages Ianhowson Com Cran Qdap Man Polarity HTMLJoseh Tenylson G. RodriguesBelum ada peringkat
- Review Questions DSDokumen14 halamanReview Questions DSSaleh AlizadeBelum ada peringkat
- Learning 2Dokumen104 halamanLearning 2Noel Roy DenjaBelum ada peringkat
- MCQs Dumps 2Dokumen15 halamanMCQs Dumps 2surajBelum ada peringkat
- ML5Dokumen5 halamanML5Anonymous C5ACgu0Belum ada peringkat
- Machine Learning Model Predicts House PricesDokumen9 halamanMachine Learning Model Predicts House PricesEducation VietCoBelum ada peringkat
- (20131209) Practical Examples Using EviewsDokumen46 halaman(20131209) Practical Examples Using EviewsiceineagBelum ada peringkat
- Decision Trees and Boosting: Helge Voss (MPI-K, Heidelberg) TMVA WorkshopDokumen30 halamanDecision Trees and Boosting: Helge Voss (MPI-K, Heidelberg) TMVA WorkshopAshish TiwariBelum ada peringkat
- SVM in MatlabDokumen17 halamanSVM in Matlabtruongvinhlan19895148100% (1)
- Machine Learning (CS-601) Class NotesDokumen17 halamanMachine Learning (CS-601) Class NotesASHOKA KUMARBelum ada peringkat
- K Nearest Neighbor Algorithm: Fundamentals and ApplicationsDari EverandK Nearest Neighbor Algorithm: Fundamentals and ApplicationsBelum ada peringkat
- Backpropagation: Fundamentals and Applications for Preparing Data for Training in Deep LearningDari EverandBackpropagation: Fundamentals and Applications for Preparing Data for Training in Deep LearningBelum ada peringkat
- Molecular Theory and Modeling Molecular Theory NotesDokumen191 halamanMolecular Theory and Modeling Molecular Theory NotesPaulami Lahiry100% (1)
- Project Control RubricDokumen29 halamanProject Control RubricBrekhna JanBelum ada peringkat
- Convolution Encoder Verilog CodeDokumen3 halamanConvolution Encoder Verilog CodeMounesh Panchal50% (4)
- The Exponential Decay and Growth of SkittlesDokumen4 halamanThe Exponential Decay and Growth of Skittlesapi-267852685Belum ada peringkat
- Advanced Algorithms Analysis and Design: Strong InductionDokumen15 halamanAdvanced Algorithms Analysis and Design: Strong Inductionaamir aliBelum ada peringkat
- AML774 Post Assignment 2Dokumen4 halamanAML774 Post Assignment 2Panashe Cleopas MatsaudzaBelum ada peringkat
- Bitcoin ScroogeCoin transactionsDokumen3 halamanBitcoin ScroogeCoin transactionsAnil ShekarBelum ada peringkat
- Journal Pre-Proofs: Chemical Engineering ScienceDokumen40 halamanJournal Pre-Proofs: Chemical Engineering SciencekorichiBelum ada peringkat
- Machine LearningDokumen4 halamanMachine LearningonesnoneBelum ada peringkat
- FEM IntroductionDokumen26 halamanFEM IntroductionAlfia BanoBelum ada peringkat
- Vibration Reduction of Gantry Crane Loads Using FIR FiltersDokumen7 halamanVibration Reduction of Gantry Crane Loads Using FIR FiltersHosseinBelum ada peringkat
- Conversion between number basesDokumen5 halamanConversion between number basesMohibul HasanBelum ada peringkat
- 2008 Carter 12Dokumen38 halaman2008 Carter 12PiousBelum ada peringkat
- Regression Model Specification ErrorsDokumen7 halamanRegression Model Specification ErrorsAbdullah KhatibBelum ada peringkat
- Survey Reveals Awareness of Legislator's Abortion Funding PositionDokumen3 halamanSurvey Reveals Awareness of Legislator's Abortion Funding PositionÁngel Enrique Cabarcas MendozaBelum ada peringkat
- F3a 1Dokumen126 halamanF3a 1Ng Kwan YinBelum ada peringkat
- Design of Equiripple FIR Filters Using Multiple Exchange AlgorithmDokumen34 halamanDesign of Equiripple FIR Filters Using Multiple Exchange AlgorithmPatel IbrahimBelum ada peringkat
- Absolute Value Equations and InequalitiesDokumen13 halamanAbsolute Value Equations and InequalitiesAnonymous chEHU2E8PBelum ada peringkat
- Exam Paper for Neural Networks CoursesDokumen7 halamanExam Paper for Neural Networks CoursesAlshabwani SalehBelum ada peringkat
- GEG 311 - 3 Calculus of Several Variablespdf2Dokumen26 halamanGEG 311 - 3 Calculus of Several Variablespdf2OBO EmmanuelBelum ada peringkat
- Signals & Systems (Solved Problems)Dokumen7 halamanSignals & Systems (Solved Problems)Lohith CoreelBelum ada peringkat
- Materi 4 - Analisis Big DataDokumen30 halamanMateri 4 - Analisis Big DataGerlan NakeciltauBelum ada peringkat
- Springer - Synchronization and Triggering - From Fracture To Earthquake Processes - Laboratory, Field Analysis and Theories - 2010Dokumen381 halamanSpringer - Synchronization and Triggering - From Fracture To Earthquake Processes - Laboratory, Field Analysis and Theories - 2010qkmongaBelum ada peringkat
- Multicriteria Decision Making: Analytical Hierarchy ProcessesDokumen20 halamanMulticriteria Decision Making: Analytical Hierarchy ProcessesmohsinyazdaniBelum ada peringkat
- A Technique of Treating Negative Weights in WENO SchemesDokumen26 halamanA Technique of Treating Negative Weights in WENO Schemesdavidjones1105Belum ada peringkat
- Biceph-Net A Robust and Lightweight Framework For The Diagnosis of Alzheimers Disease Using 2D-MRI Scans and Deep Similarity LearningDokumen9 halamanBiceph-Net A Robust and Lightweight Framework For The Diagnosis of Alzheimers Disease Using 2D-MRI Scans and Deep Similarity LearningWided HechkelBelum ada peringkat
- Regression Analysis AssignmentDokumen8 halamanRegression Analysis Assignmentضیاء گل مروت100% (1)
- Contoh Soal Matematika Diskrit Tentang Relation, Function, and RecurrenceDokumen10 halamanContoh Soal Matematika Diskrit Tentang Relation, Function, and RecurrencerakhaaditBelum ada peringkat
- Full Download Solution Manual For Managerial Economics Business Strategy 10th Edition Michael Baye Jeff Prince PDF Full ChapterDokumen36 halamanFull Download Solution Manual For Managerial Economics Business Strategy 10th Edition Michael Baye Jeff Prince PDF Full Chaptercerasin.cocoon5pd1100% (15)
- 1 Mathematical Modeling of Physical SystemsDokumen18 halaman1 Mathematical Modeling of Physical Systemsmichael KetselaBelum ada peringkat