Anda mungkin juga menyukai
- Membuat Aplikasi Bisnis Menggunakan Visual Studio Lightswitch 2013Dari EverandMembuat Aplikasi Bisnis Menggunakan Visual Studio Lightswitch 2013Penilaian: 3.5 dari 5 bintang3.5/5 (7)
- (NEW) Template Presentasi UGM 5Dokumen4 halaman(NEW) Template Presentasi UGM 5Muhrazaq FarikBelum ada peringkat
- Bab 4 RNGDokumen34 halamanBab 4 RNGirwantika100% (1)
- Tugas SimulasiDokumen12 halamanTugas SimulasiIndri FebriantiBelum ada peringkat
- DAA-PERTEMUAN 05-Analisis Algoritma Non-RekursifDokumen14 halamanDAA-PERTEMUAN 05-Analisis Algoritma Non-RekursifWildanySihabBelum ada peringkat
- Analisis Dan Implementasi Data Mining Dengan Algoritma Apriori Dan Hash-Based Technique Pada Algoritma Genetika Untuk Mereduksi Jumlah Kemungkinan Solusi Dalam Proses Penjadwalan KuliahDokumen5 halamanAnalisis Dan Implementasi Data Mining Dengan Algoritma Apriori Dan Hash-Based Technique Pada Algoritma Genetika Untuk Mereduksi Jumlah Kemungkinan Solusi Dalam Proses Penjadwalan KuliahDelfi Kusuma WardhaniBelum ada peringkat
- Pertemuan 2Dokumen20 halamanPertemuan 2M. REZA APBelum ada peringkat
- Sistem Informasi Penjualan Tiket Bus Cv. XXXDokumen10 halamanSistem Informasi Penjualan Tiket Bus Cv. XXXDwii SunshiineBelum ada peringkat
- Analisa Sistem Pembayaran Biaya KuliahDokumen29 halamanAnalisa Sistem Pembayaran Biaya KuliahHarsan FebrianBelum ada peringkat
- Panduan Penulisan KP Universitas PamulangDokumen18 halamanPanduan Penulisan KP Universitas PamulangAyuza SaepullohBelum ada peringkat
- Tugas Komputasi Manual 1Dokumen3 halamanTugas Komputasi Manual 1Eko PotterBelum ada peringkat
- Analisis PerbandinganDokumen8 halamanAnalisis PerbandinganAditya Maulida MBelum ada peringkat
- Transversal GraphDokumen4 halamanTransversal GraphTANIA FIDELA AMANDABelum ada peringkat
- Tugas 1 Penelitian Operational 2 2021-2022Dokumen2 halamanTugas 1 Penelitian Operational 2 2021-2022Atika FridausBelum ada peringkat
- FeriApriawanto - APSI KJ002 - Tugas Sesi 12Dokumen5 halamanFeriApriawanto - APSI KJ002 - Tugas Sesi 12Feri ApriawantoBelum ada peringkat
- Sistem Operasi 2010 Q2K KunciDokumen2 halamanSistem Operasi 2010 Q2K KunciNusqi DwiBelum ada peringkat
- Algoritma K-Nearest Neighbor (K-NN)Dokumen10 halamanAlgoritma K-Nearest Neighbor (K-NN)candraBelum ada peringkat
- Analisis Algoritma Non Rekursif Dan RekursifDokumen36 halamanAnalisis Algoritma Non Rekursif Dan Rekursifpaprian0% (1)
- 11-Diagram Tabel KeputusanDokumen22 halaman11-Diagram Tabel KeputusanAvenueeBelum ada peringkat
- UTS Ilmu FiqihDokumen1 halamanUTS Ilmu FiqihDetasariBelum ada peringkat
- Jawaban Kisi-Kisi Sistem TerdistribusiDokumen25 halamanJawaban Kisi-Kisi Sistem TerdistribusiVickey NehalemBelum ada peringkat
- Transposisi ChiperDokumen17 halamanTransposisi ChiperFians OnllineeBelum ada peringkat
- DPPL WEB PPDB Online - Informatika 2018 Universitas TelkomDokumen35 halamanDPPL WEB PPDB Online - Informatika 2018 Universitas TelkomACHMAD SALIM AIMANBelum ada peringkat
- Konsep Metode Hash Searc1Dokumen15 halamanKonsep Metode Hash Searc1Subandi WahyudiBelum ada peringkat
- Kuliah 3 - Data Warehouse Dan OLAPDokumen35 halamanKuliah 3 - Data Warehouse Dan OLAPbrilili100% (1)
- BAB 2 Project Rekayasa Perangkat LunakDokumen11 halamanBAB 2 Project Rekayasa Perangkat LunakDio Bian PriatamaBelum ada peringkat
- Analisis Karya Tulis Ilmiah Pak Iwan-Kel. KapakDokumen13 halamanAnalisis Karya Tulis Ilmiah Pak Iwan-Kel. KapakUpin Ipin ApinBelum ada peringkat
- Sistem Informasi Retail MinimarketDokumen11 halamanSistem Informasi Retail MinimarketAzizNugrohoBelum ada peringkat
- Analisis Algoritma Sequential Search Dan Binary Search Pada Big DataDokumen6 halamanAnalisis Algoritma Sequential Search Dan Binary Search Pada Big DataYoga ReligiaBelum ada peringkat
- Socket, RPC Dan RMIDokumen22 halamanSocket, RPC Dan RMIKadek Dede Hendra KusumaBelum ada peringkat
- Dunn Index Dan DB IndexDokumen4 halamanDunn Index Dan DB IndexPinsar SiphomBelum ada peringkat
- Bab 4 Analisis LeksikalDokumen7 halamanBab 4 Analisis LeksikalKatsuoOnoBelum ada peringkat
- Tugas Uml Rental KasetDokumen7 halamanTugas Uml Rental KasetHeru ApBelum ada peringkat
- Modul 10 Cip311Dokumen17 halamanModul 10 Cip311esa unggulBelum ada peringkat
- MATERI Kecerdasan BuatanDokumen19 halamanMATERI Kecerdasan BuatanndioBelum ada peringkat
- Rangkuman Materi Binary Search TreeDokumen20 halamanRangkuman Materi Binary Search TreerahelBelum ada peringkat
- Ekivalensi Nfa DfaDokumen11 halamanEkivalensi Nfa DfaMuhammad NafisBelum ada peringkat
- Contoh Makalah KanbanDokumen2 halamanContoh Makalah KanbanNindi AyuningtyasBelum ada peringkat
- Data Mining WalmartDokumen5 halamanData Mining WalmartRidwan HsBelum ada peringkat
- Tabel 3.1 Perbedaan Metode Penelitian Kualitatif Dan KuantitatifDokumen9 halamanTabel 3.1 Perbedaan Metode Penelitian Kualitatif Dan KuantitatifRahmatch M U SmileBelum ada peringkat
- Tpl0302 06 Basis Data RelasionalDokumen15 halamanTpl0302 06 Basis Data RelasionalMister TompelBelum ada peringkat
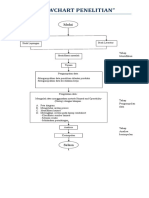
- Flowchart PenelitianDokumen1 halamanFlowchart PenelitianjokyBelum ada peringkat
- Proposal Sistem PakarDokumen12 halamanProposal Sistem PakarWieryo SelowBelum ada peringkat
- Proposal Pembuatan Website MusikDokumen6 halamanProposal Pembuatan Website MusikTriwidyastut JBelum ada peringkat
- Contoh Krangka PikirDokumen2 halamanContoh Krangka Pikirkimimaru86Belum ada peringkat
- State of The Art Information SystemsDokumen62 halamanState of The Art Information SystemsDarmanta Sukrianto SiregarBelum ada peringkat
- Analisis Kebutuhan Perangkat Lunak PDFDokumen11 halamanAnalisis Kebutuhan Perangkat Lunak PDFAyu OktaaBelum ada peringkat
- Pembuatan Aplikasi Perhitungan Transaksi Dengan JavaDokumen15 halamanPembuatan Aplikasi Perhitungan Transaksi Dengan JavaAnggrelia PradinaBelum ada peringkat
- Analisa Website BASARNASDokumen58 halamanAnalisa Website BASARNASSky BayBelum ada peringkat
- SKPL-OO Sistem Penjualan Obat - UdinusDokumen9 halamanSKPL-OO Sistem Penjualan Obat - UdinusFajar HidayatBelum ada peringkat
- Jurnal Praktikum Mini 4WDDokumen22 halamanJurnal Praktikum Mini 4WDMuhammad IhsanBelum ada peringkat
- 01 - Logika Dan Pembuktian CH 1.1 - 1.5Dokumen64 halaman01 - Logika Dan Pembuktian CH 1.1 - 1.5leni marlinaBelum ada peringkat
- Laporan Modul 1 Pemrograman Perangkat BergerakDokumen5 halamanLaporan Modul 1 Pemrograman Perangkat BergerakYanuar AliffioBelum ada peringkat
- 1001 Judul Skripsi TeknikDokumen36 halaman1001 Judul Skripsi TeknikMustika Sari SoneyoungBelum ada peringkat
- Go FoodDokumen13 halamanGo FoodSone Vipgd0% (1)
- Cara Menulis Skripsi Dengan Cepat Dan Sistematika Proposal SkripsiDokumen6 halamanCara Menulis Skripsi Dengan Cepat Dan Sistematika Proposal SkripsiIman Lake Sajach CukupBelum ada peringkat
- Space Time and Trade Offs.Dokumen10 halamanSpace Time and Trade Offs.Ayu KrisnasariBelum ada peringkat
- Pertemuan Pengantar SD Dan Modul Array (Larik)Dokumen56 halamanPertemuan Pengantar SD Dan Modul Array (Larik)Alghi RifghiBelum ada peringkat
- Perancangan DatabaseDokumen25 halamanPerancangan DatabaseRizkaOkta PutriBelum ada peringkat
- BAB IV-Metode Information Retrival (IR)Dokumen8 halamanBAB IV-Metode Information Retrival (IR)Winda LisaBelum ada peringkat
- Relevance Feedback Adalah Mengambil Hasil Dari Pencarian Yang Dilakukan Dengan Menggunakan Suatu Query Dan Menggunakan Informasi Tersebut Untuk Menentukan Apakah Hasil Pencarian Tersebut Relevan Untuk MelakDokumen1 halamanRelevance Feedback Adalah Mengambil Hasil Dari Pencarian Yang Dilakukan Dengan Menggunakan Suatu Query Dan Menggunakan Informasi Tersebut Untuk Menentukan Apakah Hasil Pencarian Tersebut Relevan Untuk MelakHeri SimbolonBelum ada peringkat
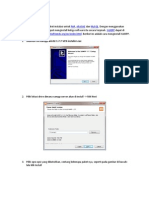
- Intallasi XAMPPDokumen4 halamanIntallasi XAMPPMuhammad SofyanBelum ada peringkat
- VSM 2Dokumen21 halamanVSM 2Heri SimbolonBelum ada peringkat
- KisiDokumen1 halamanKisiHeri SimbolonBelum ada peringkat