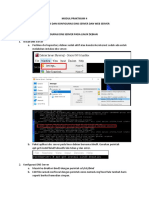
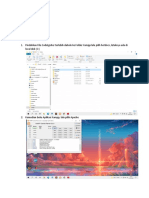
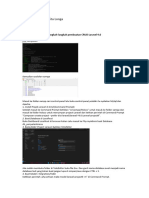
Anda mungkin juga menyukai
- Langkah-Langkah Instalasi HadoopDokumen8 halamanLangkah-Langkah Instalasi HadoopTendi Nugeraha WijayaBelum ada peringkat
- Prak HadoopDokumen24 halamanPrak HadoopHasri AinunBelum ada peringkat
- TugasKelompok HDFS MapReduce Satria&HabibieDokumen9 halamanTugasKelompok HDFS MapReduce Satria&HabibieArnita FentrinBelum ada peringkat
- 4 FileleeDokumen9 halaman4 FileleeArnita FentrinBelum ada peringkat
- Adrian Maulana Rizqy - IF2 - Laporan ITBDDokumen12 halamanAdrian Maulana Rizqy - IF2 - Laporan ITBDAdrian MaulanaBelum ada peringkat
- Modul 1 Implementasi MapReduce Terminal Streaming - Muhamad Aldo Fernanda - 064002000037Dokumen26 halamanModul 1 Implementasi MapReduce Terminal Streaming - Muhamad Aldo Fernanda - 064002000037Nanami KareninaBelum ada peringkat
- Riki Vansuardi HadoopDokumen5 halamanRiki Vansuardi HadoopRiki VansuardiBelum ada peringkat
- HADOOPDokumen23 halamanHADOOPHasri AinunBelum ada peringkat
- Big Data Essentials With Hadoop: Mochamad KhoironDokumen28 halamanBig Data Essentials With Hadoop: Mochamad Khoironsatish.sathya.a2012Belum ada peringkat
- Tugas MODUL PRAKTIKUMDokumen36 halamanTugas MODUL PRAKTIKUMRiki AbdulBelum ada peringkat
- Firstamora Javanda P - 2102182 - P2Dokumen13 halamanFirstamora Javanda P - 2102182 - P2firsta moraBelum ada peringkat
- Modul 2 Cloudera HadoopMR Edit - KelompokDokumen15 halamanModul 2 Cloudera HadoopMR Edit - KelompokSyahrul RamadhanBelum ada peringkat
- HadoopDokumen3 halamanHadoopJamiatBelum ada peringkat
- Infrastruktur Big DataDokumen14 halamanInfrastruktur Big DataAde Candrawan ZonaBelum ada peringkat
- Install Hadoop - Kelompok 3Dokumen9 halamanInstall Hadoop - Kelompok 3Rahma Ataya TBelum ada peringkat
- PDT Modul4b CacheDokumen52 halamanPDT Modul4b CacheAbdul rikiBelum ada peringkat
- Modul PraktikumDokumen8 halamanModul PraktikumRika puspitaBelum ada peringkat
- Membuat File Migrations Dan Database Seed (Laravel Framework)Dokumen3 halamanMembuat File Migrations Dan Database Seed (Laravel Framework)HendarBelum ada peringkat
- Modul 5, 6, 7, 8 FrameworkDokumen39 halamanModul 5, 6, 7, 8 FrameworkAA DEANBelum ada peringkat
- Modul 2 Cloudera HadoopMR Edit - Muhamad Aldo Fernanda - 064002000037Dokumen17 halamanModul 2 Cloudera HadoopMR Edit - Muhamad Aldo Fernanda - 064002000037Nanami KareninaBelum ada peringkat
- Slide INS106 INS106 Slide 14Dokumen29 halamanSlide INS106 INS106 Slide 14Aji NamasayaBelum ada peringkat
- Web Server Debian 10Dokumen4 halamanWeb Server Debian 10aurishii04Belum ada peringkat
- Modul Instalasi Dan Konfigurasi Platform CMS Wordpress Di DebianDokumen6 halamanModul Instalasi Dan Konfigurasi Platform CMS Wordpress Di DebianFahrezy Fahrul RBelum ada peringkat
- Resume Praktek Manajemen Jaringan KomputerDokumen7 halamanResume Praktek Manajemen Jaringan KomputerMuhammad Fhadil Rizky PratamaBelum ada peringkat
- Install Dan Konfigurasi Web Server Dan CMS WordPress Di Debian 8Dokumen4 halamanInstall Dan Konfigurasi Web Server Dan CMS WordPress Di Debian 8Sii Saprandy LasimpalaBelum ada peringkat
- Kuliah KeamananDokumen3 halamanKuliah KeamananD SDBelum ada peringkat
- Laporan Hasil Ujian Praktek Asj JerryDokumen16 halamanLaporan Hasil Ujian Praktek Asj JerryJerry J1Belum ada peringkat
- Formatif Big Data Technology - Sukmayani NasutionDokumen38 halamanFormatif Big Data Technology - Sukmayani NasutionMuhamadAyubAlAnshariBelum ada peringkat
- Jobsheet ASJ DNS WebDokumen13 halamanJobsheet ASJ DNS WebAyunisa Esti DarmayantiBelum ada peringkat
- Winda Saputri - 16121027 - 2LA - Laporan Praktikum Bab 10Dokumen9 halamanWinda Saputri - 16121027 - 2LA - Laporan Praktikum Bab 10WindaBelum ada peringkat
- Laporan Framework CakephpDokumen11 halamanLaporan Framework CakephpMuhammad RamdeniBelum ada peringkat
- MEMBUAT APLIKASI KASIR BERBASIS WEB (CI3 & SBAdmin2)Dokumen33 halamanMEMBUAT APLIKASI KASIR BERBASIS WEB (CI3 & SBAdmin2)23Muhamad Khoirul Bintang SaputroRPL 1Belum ada peringkat
- Clustering ServerDokumen17 halamanClustering Serverchandrika.oktavian9Belum ada peringkat
- Cheat Sheet Ukk TKJDokumen5 halamanCheat Sheet Ukk TKJnursitiabc02Belum ada peringkat
- HadoopVM (Single)Dokumen17 halamanHadoopVM (Single)Luth FanBelum ada peringkat
- Modul 2 Cloudera HadoopMR EditDokumen15 halamanModul 2 Cloudera HadoopMR EditSyahrul RamadhanBelum ada peringkat
- Laporan Konfigurasi Debian 6 ServerDokumen60 halamanLaporan Konfigurasi Debian 6 Serveragus supriantoBelum ada peringkat
- TempleDokumen13 halamanTempleTiti NastitiBelum ada peringkat
- Bab III Cara Instalasi - OdtDokumen98 halamanBab III Cara Instalasi - OdtOrlando Rezki RBelum ada peringkat
- Jobsheet Cms & ProxyDokumen20 halamanJobsheet Cms & ProxySamsudin SaminuBelum ada peringkat
- Setting DNS, WEB, FTP, SAMBA Server Pada Ubuntu ServerDokumen12 halamanSetting DNS, WEB, FTP, SAMBA Server Pada Ubuntu ServerNanang Kurnia WahabBelum ada peringkat
- Laravel KiranaDokumen3 halamanLaravel Kiranafabian6252Belum ada peringkat
- Konfigurasi DEBIANDokumen5 halamanKonfigurasi DEBIANRamzil Gempita HidayatBelum ada peringkat
- Materi Drilling SMK RPL Paket1Dokumen86 halamanMateri Drilling SMK RPL Paket1dede boyBelum ada peringkat
- Laporan Pemrosesan Paralel 2 - Nabilla Suci Febriani - 09011182227018 - SK5CDokumen15 halamanLaporan Pemrosesan Paralel 2 - Nabilla Suci Febriani - 09011182227018 - SK5CNabilla SuciBelum ada peringkat
- Laporan Pemrosesan Paralel 2 - Nabilla Suci Febriani - 09011182227018 - SK5CDokumen15 halamanLaporan Pemrosesan Paralel 2 - Nabilla Suci Febriani - 09011182227018 - SK5CNabilla SuciBelum ada peringkat
- Modul 7Dokumen8 halamanModul 7gabanBelum ada peringkat
- WordpressDokumen14 halamanWordpressAnggud PerlBelum ada peringkat
- Okta Nadilla Putri XII TKJ 2 Konfigurasi Wordpress-2Dokumen10 halamanOkta Nadilla Putri XII TKJ 2 Konfigurasi Wordpress-2intandiah937Belum ada peringkat
- Web Server Apache ConfigurationDokumen12 halamanWeb Server Apache ConfigurationAldo JuliusBelum ada peringkat
- Modul 6 Pengenalan Dan Konfigurasi Codeigniter: A. Tujuan PraktikumDokumen20 halamanModul 6 Pengenalan Dan Konfigurasi Codeigniter: A. Tujuan PraktikumIndra RajsyaBelum ada peringkat
- Cara Install ScriptDokumen1 halamanCara Install ScriptjacklindhaBelum ada peringkat
- Aplikasi Rental MobilDokumen52 halamanAplikasi Rental MobilRidwan K GumilangBelum ada peringkat
- KD 11 Mengevaluasi Dan Mengkonfigurasi Share Hosting ServerDokumen18 halamanKD 11 Mengevaluasi Dan Mengkonfigurasi Share Hosting ServerA'yay Thea0% (1)
- Langkah-Langkah Menginstall CMS DrupalDokumen3 halamanLangkah-Langkah Menginstall CMS DrupalMaharani RindyBelum ada peringkat
- CURD LaravelDokumen12 halamanCURD LaravelZayyan BarcelonaBelum ada peringkat
- Tugas 6Dokumen7 halamanTugas 6AZAM SAPUTRABelum ada peringkat
- Tutorial Installasi Moodle Menggunakan Xampp Di Debian 9 PDFDokumen40 halamanTutorial Installasi Moodle Menggunakan Xampp Di Debian 9 PDFV atleachnaBelum ada peringkat
- Jobsheet - Linux Web Server (LAMP)Dokumen18 halamanJobsheet - Linux Web Server (LAMP)abd ghafurBelum ada peringkat