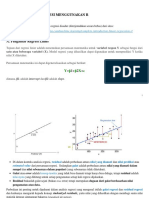
Anda mungkin juga menyukai
- Uji Asumsi KlasikDokumen16 halamanUji Asumsi KlasikRirin GustinaBelum ada peringkat
- Multikolinieritas PPT Kelompok 4Dokumen17 halamanMultikolinieritas PPT Kelompok 4Mega0% (1)
- Analisis Regresi Linier BergandaDokumen19 halamanAnalisis Regresi Linier BergandaArifian RivaldiBelum ada peringkat
- Uji Asumsi KlasikDokumen20 halamanUji Asumsi KlasikfianBelum ada peringkat
- Modul Ekonometrika II Revisi 2008 by Syofriza SyofyanDokumen92 halamanModul Ekonometrika II Revisi 2008 by Syofriza Syofyansyofriza syofyan82% (11)
- Asumsi-Asumsi Analisis Regresi PDFDokumen30 halamanAsumsi-Asumsi Analisis Regresi PDFSarah Novitriani100% (1)
- Uji Asumsi KlasikDokumen35 halamanUji Asumsi Klasik5130019049 SHOFI EKA PRATIWI100% (1)
- Asumsi KlasikDokumen26 halamanAsumsi KlasikCahyanaBelum ada peringkat
- Dokumen - Tips Uji-Asumsi-klasik Ini Yang SederhanaDokumen23 halamanDokumen - Tips Uji-Asumsi-klasik Ini Yang Sederhanaboboboyapi370Belum ada peringkat
- Materi 7 Asumsi Klasik 2019Dokumen34 halamanMateri 7 Asumsi Klasik 2019Dyah SekarBelum ada peringkat
- Minggu - Ke-7 - Uji - Asumsi - DasarDokumen32 halamanMinggu - Ke-7 - Uji - Asumsi - Dasarwinda septianaBelum ada peringkat
- Analisis Data Melalui Stata Untuk Data KeuanganDokumen39 halamanAnalisis Data Melalui Stata Untuk Data KeuanganHadi GunawanBelum ada peringkat
- Asumsi KlasikDokumen29 halamanAsumsi Klasikvera_wulan08Belum ada peringkat
- UjiDokumen20 halamanUjiAGoenk CheelBelum ada peringkat
- Analisis Regresi Menggunakan RDokumen45 halamanAnalisis Regresi Menggunakan RHamim SudarsonoBelum ada peringkat
- Hetero Dan AutoDokumen7 halamanHetero Dan AutoKadek Ary WidyawatiBelum ada peringkat
- TAMBAHANDokumen7 halamanTAMBAHANiketutpangestuBelum ada peringkat
- UAS Praktik Ekonometrika Satrio Wicaksono AjiDokumen12 halamanUAS Praktik Ekonometrika Satrio Wicaksono AjiSatrioAjiBelum ada peringkat
- 2023 - Modul Praktikum Regresi D3-Modul 12Dokumen14 halaman2023 - Modul Praktikum Regresi D3-Modul 12SANDI PALAGALANABelum ada peringkat
- BAB IV ChyaDokumen16 halamanBAB IV ChyaYua NandaBelum ada peringkat
- Pengolahan Analisis Regresi Berganda (Kak Chicka)Dokumen16 halamanPengolahan Analisis Regresi Berganda (Kak Chicka)HaerilBelum ada peringkat
- Tugas Statistika Bisnis - Analisi Regresi LinearDokumen19 halamanTugas Statistika Bisnis - Analisi Regresi LinearAndy Jaya HartantoBelum ada peringkat
- 05 TUGAS DATA PANEL - Meldiyana Trianadifa S - 1402194014Dokumen6 halaman05 TUGAS DATA PANEL - Meldiyana Trianadifa S - 1402194014meldiyana tsBelum ada peringkat
- Modul 5 STATEK & BisnisDokumen84 halamanModul 5 STATEK & BisnisIrkar YapendiBelum ada peringkat
- Bab Iv FixDokumen20 halamanBab Iv FixNajihanBelum ada peringkat
- Uji Asumsi KlasikDokumen22 halamanUji Asumsi Klasikmiu mauBelum ada peringkat
- Pemodelan SemDokumen13 halamanPemodelan SemIndra DiputraBelum ada peringkat
- Bab 4 Arin Sefida1Dokumen16 halamanBab 4 Arin Sefida1Evi QaBelum ada peringkat
- EkonometriDokumen12 halamanEkonometrisea swingBelum ada peringkat
- Regresi Dengan EviewsDokumen50 halamanRegresi Dengan Eviewsforpt indonesiaBelum ada peringkat
- Analisis DiskriminanDokumen20 halamanAnalisis DiskriminanAnwar HidayatBelum ada peringkat
- Analisis Regresi BergandaDokumen35 halamanAnalisis Regresi BergandaNafisatul UlfaBelum ada peringkat
- 11 & 12 Asumsi KlasikDokumen24 halaman11 & 12 Asumsi Klasiknad daBelum ada peringkat
- Metlit-11-2021-Soal Ada Di Slide Halaman 40Dokumen41 halamanMetlit-11-2021-Soal Ada Di Slide Halaman 40Delin ChristiBelum ada peringkat
- Regresi Linier SederhanaDokumen27 halamanRegresi Linier SederhanaRahmah DesfitriBelum ada peringkat
- BAB III. 8 MeiDokumen7 halamanBAB III. 8 MeiZaenal AbidinBelum ada peringkat
- HeteroscedasticityDokumen11 halamanHeteroscedasticityRoro Ayu KusumadeviBelum ada peringkat
- Re GresiDokumen4 halamanRe GresiRum DewiBelum ada peringkat
- Ridge Reggession (Hidayati Indah R)Dokumen37 halamanRidge Reggession (Hidayati Indah R)Vina WylasmiBelum ada peringkat
- EkonometrikaDokumen15 halamanEkonometrikaangelBelum ada peringkat
- Bab 7 Uji Asumsi KlsikDokumen33 halamanBab 7 Uji Asumsi KlsikWahyudi YudhiBelum ada peringkat
- PPDPA EA Tugas 11 Rizki Akbar Rahmadani 1932500562Dokumen6 halamanPPDPA EA Tugas 11 Rizki Akbar Rahmadani 1932500562RavindaFajrillahBelum ada peringkat
- Prak Statistika - Bab 4 Uji Asumsi Klasik Data PrimerDokumen28 halamanPrak Statistika - Bab 4 Uji Asumsi Klasik Data PrimerMuslimatul ABelum ada peringkat
- Uji Asumsi KlasikDokumen29 halamanUji Asumsi KlasikPutri Hasanah HarahapBelum ada peringkat
- Multikol Dan AutokolDokumen13 halamanMultikol Dan AutokolAgustina IsviandariBelum ada peringkat
- Pengertian OLSDokumen2 halamanPengertian OLSSebrindaa GinaBelum ada peringkat
- Kelompok 4 Ekonometrik UASDokumen9 halamanKelompok 4 Ekonometrik UASDedeh sunarsihBelum ada peringkat
- Bab IvDokumen19 halamanBab IvRositaBelum ada peringkat
- Asumsi KlasikDokumen19 halamanAsumsi KlasikNurul WahidaBelum ada peringkat
- Uji Asumsi Klasik Dengan SPSS 16.0Dokumen11 halamanUji Asumsi Klasik Dengan SPSS 16.0Adinda Dwi KurniasihBelum ada peringkat
- Bab 4Dokumen13 halamanBab 406 andrew putra hartantoBelum ada peringkat
- Uji Data (Sep 2023)Dokumen40 halamanUji Data (Sep 2023)Putri SridewiBelum ada peringkat
- Bab III JordanDokumen10 halamanBab III JordanMega R LubisBelum ada peringkat
- Uji MultikolinerialitasDokumen10 halamanUji MultikolinerialitasBaiq AlfalihunBelum ada peringkat
- Modern and Minimal Business Proposal Presentation - 20230809 - 142646 - 0000Dokumen21 halamanModern and Minimal Business Proposal Presentation - 20230809 - 142646 - 0000Revy Diaz FadhilahBelum ada peringkat
- Mei Siti+maryatiDokumen14 halamanMei Siti+maryatiRevy Diaz FadhilahBelum ada peringkat
- Uji Independent T TestDokumen15 halamanUji Independent T TestRevy Diaz FadhilahBelum ada peringkat
- TM 4 - IdeationDokumen28 halamanTM 4 - IdeationRevy Diaz FadhilahBelum ada peringkat
- Human Resource Management - Auto.idDokumen6 halamanHuman Resource Management - Auto.idRevy Diaz FadhilahBelum ada peringkat
- Green Candidate Selection - En.idDokumen16 halamanGreen Candidate Selection - En.idRevy Diaz FadhilahBelum ada peringkat
- Logbook Penganggaran PerusahaanDokumen1 halamanLogbook Penganggaran PerusahaanRevy Diaz FadhilahBelum ada peringkat
- UAS - ALKS - Kelompok 8 - Perhitngan ExcelDokumen99 halamanUAS - ALKS - Kelompok 8 - Perhitngan ExcelRevy Diaz FadhilahBelum ada peringkat
- Surat Pernyataan Orisinil CM-CMA 2022 KOSONGANDokumen1 halamanSurat Pernyataan Orisinil CM-CMA 2022 KOSONGANRevy Diaz FadhilahBelum ada peringkat
- TM 13 - Mazhab Ekonomi Islam KontemporerDokumen28 halamanTM 13 - Mazhab Ekonomi Islam KontemporerRevy Diaz FadhilahBelum ada peringkat
- SPEIDokumen26 halamanSPEIRevy Diaz FadhilahBelum ada peringkat