LECTURE NOTES
Artificial Intelligence
Minggu 9
Natural Language Processing
Artificial Intelligence
� LEARNING OUTCOMES
LO3: Mengaplikasikan berbagai teknik pada agen pada saat bertindak dalam domain
yang tidak pasti
LO4: Mengaplikasikan berbagai algoritma pembelajaran untuk menyelesaikan masalah
OUTLINE MATERI
• Model bahasa
• Klasifikasi Teks
• Retrieval Informasi
• Ekstraksi Informasi
• Struktur Tata Bahasa
• Analisis Sintaksis
• Mesin penerjemah
• Pengenalan Suara
• Simpulan
Artificial Intelligence
� ISI MATERI
1. Pengolahan Bahasa Alami
Agen yang ingin menambahkan informasi perlu memahami bahasa manusia karena
terkadang ambigu dan tidak jelas.
Ada 3 cara untuk menemukan informasi berdasarkan perspektif temu kembali
informasi:
a) Klasifikasi Teks
b) Temu kembali informasi
c) Ekstraksi Informasi
Salah satu faktor yang umum dalam pencarian informasi adalah Model Bahasa. Ada
banyak sekali informasi yang terdapat di halaman Web, hampir semuanya
menggunakan bahasa alami. Seorang agen yang ingin melakukan akuisisi
pengetahuan perlu memahami bahasa yang digunakan oleh manusia yang terkadang
ambigu dan tidak jelas. Hal ini dilihat dari sudut masalah: klasifikasi teks, temu
kembali, dan ekstraksi informasi. Bahasa formal memiliki aturan yang menentukan
makna atau semantiknya. Misalnya, Riles mengatakan bahwa "makna" dari "2 + 2"
adalah 4, dan arti dari "1/0" adalah ada kesalahan.
2. Model bahasa
a) Model N-gram
Model karakter N-gram didefinisikan sebagai rangkaian rantai Markov dengan
orde n-1. Dalam rantai Markov probabilitas karakter hanya bergantung pada
karakter sebelumnya, sehingga dalam model trigram (Markov chain orde 2)
dirumuskan:
Kita dapat menentukan probabilitas urutan karakter P(c1:N) di bawah model
trigram dengan factor pertama dengan aturan rantai kemudian menggunakan
asumsi Markov:
Contoh
Artificial Intelligence
� Perhatikan kalimat “Kemarin aku membeli sepatu baru”
Jika n = 1 → disebut juga unigram, n-gram menjadi
1. Kemarin
2. aku
3. membeli
4. sepatu
5. baru
Jika n = 2 → disebut juga bigram, n-gram menjadi
1. Kemarin aku
2. aku membeli
3. membeli sepatu
4. sepatu baru
Jika n = 3 → disebut juga trigram, n-gram menjadi
1. Kemarin aku membeli
2. membeli sepatu baru
b) Penghalusan model N-gram
• Dalam model N-gram, kata-kata bukan umum, seperti 'ht', memiliki estimasi
0 (nol)
• Generalisasi model bahasa untuk mengidentifikasi teks yang belum pernah
dilihat dari agen sebelumnya
• Pendekatan penghalusan N-gram dengan model Pierre-Simon Laplace,
mengatakan dalam kumpulan informasi, jika variabel acak X selalu salah
dalam pengamatan, maka formula untuk adalah
P (X = benar) = 1/(n+2)
• Pendekatan penghalusan yang lebih baik dengan m enggunakan
model backoff,misalnya: Linear interpolation smoothing. Linear interpolation
smoothing menggabungkan unigram,bigram, dan trigram dengan menggunakan
interpolasi linier.
Artificial Intelligence
�3. Klasifikasi Teks
Klasifikasi teks, dikenal juga sebagai kategorisasi yang artinya teks yang terdiri dari
beberapa jenis, akan dikelompokkan berdasarkan kelas yang telah ditentukan.
Identifikasi bahasa dan klasifikasi genre music atau film adalah contoh klasifikasi
teks, seperti analisis sentimen (mengklasifikasikan review film atau produk sebagai
positif atau negatif) dan deteksi spam (mengklasifikasikan pesan email sebagai spam
atau bukan spam).
Klasifikasi dengan kompresi data
• Cara lain untuk melihat masalah klasifikasi adalah melihat sebagai masalah
kompresi data. Algoritma kompresi lossless mengambil urutan simbol,
mendeteksi pola berulang di dalamnya, dan menulis deskripsi urutan yang lebih
ringkas dari aslinya. Misalnya, teks "0.142857142857142857" akan diubah
menjadi "142857."
• Akibatnya, algoritma kompresi menciptakan sebuah model bahasa. Algoritma
LZW secara khusus memodelkan distribusi probabilitas entropi maksimum.
Untuk melakukan klasifikasi dengan kompresi, pertama-tama kita
menggabungkan semua pesan pelatihan spam dan memampatkannya
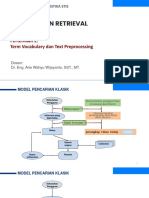
4. Retrieval Informasi
a) Temu kembali informasi bertujuan untuk menemukan dokumen yang sesuai
dengan kebutuhan pengguna. Contoh sistem temu kembali informasi yang
paling terkenal adalah mesin pencari di World Wide Web. Pengguna Web dapat
mengetikkan kueri seperti [AI] ke mesin pencarian dan melihat daftar halaman
yang relevan.
Sistem temu kembali informasi (selanjutnya disebut IR) dapat ditandai dengan:
o Korpus dokumen. Setiap sistem harus memutuskan apa yang ingin
diperlakukan sebagai dokumen: paragraf, halaman, atau teks multipage.
o Pertanyaan diajukan menggunakan query. Kueri menentukan apa yang ingin
diketahui pengguna. Bahasa kueri bisa berupa daftar kata- kata, seperti [buku
AI]; atau menggunakan sebuah frasa kata.
o Kumpulan hasil yang ditentukan. Ini merupakan bagian dari dokumen yang
menurut sistem IRrelevan dengan kueri. Relevan disini mempunyai arti hasil
ini berguna bagi orang yang mengajukan pertanyaan, untuk kebutuhan informasi
tertentu yang diungkapkan dalam kueri.
o Tampilan kumpulan hasil. Tampilan dapat berupa daftar judul dokumen atau
sekompleks peta warna yang berputar dari hasil yang diproyeksikan ke ruang
tiga dimensi, yang diberikan sebagai tampilan dua dimensi.
Informasi Retrieval = menemukan kembali informasi
Temu kembali informasi seperti melakukan kueri (input pengguna) dari semua
dokumen yang ada untuk mendapatkan informasi yang dibutuhkan pengguna.
Artificial Intelligence
� Contohnya temu kembali informasi adalah Google.
b) Karakteristik dari IR
o Kumpulan tulisan (dokumen). Sistem harus menentukan mana yang ingin
dianggap sebagai dokumen (kertas). Contoh: paragraf, halaman, dll.
o Kueri pengguna
Kueri adalah rumus yang digunakan untuk menemukan informasi yang
dibutuhkan oleh pengguna. Dalam bentuk yang paling sederhana, kueri adalah
kata kunci dan dokumen yang mengandung kata kunci yang dicari dalam
dokumen.
Contoh: [buku AI]; ["buku AI"]; [AI dan buku]; [AI DEKAT buku];
[Situs buku AI: [Link]].
o Kumpulan Hasil
Hasil dari kueri. Bagian dari dokumen yang relevan dengan kueri.
o Tampilan set hasil
Dapat berupa hasil yang diurutkan berdasarkab judul dokumen
c) Fungsi Penentuan IR
o Model Boolean telah ditinggalkan digantikan dengan model statistik
berdasarkan jumlah kata.
o Fungsi penilaian BM25, Stephen Robertson dan Karen Sparck Jones di
London City College yang telah digunakan di search engine.
o Fungsi penilaian mengambil dokumen dan query yang mengembalikan nilai
numerik, dokumen yang paling relevan memiliki nilai tertinggi.
o Dalam fungsi BM25, skor sebanding dengan bobot kombinasi skor untuk
setiap kata sesuai dengan kueri.
Faktor-faktor yang mempengaruhi bobot:
• Frekuensi kata yang muncul dalam dokumen yang sesuai dengan kueri (TF).
• Kebalikan dari TF atau IDF.
• Panjang dokumen. Sebuah dokumen berisi jutaan kata bisa menyebutkan
semua kata kueri, tapi mungkin juga itu bukan yang disebut dalam kueri.
Sebuah dokumen singkat yang menguraikan semua kata adalah kandidat yang
lebih baik.
Artificial Intelligence
�d) Evaluasi Sistem IR
• Bagaimana cara memeriksa fungsi IR bekerja dengan baik?
• Nilai performa aplikasi IR menunjukkan keberhasilan IR dalam
menemukan kembali informasi yang dibutuhkan oleh pengguna.
• Parameter yang digunakan dalam mengukur kinerja sistem adalah untuk
mengukur kelengkapan dan akurasi.
• Fungsi: Recall (kelengkapan) dan Precision (Akurasi)
Contoh kasus
Recall (kelengkapan) adalah rasio jumlah dokumen yang relevan yang
diperoleh sistem dengan jumlah semua dokumen yang relevan dalam
pengumpulan dokumen (digambar atau tidak ditarik oleh sistem).
Precision (Akurasi) untuk mengukur rasio dokumen dalam kumpulan hasil
yang benar-benar relevan.
30
𝑃𝑟𝑒𝑐𝑖𝑠𝑖𝑜𝑛 = = 0.75
30 + 10
e) Penyempurnaan IR
Terdapat banyak kemungkinan untuk membuat sistem IR menjadi lebih baik.
Hal itu dapat dilakukan dengan mencari algoritma yang lebih baik untuk
menemukan dokumen yang relevan. Fungsi penilaian BM25 berlaku bahwa
setiap kata harus berdiri sendiri, tetapi pada kenyataannya, banyak kata yang
mungkin terkait. Misalnya: kata "couch" dikaitkan dengan kata 'couches' atau
'sofa'. Banyak IR yang mencoba menerapkan asosiasi ini. Selanjutnya, dalam
menyikapi hubungan antara "couch" dengan 'couches' ada temuan tentang
pendekatan algoritma stemming. (Penghapusan kata, dalam hal ini penghapusan
-es). Tapi kita akan menemukan masalah lain karena akan mengurangi presisi,
pada proses stemming, "stocking" akan menjadi 'stock', itu bukan masalah, tapi
kata "foot covering" akan mengurangi presisi. Ada temuan lain, yaitu 'stemming
based on dictionary' untuk memecahkan masalah di atas. Kata -ing tidak akan
jika kata tersebut ditemukan dalam kamus. Langkah selanjutnya adalah
Artificial Intelligence
� mengidentifikasi sinonim. "Couch" dan"sofa"
Fungsi BM25 :
• di = panjang dokumen (dalam kata)
• N = total dokumen
• L = panjang rata-rata dokumen dalam korpus (koleksi dokumen).
• Fungsi TF (Term Frekuensi)
• Fungsi IDF (kebalikan dari TF) invers.
• Ada 2 parameter, yaitu k dan b. nilai k = 0,2 dan b = 0,75.
f) Algoritma PageRank
o Algoritma ini adalah salah satu ide original dalam pencarian Google
membedakan dengan mesin pencari web lainnya.
o Idenya adala menghubungkan kata-kata menjadi hyperlink menuju halaman lain
yang dimaksud.
o Jika query [IBM] bagaimana kita memastikan bahwa home page IBM
([Link]) adalah yang pertama dalam urutan hasil query, meskipun
sebenarnya halaman lain memiliki frekuensi kata IBM yang lebih banyak.
Konsepnya adalah [Link] memiliki banyak link menuju [Link]), maka
dipastikan akan berada di peringkat pertama dalam hasilnya.
o Tetapi jika kita hanya menghitung link saja, akan memungkinkan bagi
spammer Web untuk membuat halaman web dan membuat banyak tautan
yang mengarah ke halaman halaman mana yang akan meningkatkan skor
halaman web. Oleh karena itu, algoritma PageRank dirancang d e n g a n
bobot link dari situs y a n g r e l e v a n
g) Algoritma HITS (Hyperlink-Induced Topic Search)
Ini hampir sama dengan algoritma PageRank, namun HITS tidak menghitung
jumlah link di halaman, tapi melihat link yang ditemukan, jika sesuai dengan
tujuan link dengan kata-kata yang lebih tepat antara link asal ke link tujuan,
semakin tinggi nilai otoritas halaman.
h) Question Answering
• Bila tipe query adalah pertanyaan, maka hasilnya bukan daftar rangking
dokumen, namun bentuk respon singkat, bisa jadi berupa kalimat atau frase.
• Sistem ASKMSR (Banko, 2002) adalah sistem pertanyaan dan jawaban
berbasis web. Berdasarkan premis bahwa pertanyaan bisa dijawab di banyak
halaman web, maka masalah yang dipertanyakan dan dijawab dianggap
sebagai isu presisi (akurasi), bukan recall (kelengkapan).
Artificial Intelligence
� • ASKMSR tidak mengenali kata ganti, kata kerja, dll. Hanya dikenali 15 jenis
pertanyaan dan cara penulisan ulang di search engine.
• Contoh pertanyaan [who killed Abraham Lincoln] dapat ditulis ulang menjadi
[killed Abraham Lincoln] dan menjadi [Abraham Lincoln was killed by*].
• Hasil yang diperoleh bukan halaman penuh namun hanya ringkasan singkat
teks yang mungkin mendekati kondisi kueri.
• Hasilnya adalah 1 -, 2 -, dan 3 n-gram dan dihitung untuk rangkaian frekuensi
hasil dan bobot: n-gram dikembalikan dari pertanyaan yang sangat spesifik
yang ditulis ulang (seperti mencocokkan kueri dengan tepat dengan frasa
["Abraham Lincoln was killed by*"]) akan mendapatkan bobot lebih banyak
daripada kueri umum seperti [Abraham ATAU Lincoln ATAU killed]. Hasil
yang diharapkan adalah "John Wilkes Booth" akan menjadi salah satu hasil
dari n-gram dengan peringkat tinggi, tapi begitu juga "Abraham Lincoln" dan
"pembunuhan" dan "Teater Ford".
• Setelah n-gram diberi nilai, maka akan difilter berdasarkan pertanyaan, jika
pertanyaannya adalah "siapa" yang kemudian akan disaring pada nama
seseorang. Bila pertanyaannya adalah "kapan" itu akan disaring pada tanggal
atau waktu. Ada juga filter yang bukan bagian dari jawaban atas
pertanyaannya.
5. Ekstraksi Informasi
Ekstraksi informasi adalah proses memperoleh pengetahuan dengan membaca teks
dan mencari kejadian dari kelas objek tertentu dan untuk hubungan antar objek.
Jenis paling sederhana dari sistem ekstraksi informasi adalah sistem ekstraksi
berbasis atribut TEMPLATE REGULER EXPRESSION yang mengasumsikan bahwa
keseluruhan teks mengacu pada satu objek dan tugasnya adalah untuk mengekstrak
atribut objek itu.
4 perkiraan untuk Ekstraksi Informasi:
o Deterministik terhadap stokastik
o Domain-spesifik untuk umum
o Hand-crafted untuk dipelajari
o Skala kecil sampai berskala besar
FASTUS adalah sistem ekstraksi berbasis [Link] menjadi 5 tahap:
o Tokenisasi
yang membagi aliran karakter menjadi token (kata, angka, dan tanda
baca). Untuk bahasa Inggris, tokenization bisa sangat sederhana; hanya
sepintas karakter di ruang putih atau tanda baca melakukan pekerjaan
yang cukup baik. Beberapa tokenizers juga menangani bahasa markup
seperti HTML, SGML, dan XML.
Artificial Intelligence
� o Penanganan kata kompleks
termasuk kolokasi seperti “set up” dan “joint venture,” serta nama-nama
yang tepat seperti “Bridgestone Sport Co” ini diakui oleh kombinasi
entri leksikal dan aturan tata bahasa yang terbatas-negara. Sebagai
contoh, nama perusahaan mungkin akan diakui oleh aturan.
o Penanganan kelompok dasar
artinya kelompok kata benda dan kelompok kata kerja. Idenya adalah
untuk memasukkannya ke dalam unit yang akan dikelola oleh tahap
selanjutnya. Kita akan melihat bagaimana menulis deskripsi kata benda
dan frase kata-kata yang kompleks di Bab 23, tapi di sini kita memiliki
peraturan sederhana yang hanya mendekati kompleksitas bahasa
Inggris, namun memiliki keuntungan untuk dapat mewakili oleh
automata negara yang terbatas. Contoh kalimat akan muncul dari tahap
ini sebagai urutan kelompok tag berikut:
Disini NG berarti kelompok kata benda, VG adalah kelompok kata
kerja, PR adalah preposisi, dan CJ adalah konjungsi.
o Penanganan frase kompleks
Tujuannya adalah untuk memiliki peraturan yang bersifat terbatas dan
dengan demikian dapat diproses dengan cepat, dan itu menghasilkan
frase keluaran yang tidak ambigu (atau hampir tidak ambigu). Salah
satu jenis aturan kombinasi berkaitan dengan peristiwa khusus domain.
Misalnya aturannya
o Penggabungan struktur
dibangun di langkah sebelumnya. Jika kalimat berikutnya mengatakan
"Usaha patungan akan mulai berproduksi pada bulan Januari," maka
langkah ini akan memperhatikan bahwa ada dua referensi untuk usaha
patungan, dan bahwa hal itu harus digabungkan menjadi satu.
• Model probabilistik untuk ekstraksi informasi
Bila ekstraksi informasi harus diupayakan dari masukan yang berisik atau
Artificial Intelligence
�bervariasi, pendekatan negara bagian sederhana tidak berjalan dengan baik.
Terlalu sulit untuk mendapatkan semua peraturan dan prioritas mereka
dengan benar; lebih baik menggunakan model probabilistik daripada model
berbasis aturan. Model probabilistik yang paling sederhana untuk urutan
dengan keadaan tersembunyi adalah model Markov tersembunyi, atau
HMM.
Untuk menerapkan HMM pada ekstraksi informasi, kita dapat membangun
satu HMM besar untuk semua atribut atau membangun HMM terpisah
untuk setiap atribut. Kita akan melakukan yang kedua. Pengamatan adalah
kata-kata dari teks, dan keadaan tersembunyi adalah apakah kita berada di
bagian target, awalan, atau postfix dari template atribut, atau di latar
belakang (bukan bagian dari template).
Contoh :
Diagram
Ekstraksi Ontologi dari corpora besar
• Sejauh ini kami telah memikirkan ekstraksi informasi saat menemukan
rangkaian hubungan tertentu (mis., Pembicara, waktu, lokasi) dalam
teks tertentu (mis., Pengumuman ceramah). Penerapan teknologi
ekstraksi yang berbeda adalah membangun basis pengetahuan yang
besar atau ontologi fakta dari sebuah korpus. Ini berbeda dalam tiga
cara:
• Pertama, open-ended-kita ingin mendapatkan fakta tentang semua jenis
Artificial Intelligence
� domain, bukan hanya satu domain tertentu.
• Kedua, dengan korpus besar, tugas ini didominasi oleh ketepatan, bukan
dengan menjawab pertanyaan di Web (Bagian 22.3.6).
• Ketiga, hasilnya bisa jadi agregat statistik dikumpulkan dari berbagai
sumber, bukan diekstrak dari satu teks tertentu.
6. Struktur Tata Bahasa Frase
Model bahasa n-gram didasarkan pada urutan kata. Masalah dengan model ini adalah
data sparsity. Tetapi hal tersebut dapat diatasi melalui generalisasi. Dalam tata bahasa
Inggris, generalisasi dapat terbentuk dari kata sifat cenderung datang sebelum kata
benda. Kategori leksikal seperti kata benda atau kata sifat juga berguna untuk
generalisasi. Terdapat banyak model bahasa berdasarkan ide struktur frase, namun
yang akan digunakan disini adalah tata bahasa bebas konteks probabilistik, atau
PCFG.1
Tata bahasa adalah kumpulan aturan yang mendefinisikan bahasa sebagai serangkaian
kata yang diizinkan. "Bebas konteks" adalah struktur yang memenuhi tata bahasa
tertentu dan "probabilistik" berarti bahwa tata bahasa memberikan probabilitas untuk
setiap katanya.
Berikut adalah aturan PCFG:
VP (frasa kata kerja) dan NP (frasa kata benda) adalah simbol non-terminal. Tata
bahasa juga mengacu pada kata-kata aktual, yang disebut simbol terminal.
Dalam tata bahasa bebas konteks terdapat leksikon yaitu daftar kata yang
diperbolehkan. Kata-kata dikelompokkan ke dalam kategori seperti kata benda, kata
ganti, dan nama untuk menunjukkan sesuatu; kata kerja untuk menunjukkan
peristiwa; kata sifat untuk memodifikasi kata benda; kata keterangan untuk
memodifikasi kata kerja; artikel (seperti the), preposisi (di), dan konjungsi (dan)
Artificial Intelligence
� Selanjutnya adalah menggabungkan kata-kata menjadi frase. Gambar 1 menunjukkan
tata bahasa untuk leksikon, dengan aturan untuk masing-masing dari enam kategori
sintaksis dan contoh untuk setiap aturan penulisan ulang. Gambar 2 menunjukkan
pohon parse untuk kalimat “Setiap wumpus berbau.” Pohon parse memberikan bukti
konstruktif bahwa rangkaian kata dapat membentuk suatu kalimat menurut aturan
leksikon.
Gambar 1
Gambar 2
7. Analisis Sintaksis (Parsing)
Parsing adalah proses menganalisis untaian kata untuk melihat struktur frasanya,
menurut aturan tata bahasa. Proses analisis dapat dimulai dengan simbol S dan
mencari dari atas ke bawah untuk pohon yang memiliki kata-kata sebagai cabang,
atau dapat dimulai dengan kata-kata dan mencari dari bawah ke atas untuk pohon S.
Artificial Intelligence
�8. Mesin penerjemah
Mesin penerjemah adalah penerjemah otomatis suatu teks dari satu bahasa alami
(sumber) ke bahasa lain (target). Penerjemahan sulit dilakukan karena memerlukan
pemahaman teks yang mendalam. Seorang penerjemah (manusia atau mesin) sering
kali perlu memahami situasi aktual yang dijelaskan dalam sumbernya, bukan hanya
kata per kata. Semua sistem terjemahan harus memodelkan bahasa sumber dan bahasa
target. Sistem tersebut menyimpan database aturan terjemahan dan kapan aturan tepat
digunaka. Jika sudah sesuai sistem akan menerjemahkan secara langsung. Terjemahan
dapat terjadi pada level leksikal, sintaksis, atau semantic. Pada gambar dibawah
adalah contoh terjemahan dari bahasa Inggris kedalam bahasa Perancis.
Untuk menerjemahkan kalimat bahasa Inggris (e) ke bahasa Perancis (f), formula
yang dapat digunakan
P(f) adalah model bahasa target untuk bahasa Perancis
P(e|f) adalah model terjemahan
P(f|e) adalah model terjemahan dari bahasa Inggris ke bahasa Prancis
Dalam mencari terjemahaan, sebuah kalimat bahasa Inggris (e), menjadi terjemahan
bahasa Perancis (f) ada tiga langkah:
1. Pecah kalimat bahasa Inggris menjadi frasa e1,...,en.
2. Untuk setiap frasa ei, pilih frasa Perancis yang sesuai fi. Dapat digunakan
notasi P(fi|ei) untuk probabilitas phrasal bahwa fi adalah terjemahan dari ei.
Artificial Intelligence
� 3. Pilih permutasi dari frasa f1,...,fn. Untuk setiap fi, kami memilih distorsi di ,
yang merupakan jumlah kata yang dipindahkan frasa fi sehubungan dengan
fi− 1; positif untuk bergerak ke kanan, negatif untuk bergerak ke kiri, dan nol
jika fi diikuti dengan fi−1
Contoh
“There is a smelly wumpus sleeping in 2 2”
o Pecah kalimat menjadi 5 frasa e1,...,e5. Setiap frasa diterjemahkan yang
berkorespodensi dengan frasa fi,
o Lakukan permutasi sesuai urutan f1,f3,f4,f2,f5.
o di = START(fi)−END(fi−1) − 1 , dimana START(fi) is urutan dari kata
pertama dari frasa fi dalam kalimat Perancis, dan END(fi−1) is urutan kata
terakhir dalam frasa fi−1.
o Buat asumsi bahwa setiap terjemahan frasa dan setiap distorsi tidak
bergantung pada yang lain, ekspresi dapat difaktorkan sebagai
9. Pengenalan Ucapan
Pengenalan ucapan adalah sistem untuk mengidentifikasi urutan kata yang
diucapkan oleh pembicara, yang diberikan melalui sinyal akustik. Bidang ini telah
menjadi salah satu aplikasi utama AI—karena banyak orang berinteraksi dengan
sistem pengenalan suara dalam kehidupan sehari-hari seperti untuk menavigasi
sistem pesan suara, menelusuri Web dari ponsel, dan aplikasi lainnya. Pengenalan
ucapan sulit karena suara yang dibuat oleh pembicara ambigu dan juga tidak jelas
pengucapannya. Pengenalan suara dapat dihitung dengan bantuan aturan Bayes
menjadi:
P(sound1:t|word1:t) adalah model akustik.
Notasi ini untuk menggambarkan bunyi kata, seperti kata "ceiling" dimulai dengan
Artificial Intelligence
�huruf "c" yang lembut dan bunyinya sama dengan "sealing".
P(word1:t) dikenal sebagai model bahasa.
Notasi ini digunakan untuk menentukan probabilitas dari kata yang diucapkan
sebelumnya, misalnya, bahwa "ceiling fan" memiliki kemungkinan sekitar 500 kali
diucapkan daripada "sealing fan."
Artificial Intelligence
� SIMPULAN
1. Model bahasa probabilistik berdasarkan n-gram memulihkan sejumlah informasi
tentang sebagai bahasa.
2. Model bahasa probabilistik dapat melakukan dengan baik pada tugas yang
beragam seperti identifikasi bahasa, koreksi ejaan, klasifikasi genre, dan
pengenalan entitas bernama.
3. Sistem temu kembali informasi menggunakan model bahasa yang sangat
sederhana berdasarkan kumpulan kata, dan presisi yang besar. Di pengembangan
Web, algoritma analisis tautan dapat meningkatkan unjuk kerja
4. Question answering dapat ditangani dengan pendekatan berbasis temu kembali
informasi, untuk pertanyaan yang memiliki banyak jawaban dalam korpus. Ketika
lebih banyak jawaban tersedia di korpus, kita dapat menggunakan teknik presisi
daripada mengingat.
5. Sistem Ekstraksi Informasi menggunakan model yang lebih kompleks yang
mencakup pengertian sintaksis dan semantik yang terbatas dalam bentuk template.
Sistem tersebut dibangun dari FSA,
6. Dalam membangun sistem bahasa statistik, yang terbaik adalah merancang model
yang dapat memanfaatkan data yang tersedia dengan baik.
7. Teori bahasa formal dan tata bahasa struktur frase (dan khususnya, tata bahasa
bebas konteks) adalah alat yang berguna untuk menangani beberapa aspek bahasa
alami. Formalisme tata bahasa bebas konteks probabilistik (PCFG) banyak
digunakan.
8. Ambiguitas adalah masalah yang sangat penting dalam pemahaman bahasa alami;
kebanyakan kalimat memiliki banyak kemungkinan interpretasi, tetapi biasanya
hanya satu yang sesuai. Disambiguasi bergantung pada pengetahuan tentang
dunia, tentang situasi saat ini, dan tentang penggunaan bahasa.
9. Mesin penerjemah telah diimplementasikan menggunakan berbagai teknik, mulai
dari analisis sintaksis dan semantik penuh hingga teknik statistik berdasarkan
frekuensi frasa. Saat ini model statistik paling populer dan paling sukses.
10. Sistem pengenalan ucapan juga terutama didasarkan pada prinsip-prinsip statistik.
Sistem ucapan populer dan berguna, meskipun tidak sempurna
Artificial Intelligence
� DAFTAR PUSTAKA
1. Stuart Russell, Peter Norvig,. 2010. Artificial intelligence : a modern
approach. PE. New Jersey. ISBN:9780132071482, Chapter 22-23
2. Elaine Rich, Kevin Knight, Shivashankar B. Nair. 2010. Artificial
Intelligence. MHE. New York. ISBN:0070678162, Chapter 15
3. Applications in Natural Language Processing:
4. [Link]
5. Artificial Intelligence: Natural Language Processing:
6. [Link]
Artificial Intelligence