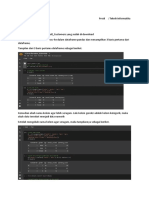
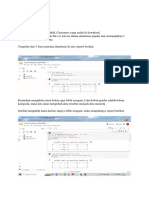
Anda mungkin juga menyukai
- Membuat Aplikasi Bisnis Menggunakan Visual Studio Lightswitch 2013Dari EverandMembuat Aplikasi Bisnis Menggunakan Visual Studio Lightswitch 2013Penilaian: 3.5 dari 5 bintang3.5/5 (7)
- Pemrograman Berorientasi Objek dengan Visual C#Dari EverandPemrograman Berorientasi Objek dengan Visual C#Penilaian: 3.5 dari 5 bintang3.5/5 (6)
- Tugas ANNDokumen10 halamanTugas ANNchintya ang98Belum ada peringkat
- Uas MCLDokumen7 halamanUas MCLdanawanBelum ada peringkat
- Praktikum Big Data M - 7Dokumen12 halamanPraktikum Big Data M - 7Ade SulisBelum ada peringkat
- Apa Itu Array 2 Dimensi ChatgptDokumen5 halamanApa Itu Array 2 Dimensi ChatgptMaulana JmbBelum ada peringkat
- Bab 4 Analisa Hasil Dan PembahasanDokumen19 halamanBab 4 Analisa Hasil Dan PembahasanDaniel ErgawantoBelum ada peringkat
- UntitledDokumen2 halamanUntitledDimas RamadhanBelum ada peringkat
- Sagita Amaria ChristieDokumen5 halamanSagita Amaria ChristieYulianti RepatiBelum ada peringkat
- Checkpoint 5 PDFDokumen6 halamanCheckpoint 5 PDFIndah KusumaningrumBelum ada peringkat
- Pointer Dan Array: Modul ArsikomDokumen33 halamanPointer Dan Array: Modul ArsikomRizkyBelum ada peringkat
- Bab 9 PemrogramanDokumen18 halamanBab 9 PemrogramanUsi ZaharaBelum ada peringkat
- Hasil Dan PembahasanDokumen13 halamanHasil Dan PembahasanDaniel ErgawantoBelum ada peringkat
- Laporan Pratikum Kelompok 7Dokumen15 halamanLaporan Pratikum Kelompok 7PujiBelum ada peringkat
- Laporan 1 Algoritma Semester 2Dokumen17 halamanLaporan 1 Algoritma Semester 2windaBelum ada peringkat
- 10s2101 Alsrudat 2021 2022 mg13 GraphDokumen20 halaman10s2101 Alsrudat 2021 2022 mg13 Graphsuprianto sitompulBelum ada peringkat
- Algorithma K MeansDokumen10 halamanAlgorithma K MeansyunbetrysiagianBelum ada peringkat
- Modul VII Kelompok 5 (Kelas A)Dokumen43 halamanModul VII Kelompok 5 (Kelas A)Maychel Riclof AkyuwenBelum ada peringkat
- UntitledDokumen3 halamanUntitledDimas RamadhanBelum ada peringkat
- Bab 10 Dhani Insha Allah AccDokumen25 halamanBab 10 Dhani Insha Allah AccM. Fikri RamadhaniBelum ada peringkat
- Kode Program Ini Adalah Sebuah Fungsi Python Yang Disusun Untuk Memeriksa Apakah Simbol Saham Yang Dimasukkan Oleh Pengguna Terdapat Dalam File CSV Yang DisediakanDokumen8 halamanKode Program Ini Adalah Sebuah Fungsi Python Yang Disusun Untuk Memeriksa Apakah Simbol Saham Yang Dimasukkan Oleh Pengguna Terdapat Dalam File CSV Yang DisediakanIndhiro Elsaday Nainggolan 28Belum ada peringkat
- CCS120 7541 092018 Modul Struktur DataDokumen39 halamanCCS120 7541 092018 Modul Struktur DataSyarifBelum ada peringkat
- Laprak Percobaan 1Dokumen40 halamanLaprak Percobaan 1habib nurulBelum ada peringkat
- TUGAS KELOMPOK CODING-dikonversiDokumen16 halamanTUGAS KELOMPOK CODING-dikonversiDita Aulia BudiarthaBelum ada peringkat
- Nur - Rochman - Muhammad - Tugas - Asistensi - 04 - Komputasi - Geofisika - B - (Incremental Search Method Polynom 9 Degree Load Mat TXT XLX XLSX Dat)Dokumen11 halamanNur - Rochman - Muhammad - Tugas - Asistensi - 04 - Komputasi - Geofisika - B - (Incremental Search Method Polynom 9 Degree Load Mat TXT XLX XLSX Dat)Nur Rochman MuhBelum ada peringkat
- Modul1 2 (SD)Dokumen7 halamanModul1 2 (SD)Isti Zahra Eka PutriBelum ada peringkat
- Materi PKBDokumen17 halamanMateri PKBStefanus Dapa LokaBelum ada peringkat
- Machine LearningDokumen6 halamanMachine LearningAndri Mattola GintingBelum ada peringkat
- Array HafisDokumen20 halamanArray HafisAnak BaruBelum ada peringkat
- Modul Praktikum MatlabDokumen68 halamanModul Praktikum MatlabSarah BibiBelum ada peringkat
- Pemrograman Praktikum MatlabDokumen68 halamanPemrograman Praktikum Matlabsarah bibiBelum ada peringkat
- Array (Algoritma)Dokumen9 halamanArray (Algoritma)mmhd.syahrul089Belum ada peringkat
- Data Preprocessing in SparkDokumen9 halamanData Preprocessing in SparkfalahrohmawanBelum ada peringkat
- ArrayDokumen14 halamanArrayZull DezeeBelum ada peringkat
- Bab 19Dokumen7 halamanBab 19Syifa Rifda SayyidahBelum ada peringkat
- Alg2 Bab2 17Dokumen9 halamanAlg2 Bab2 17Vasil YermakovBelum ada peringkat
- LAPORAN PRAKTIKUM II Metode Statistik - Zeti Zarlina - 60600123033Dokumen14 halamanLAPORAN PRAKTIKUM II Metode Statistik - Zeti Zarlina - 60600123033Xo.xoBelum ada peringkat
- Modul Praktikum Struktur DataDokumen71 halamanModul Praktikum Struktur DataMuhammad MauludinBelum ada peringkat
- Pengenalan R Dan Visualisasi DataDokumen7 halamanPengenalan R Dan Visualisasi DataAdi SuwarnoBelum ada peringkat
- Tugas Kelompok 7Dokumen16 halamanTugas Kelompok 7PujiBelum ada peringkat
- AD Modul 7. MatplotlibDokumen14 halamanAD Modul 7. MatplotlibAndika NugrahaBelum ada peringkat
- Modul 2 Array, Pointer Dan ADTDokumen17 halamanModul 2 Array, Pointer Dan ADTDevika PakpahanBelum ada peringkat
- Dokumen Memakai RDokumen18 halamanDokumen Memakai RbenikyoshiroBelum ada peringkat
- Pengertian TipeDokumen68 halamanPengertian TipeDevynurlailaBelum ada peringkat
- TgasDokumen27 halamanTgasVanquish VeinBelum ada peringkat
- TUGAS 05 ModularFungsi 2021 00Dokumen8 halamanTUGAS 05 ModularFungsi 2021 00Reza Alsa FitriBelum ada peringkat
- Soal Pemrograman - 2Dokumen11 halamanSoal Pemrograman - 2Nindya Ika PutriBelum ada peringkat
- BAB 2 - Introduction To Statictics With RDokumen16 halamanBAB 2 - Introduction To Statictics With Rritapermatasari17Belum ada peringkat
- Modul Matriks Dan VektorDokumen33 halamanModul Matriks Dan VektorRoni LimbongBelum ada peringkat
- Lap 4 - 215410047 - Puja Redho Sri Putri - If-2-4.pdf-1Dokumen14 halamanLap 4 - 215410047 - Puja Redho Sri Putri - If-2-4.pdf-1Aruarak AlbahariBelum ada peringkat
- LAPORAN 2 METODE STATISTIKA KiranaDokumen10 halamanLAPORAN 2 METODE STATISTIKA Kiranak1r4n4ayu18Belum ada peringkat
- You Vensius Pandiangan - V Ekt 2Dokumen14 halamanYou Vensius Pandiangan - V Ekt 2youvensiuspBelum ada peringkat
- ADT MatriksDokumen9 halamanADT MatriksDede IrwanBelum ada peringkat
- Pertemuan 2Dokumen14 halamanPertemuan 2Dea GayatriBelum ada peringkat
- Modul Praktikum Metode NumerikDokumen80 halamanModul Praktikum Metode Numerikmicky kololu100% (2)
- 01 Array Pointer Dan StrukturDokumen15 halaman01 Array Pointer Dan StrukturShohibul AminBelum ada peringkat
- Tugas Alpro ArrayDokumen9 halamanTugas Alpro ArrayNaura WicaksonoBelum ada peringkat
- Praktikum 04Dokumen21 halamanPraktikum 04Josh Delon TamzBelum ada peringkat
- WendiKardian A ModulPraktikum1Dokumen11 halamanWendiKardian A ModulPraktikum1WENDI KARDIANBelum ada peringkat
- Laporan Hasil Praktikum Modul 2Dokumen27 halamanLaporan Hasil Praktikum Modul 2YdhNvBelum ada peringkat
- Computer Vision TIDokumen14 halamanComputer Vision TIchintya ang98Belum ada peringkat
- Tugas Fuzzy LogicDokumen10 halamanTugas Fuzzy Logicchintya ang98Belum ada peringkat
- Virus ZikaDokumen6 halamanVirus Zikachintya ang98Belum ada peringkat
- Sejarah Pengesahan UUD & Pemilihan PresidenDokumen13 halamanSejarah Pengesahan UUD & Pemilihan Presidenchintya ang98Belum ada peringkat
- Soal Osn Kimia Tingkat Kabupaten Kota Tahun 2015 1 PDFDokumen15 halamanSoal Osn Kimia Tingkat Kabupaten Kota Tahun 2015 1 PDFAbdullah Al-Baitsu Tenri PadaBelum ada peringkat
- PPKN Bidang EkonomiDokumen4 halamanPPKN Bidang Ekonomichintya ang98Belum ada peringkat