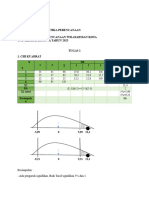
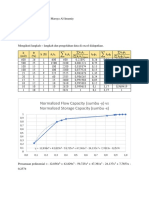
Anda mungkin juga menyukai
- Tugas Sebelum UAS STATISTIKA & PROBABILITASDokumen4 halamanTugas Sebelum UAS STATISTIKA & PROBABILITASreihan delonBelum ada peringkat
- Draf Tugas ExcelDokumen7 halamanDraf Tugas Exceltarisa suwandiBelum ada peringkat
- REGRESIDokumen7 halamanREGRESInissafau50% (2)
- REGRESI LINIERDokumen8 halamanREGRESI LINIERAndi Nurul Tariza Paraja BaslanBelum ada peringkat
- Langkah-Langkah Analisis Dan Uji Regresi Linear SederhanaDokumen6 halamanLangkah-Langkah Analisis Dan Uji Regresi Linear SederhanaFathur Insan RidhoBelum ada peringkat
- Autoregressive & Distributed LagDokumen10 halamanAutoregressive & Distributed Lagdwi astutikBelum ada peringkat
- REGRESI MULTIPLEDokumen9 halamanREGRESI MULTIPLEsea swingBelum ada peringkat
- Ayu Rahmah Citra - 1910229001 - Tugas 13 - DDE Agri B-DikonversiDokumen6 halamanAyu Rahmah Citra - 1910229001 - Tugas 13 - DDE Agri B-Dikonversianji rumbaiBelum ada peringkat
- 03 SHOFWAN HAMDANI 21383021122Dokumen6 halaman03 SHOFWAN HAMDANI 21383021122ronijaya303Belum ada peringkat
- StatistikapendidikanDokumen3 halamanStatistikapendidikanpitri handayaniBelum ada peringkat
- Soal Regresi Linear Sederhana Dan Regresi Linear BergandaDokumen10 halamanSoal Regresi Linear Sederhana Dan Regresi Linear BergandaAldonnaBelum ada peringkat
- Indah Vera 17051059 (Analisis Korelasi Bivariat)Dokumen7 halamanIndah Vera 17051059 (Analisis Korelasi Bivariat)IndahBelum ada peringkat
- StatistikapendidikanDokumen3 halamanStatistikapendidikanpitri handayaniBelum ada peringkat
- Makalah Korelasi BergandaDokumen9 halamanMakalah Korelasi BergandaMutiara A100% (1)
- Tugas 5Dokumen9 halamanTugas 5Febry Giovano SidabalokBelum ada peringkat
- Perhitungan Manual Hasil Uji Margi UtamiDokumen15 halamanPerhitungan Manual Hasil Uji Margi UtamiNur RahmanBelum ada peringkat
- Data x5CDokumen20 halamanData x5CAl13 AldianoBelum ada peringkat
- KetidakpastianDokumen14 halamanKetidakpastianFadli HermawanBelum ada peringkat
- 12 Korelasi Dan RegresiDokumen24 halaman12 Korelasi Dan RegresiyudhaBelum ada peringkat
- Kel 5 Latihan Soal BiostatistikDokumen6 halamanKel 5 Latihan Soal BiostatistikMario ChristopherBelum ada peringkat
- Tgs Korelasional Astri Yuli RamadaniDokumen4 halamanTgs Korelasional Astri Yuli RamadaniAstri yuli RamadhaniBelum ada peringkat
- Statistik PERTEMUAN 14Dokumen12 halamanStatistik PERTEMUAN 14Lulu AmansturoBelum ada peringkat
- SOAL STATISTIKDokumen10 halamanSOAL STATISTIKrafarakha rakha100% (1)
- REGRESI LINEARDokumen3 halamanREGRESI LINEARZaenal AbidinBelum ada peringkat
- REGRESIDokumen6 halamanREGRESIBINTIBelum ada peringkat
- Dwi Tri Mega Rahayu - Tugas Ekonomi 3Dokumen16 halamanDwi Tri Mega Rahayu - Tugas Ekonomi 3Dwi Tri Mega RahayuBelum ada peringkat
- OPTIMAL PENGERINGANDokumen23 halamanOPTIMAL PENGERINGANelsya Elizza RamadhaniBelum ada peringkat
- Lampiran 17-19Dokumen5 halamanLampiran 17-19SATRAMABelum ada peringkat
- Tugas Penyusunan Persamaan Empiris (Astri Handayani, 122017058p)Dokumen9 halamanTugas Penyusunan Persamaan Empiris (Astri Handayani, 122017058p)Astri Handayani100% (1)
- Jawaban UAS - Nisa Nurramdhiani KhofifahDokumen3 halamanJawaban UAS - Nisa Nurramdhiani KhofifahNisa KhofifahBelum ada peringkat
- Product MomenDokumen2 halamanProduct MomenMuhamad Fahmi Al-FariziBelum ada peringkat
- Tss Tugas Bu AgusDokumen4 halamanTss Tugas Bu AgusMuh AsdalBelum ada peringkat
- Tugas Statistika - 2242102011 - Dimas Aditia Anugerah SetiadyDokumen14 halamanTugas Statistika - 2242102011 - Dimas Aditia Anugerah SetiadyPutra SiregarBelum ada peringkat
- Tugas Ridge RegressionDokumen3 halamanTugas Ridge RegressionDil DilBelum ada peringkat
- UTSDokumen10 halamanUTSbryan zebuaBelum ada peringkat
- REGRESIDokumen5 halamanREGRESIAman NulaBelum ada peringkat
- Analisis Regresi Dengan Variabel ModeratingDokumen47 halamanAnalisis Regresi Dengan Variabel ModeratingFahmi CahyaBelum ada peringkat
- Regresi LinierDokumen3 halamanRegresi Liniergres sinagaBelum ada peringkat
- Tugas Korelasi Dan Uji Signifikansi - Fajri Yudha Pratama - 1910532041Dokumen15 halamanTugas Korelasi Dan Uji Signifikansi - Fajri Yudha Pratama - 1910532041Fajri Yudha PratamaBelum ada peringkat
- 22 A2 Luthfansyah Kuis3Dokumen12 halaman22 A2 Luthfansyah Kuis3Sony OrlandoBelum ada peringkat
- Makalah Kelompok 11 Statistik InferensialDokumen9 halamanMakalah Kelompok 11 Statistik InferensialJihan SalsabilaBelum ada peringkat
- Meet 7 Deret BerkalaDokumen9 halamanMeet 7 Deret BerkalaNurulBelum ada peringkat
- Soal Kelompok 2Dokumen4 halamanSoal Kelompok 2SuriyusufipratiwiBelum ada peringkat
- Praktikum SPSS Tugas 1Dokumen4 halamanPraktikum SPSS Tugas 1maulidi angahBelum ada peringkat
- Statprob 12 No 34Dokumen4 halamanStatprob 12 No 34DTKAzhar IzzaBelum ada peringkat
- Modul Uji KorelasiDokumen4 halamanModul Uji Korelasiputri wahyuBelum ada peringkat
- REGRESIDokumen2 halamanREGRESIRory SandikaBelum ada peringkat
- Margules Kelompok 6 PDF FreeDokumen7 halamanMargules Kelompok 6 PDF FreeChaidir RahmanBelum ada peringkat
- Pertemuan 11 - 17Dokumen25 halamanPertemuan 11 - 17muhamad irfanBelum ada peringkat
- Egrie - TUGAS1 STAT - BuneniDokumen3 halamanEgrie - TUGAS1 STAT - BuneniEgrie PabendonBelum ada peringkat
- UJI AUTOKORELASI DAN RUN TEST DENGAN MINITABDokumen10 halamanUJI AUTOKORELASI DAN RUN TEST DENGAN MINITABIkra AryantariBelum ada peringkat
- Metode Regresi Polinomial Orde 2 Orde 3Dokumen11 halamanMetode Regresi Polinomial Orde 2 Orde 3Bagaskoro Dwi PrastioBelum ada peringkat
- UJIAN AKHIR SEMESTER METODE NUMERIKDokumen6 halamanUJIAN AKHIR SEMESTER METODE NUMERIKAndrographer IDBelum ada peringkat
- REGRESIDokumen9 halamanREGRESISarah LuthfiyaBelum ada peringkat
- PR4 Muhammad 12221125Dokumen3 halamanPR4 Muhammad 12221125sukijen ucihaBelum ada peringkat
- Asistensi Statistik UasDokumen5 halamanAsistensi Statistik UasPutri Kusuma WardaniBelum ada peringkat
- 1Dokumen8 halaman1Misra Ayu NurhaeniBelum ada peringkat
- Statistik Regresi ManualDokumen3 halamanStatistik Regresi ManualInsany 841Belum ada peringkat