Anda mungkin juga menyukai
- SocialNetworkAnalysisv1 3Dokumen11 halamanSocialNetworkAnalysisv1 3Tsaqif Alfatan NugrahaBelum ada peringkat
- Text ClassificatiomDokumen14 halamanText ClassificatiomRizqyFaishalTanjungBelum ada peringkat
- Bab 3Dokumen25 halamanBab 3Rinaldo Anugrah WahyudaBelum ada peringkat
- Laporan Pointer Dan ArrayDokumen27 halamanLaporan Pointer Dan Arraynadiadia210402Belum ada peringkat
- 05.3 Bab 3Dokumen7 halaman05.3 Bab 3Xixi NnnBelum ada peringkat
- Ekohadigunawan 1220 2470 1 sm1 13 OkDokumen14 halamanEkohadigunawan 1220 2470 1 sm1 13 OkMoh SalehBelum ada peringkat
- Confusion Matrik 2Dokumen8 halamanConfusion Matrik 2Wiwik MellianaBelum ada peringkat
- Tugas Mandiri Mata Kuliah: Sistem Informasi Manajemen (Spbid 14327) Dosen PengasuhDokumen4 halamanTugas Mandiri Mata Kuliah: Sistem Informasi Manajemen (Spbid 14327) Dosen PengasuhYayang AljufryBelum ada peringkat
- Analisis DataDokumen14 halamanAnalisis DataRizki MewengkangBelum ada peringkat
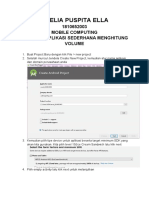
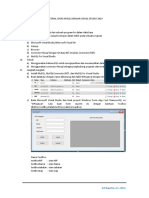
- Membuat Aplikasi Sederhana Menghitung Volume Android StudioDokumen11 halamanMembuat Aplikasi Sederhana Menghitung Volume Android StudioAmelia Puspita EllaBelum ada peringkat
- Rizky Ulfiyatul Ihsani - CDokumen17 halamanRizky Ulfiyatul Ihsani - Cricky rizkyBelum ada peringkat
- Pendataan AlumniDokumen12 halamanPendataan AlumniRahmat AlqoriBelum ada peringkat
- Angga - Nurul - Huda TI - BDokumen17 halamanAngga - Nurul - Huda TI - Bricky rizkyBelum ada peringkat
- Prototype Final ProjectDokumen26 halamanPrototype Final ProjectWidyaningdyah HidayatiBelum ada peringkat
- Rian Delianur - 2KA12 - 10120993 - Minggu Ke 8 - Ujian - Tipe CDokumen9 halamanRian Delianur - 2KA12 - 10120993 - Minggu Ke 8 - Ujian - Tipe CRian Delianur 1KA05Belum ada peringkat
- P5 RevDokumen10 halamanP5 RevArya YeeBelum ada peringkat
- Dokumen Memakai RDokumen18 halamanDokumen Memakai RbenikyoshiroBelum ada peringkat
- Science Data-12Dokumen15 halamanScience Data-12Malik Bayu AjiBelum ada peringkat
- A710200061 - Nabila Kusumawardani - Bab 1Dokumen5 halamanA710200061 - Nabila Kusumawardani - Bab 1NABILA KUSUMAWARDANIBelum ada peringkat
- Laporan PointerDokumen10 halamanLaporan PointerNadia FebiantiBelum ada peringkat
- Bab 1 Elemen - Elemen Dasar C++Dokumen14 halamanBab 1 Elemen - Elemen Dasar C++Suci May IswandhariBelum ada peringkat
- Donny Database A Pi ProjectDokumen25 halamanDonny Database A Pi ProjectjonoBelum ada peringkat
- Laprak SDA 3Dokumen26 halamanLaprak SDA 3Deva MarlinaBelum ada peringkat
- Teks (Minggu Ke-4)Dokumen8 halamanTeks (Minggu Ke-4)LaylaBelum ada peringkat
- Era Pratiwi 19220378 SI6RDokumen15 halamanEra Pratiwi 19220378 SI6RWedding Organizer DaraBelum ada peringkat
- Shilvia Febrianti If 19GX UASDokumen8 halamanShilvia Febrianti If 19GX UASAdam PrasetiiaBelum ada peringkat
- Tugas Rangkuman Mobile ProgrammingDokumen17 halamanTugas Rangkuman Mobile ProgrammingNabila Siti RomdziyahBelum ada peringkat
- Materi SQLiteDokumen16 halamanMateri SQLiteAdipta OktayasaBelum ada peringkat
- 493-Article Text-1892-1-10-20230326Dokumen8 halaman493-Article Text-1892-1-10-20230326Wahyu WigunaBelum ada peringkat
- Apkom M.5Dokumen19 halamanApkom M.5Aditya PutuBelum ada peringkat
- Modul 5 Python Collections (Arrays) Dan FunctionsDokumen7 halamanModul 5 Python Collections (Arrays) Dan FunctionsJuli Herman LaseBelum ada peringkat
- Modul 4Dokumen18 halamanModul 4Muhamad LuqmanBelum ada peringkat
- Shafira Zelinda 'Ainiyatur Rohmah (Lapres 09)Dokumen16 halamanShafira Zelinda 'Ainiyatur Rohmah (Lapres 09)shafirazelindaofficialBelum ada peringkat
- Insert MySQLDokumen5 halamanInsert MySQLNia PramithaBelum ada peringkat
- Project Simple ETL With PandasDokumen13 halamanProject Simple ETL With PandasEden HizirdBelum ada peringkat
- Sampel Implementasi Computer Vision Atau Text Mining Menggunakan R Atau PythonDokumen12 halamanSampel Implementasi Computer Vision Atau Text Mining Menggunakan R Atau PythonMukti Ali SadikinBelum ada peringkat
- Data SienceDokumen8 halamanData SienceAgung PrayogoBelum ada peringkat
- Bab 2Dokumen12 halamanBab 2Rinaldo Anugrah WahyudaBelum ada peringkat
- BAB 2 - Introduction To Statictics With RDokumen16 halamanBAB 2 - Introduction To Statictics With Rritapermatasari17Belum ada peringkat
- Modul Praktik Prokon 2Dokumen21 halamanModul Praktik Prokon 2FebriBelum ada peringkat
- LAPORAN Data MiningDokumen20 halamanLAPORAN Data Mininglisma seftiawatiBelum ada peringkat
- Laporan Praktikum Lingked List Kelompok FayzaDokumen13 halamanLaporan Praktikum Lingked List Kelompok Fayzanadiadia210402Belum ada peringkat
- Big Data: For BeginnerDokumen28 halamanBig Data: For BeginnerDain AbizarBelum ada peringkat
- Review SIP Murah - 15417050 - Timothy BrandonDokumen13 halamanReview SIP Murah - 15417050 - Timothy BrandonTimothy BrandonBelum ada peringkat
- TBD Iii - 1805551048Dokumen5 halamanTBD Iii - 1805551048Adi SuandikaBelum ada peringkat
- Modul Pelatihan R PDFDokumen109 halamanModul Pelatihan R PDFOka Lakoro0% (1)
- Bab 4 Analisa Hasil Dan PembahasanDokumen19 halamanBab 4 Analisa Hasil Dan PembahasanDaniel ErgawantoBelum ada peringkat
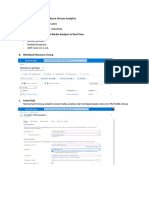
- Social Media Analysis With Azure Stream Analytics - 23522014 - Muhammad Fahmy NadhifDokumen9 halamanSocial Media Analysis With Azure Stream Analytics - 23522014 - Muhammad Fahmy Nadhifnadhif fahmyBelum ada peringkat
- Pemanfaatan Jupyter NotebookDokumen20 halamanPemanfaatan Jupyter NotebookAmirZada Shafir DevitoBelum ada peringkat
- TP2 Dian Rahmad DermawanDokumen6 halamanTP2 Dian Rahmad DermawanDian RahmadBelum ada peringkat
- BAB III Analisis SentimenDokumen6 halamanBAB III Analisis Sentimentanti yulianitaBelum ada peringkat
- Paper KelompokDokumen13 halamanPaper KelompokFicky Dwi SantosoBelum ada peringkat
- G1F022031 M Hidayat Pahlevi Laporan 6 PBASDADokumen10 halamanG1F022031 M Hidayat Pahlevi Laporan 6 PBASDAgremorydxd18Belum ada peringkat
- Prak2-3 Isnani - 1957301025Dokumen8 halamanPrak2-3 Isnani - 1957301025isnaniBelum ada peringkat
- LHP Pbo 5Dokumen30 halamanLHP Pbo 5Zara Ainun SafiraBelum ada peringkat
- Laporan Praktikum PointerDokumen13 halamanLaporan Praktikum PointerNadia FebiantiBelum ada peringkat
- C - BasicDokumen5 halamanC - BasicTriot FilmsBelum ada peringkat
- Praktikum Basis Data Sesi 5Dokumen6 halamanPraktikum Basis Data Sesi 5MOHAMMAD IHSAN ALFALAKBelum ada peringkat
- Membuat Aplikasi Bisnis Menggunakan Visual Studio Lightswitch 2013Dari EverandMembuat Aplikasi Bisnis Menggunakan Visual Studio Lightswitch 2013Penilaian: 3.5 dari 5 bintang3.5/5 (7)
- Mari Belajar Pemrograman Berorientasi Objek menggunakan Visual C# 6.0Dari EverandMari Belajar Pemrograman Berorientasi Objek menggunakan Visual C# 6.0Penilaian: 4 dari 5 bintang4/5 (16)