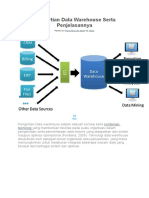
Anda mungkin juga menyukai
- Pendekatan sederhana untuk SEO: Bagaimana memahami dasar-dasar optimasi mesin pencari dengan cara yang sederhana dan praktis melalui jalur penemuan non-spesialis untuk semua orangDari EverandPendekatan sederhana untuk SEO: Bagaimana memahami dasar-dasar optimasi mesin pencari dengan cara yang sederhana dan praktis melalui jalur penemuan non-spesialis untuk semua orangBelum ada peringkat
- Data WarehouseDokumen24 halamanData WarehouseM. Riski RamadaniBelum ada peringkat
- Analisis swot dalam 4 langkah: Bagaimana menggunakan matriks SWOT untuk membuat perbedaan dalam karir dan bisnisDari EverandAnalisis swot dalam 4 langkah: Bagaimana menggunakan matriks SWOT untuk membuat perbedaan dalam karir dan bisnisPenilaian: 4.5 dari 5 bintang4.5/5 (3)
- Pertemuan 4 Data WarehouseDokumen19 halamanPertemuan 4 Data WarehouseLisaa NrhlsaBelum ada peringkat
- Mari Belajar Pemrograman Berorientasi Objek menggunakan Visual C# 6.0Dari EverandMari Belajar Pemrograman Berorientasi Objek menggunakan Visual C# 6.0Penilaian: 4 dari 5 bintang4/5 (16)
- DW KUIS ESSAYDokumen8 halamanDW KUIS ESSAYkh androBelum ada peringkat
- Definisi Data MartDokumen38 halamanDefinisi Data MartrinaldiBelum ada peringkat
- 02 Konsep Data WarehouseDokumen30 halaman02 Konsep Data Warehousefani afBelum ada peringkat
- 02 Konsep Data WarehouseDokumen30 halaman02 Konsep Data WarehouseDedekBelum ada peringkat
- Perancangan Data Warehouse Tirta Anugrah OkDokumen9 halamanPerancangan Data Warehouse Tirta Anugrah OkmustofaBelum ada peringkat
- Data Warehouse (1)Dokumen30 halamanData Warehouse (1)Siva RahmatullahBelum ada peringkat
- Materi 2 - Munti Parsi HolanDokumen18 halamanMateri 2 - Munti Parsi HolanMunti Holan Boken-kaBelum ada peringkat
- DW DAN DM UNTUK PENGAMBILAN KEPUTUSANDokumen5 halamanDW DAN DM UNTUK PENGAMBILAN KEPUTUSANYan Cita BagoezBelum ada peringkat
- Data Warehouse & ETLDokumen8 halamanData Warehouse & ETLyifanBelum ada peringkat
- DW-WAREHOUSEDokumen5 halamanDW-WAREHOUSENaylaBelum ada peringkat
- DW40Dokumen3 halamanDW40Deny SetiawanBelum ada peringkat
- Tugas TBD - Sweetly Miracly Manopo - 220211060246Dokumen7 halamanTugas TBD - Sweetly Miracly Manopo - 220211060246Sweetly ManopoBelum ada peringkat
- Materi Basis Data LanjuttDokumen14 halamanMateri Basis Data LanjuttTri SukmaBelum ada peringkat
- DW-BAB1Dokumen20 halamanDW-BAB1Kristian JuniantoBelum ada peringkat
- DW C Kelompok 6 UTSDokumen22 halamanDW C Kelompok 6 UTStirta watiBelum ada peringkat
- Tugas DATAWAREHOUSEDokumen4 halamanTugas DATAWAREHOUSESMK BHAKTI LOA JANANBelum ada peringkat
- Cara Kerja ETL dalam Data WarehouseDokumen4 halamanCara Kerja ETL dalam Data WarehouseMeira JamilahBelum ada peringkat
- Data WarehouseDokumen4 halamanData WarehouseErick KusumaBelum ada peringkat
- MODUL 1 Data WarehouseDokumen13 halamanMODUL 1 Data WarehouseSiskaCahayaSholichahBelum ada peringkat
- Materi Chapter 3Dokumen6 halamanMateri Chapter 3Alex XanderBelum ada peringkat
- SLIDE Data WarehouseDokumen19 halamanSLIDE Data WarehouseIkaLoBelum ada peringkat
- Bi 3 DWDokumen31 halamanBi 3 DWYudi AWBelum ada peringkat
- DWBIDokumen24 halamanDWBIsuryadiarif66Belum ada peringkat
- Ujian Tengah Semester Data Warehousing - Muhammad Syahrizal RahmandhaniDokumen4 halamanUjian Tengah Semester Data Warehousing - Muhammad Syahrizal RahmandhaniRahmandhani GBelum ada peringkat
- Pengertian Data Warehouse Serta PenjelasannyaDokumen5 halamanPengertian Data Warehouse Serta Penjelasannyajamilul hamdiBelum ada peringkat
- Materi 2 DWDokumen16 halamanMateri 2 DWKas lahBelum ada peringkat
- DBvsDWDokumen4 halamanDBvsDWM teguh iman hasan ayag- eyegBelum ada peringkat
- DW-ArsitekturDokumen21 halamanDW-ArsitekturRian WibowoBelum ada peringkat
- Introduction To Data Warehousing ConceptsDokumen18 halamanIntroduction To Data Warehousing ConceptsMia Hotmaria TambunanBelum ada peringkat
- ARTIKEL Data WarehouseDokumen7 halamanARTIKEL Data WarehouseTaufiq HidayatBelum ada peringkat
- UntitledDokumen6 halamanUntitled20-0280MuhammadDafaBelum ada peringkat
- Data WarehouseDokumen11 halamanData WarehouseKasih Budi PrabowoBelum ada peringkat
- Makalah Data WarehouseDokumen6 halamanMakalah Data WarehouseDewa WidjaBelum ada peringkat
- Tugas Proposal DatawarehouseDokumen10 halamanTugas Proposal DatawarehouseSyafiul Goingz UnderboneBelum ada peringkat
- QUIZ 1 DW PPA48 YurisaMarherlin 44Dokumen4 halamanQUIZ 1 DW PPA48 YurisaMarherlin 44Hyuriii 707Belum ada peringkat
- DW-KETENTUANDokumen22 halamanDW-KETENTUANLuthfi FebrianaBelum ada peringkat
- Laporan Tugas1 SI4501 Kelompok7Dokumen30 halamanLaporan Tugas1 SI4501 Kelompok7sekar adjiBelum ada peringkat
- EDWH ToolsDokumen44 halamanEDWH ToolsFahmiHamdaniBelum ada peringkat
- Uts DatawerehouseDokumen4 halamanUts DatawerehouseYogi ParmanaBelum ada peringkat
- MAKALAH TUGAS 15 DATE WAREHOUSE-Dimas Galih ADokumen11 halamanMAKALAH TUGAS 15 DATE WAREHOUSE-Dimas Galih ADimas GalihBelum ada peringkat
- Arsitektur DWDokumen28 halamanArsitektur DWTHROME sBelum ada peringkat
- Tugas Makalah Data WarehouseDokumen22 halamanTugas Makalah Data WarehouseBiru Maghib0% (1)
- Data WarehouseDokumen49 halamanData WarehouseVanellopee WitchBelum ada peringkat
- Sistem Informasi Manajemen Bab 3Dokumen6 halamanSistem Informasi Manajemen Bab 3Kevin JayadiBelum ada peringkat
- Penerapan Data Warehouse Untuk Pengelolaan Penjualan Toko Serba Ada (Amalina - Salsabila)Dokumen5 halamanPenerapan Data Warehouse Untuk Pengelolaan Penjualan Toko Serba Ada (Amalina - Salsabila)Salsabila qatrunnadaBelum ada peringkat
- Muhammad Azzam Nur Alwi Mansyur - 0110219060 - Uts - DWDokumen7 halamanMuhammad Azzam Nur Alwi Mansyur - 0110219060 - Uts - DWGinBelum ada peringkat
- 56Dokumen15 halaman56Setyo Budi MulyonoBelum ada peringkat
- Tugas Data WarehouseDokumen3 halamanTugas Data WarehouseDinda SafitriBelum ada peringkat
- Data Warehouse Dan Business IntelligenceDokumen7 halamanData Warehouse Dan Business IntelligenceCentaury AlfaBelum ada peringkat
- Reading 1 - Data WarehouseDokumen8 halamanReading 1 - Data WarehousehilalBelum ada peringkat
- Materi 01 Pengantar Big Data EngineeringDokumen18 halamanMateri 01 Pengantar Big Data EngineeringLalulalang 1302Belum ada peringkat
- 01-Modul DW IntroDokumen12 halaman01-Modul DW IntroSyarief HidayatBelum ada peringkat
- Makalah Tugas 15 Date Warehouse-Muhamad RosidinDokumen11 halamanMakalah Tugas 15 Date Warehouse-Muhamad RosidinDimas GABelum ada peringkat
- Konsep Data WarehouseDokumen4 halamanKonsep Data WarehouseDinas Kominfo MalangBelum ada peringkat
- Analisis Big Data dan Gudang Data untuk Meningkatkan BisnisDokumen7 halamanAnalisis Big Data dan Gudang Data untuk Meningkatkan BisnisNia Azura SariBelum ada peringkat
- Haryo 200101010124 Si302 PemrogramanwebDokumen4 halamanHaryo 200101010124 Si302 PemrogramanwebharyoBelum ada peringkat
- Pertemuan 15 Interpersonal SkillDokumen3 halamanPertemuan 15 Interpersonal SkillenterdieBelum ada peringkat
- Kurikulum ManajemenDokumen2 halamanKurikulum ManajemenharyoBelum ada peringkat
- Lecture Note Pertemuan 9 10 11Dokumen7 halamanLecture Note Pertemuan 9 10 11haryoBelum ada peringkat
- Skrip LombaDokumen3 halamanSkrip LombaharyoBelum ada peringkat
- Tugas Kelompok (Kelas 401 Dan 402)Dokumen1 halamanTugas Kelompok (Kelas 401 Dan 402)haryoBelum ada peringkat
- RANCANGANDokumen23 halamanRANCANGANharyoBelum ada peringkat
- CYBERIANDokumen23 halamanCYBERIANharyoBelum ada peringkat
- Haryo 200101010124 Si302 PemrogramanwebDokumen4 halamanHaryo 200101010124 Si302 PemrogramanwebharyoBelum ada peringkat
- Ujian Tengah Semester Aljabar Linier SI-02 UNSiber 2021Dokumen1 halamanUjian Tengah Semester Aljabar Linier SI-02 UNSiber 2021haryoBelum ada peringkat
- Soal UTS RPLDokumen1 halamanSoal UTS RPLharyoBelum ada peringkat
- Uas RPL Si602 Si601Dokumen2 halamanUas RPL Si602 Si601haryoBelum ada peringkat
- Soal UTSDokumen2 halamanSoal UTSharyoBelum ada peringkat
- 01 PPT Pertemuan 1 AljabarDokumen9 halaman01 PPT Pertemuan 1 AljabarharyoBelum ada peringkat
- Soal UAS AljabarDokumen1 halamanSoal UAS AljabarharyoBelum ada peringkat
- Soal UTS APBDokumen2 halamanSoal UTS APBharyoBelum ada peringkat
- Soal UAS APBDokumen1 halamanSoal UAS APBharyoBelum ada peringkat
- CrewdibleDokumen22 halamanCrewdiblerudyBelum ada peringkat
- Soal UTS Estetika HumanismeDokumen2 halamanSoal UTS Estetika HumanismeharyoBelum ada peringkat
- UTS SistemOperasiDokumen2 halamanUTS SistemOperasiharyoBelum ada peringkat
- Soal UASDokumen2 halamanSoal UASharyoBelum ada peringkat
- STRUKTUR DIREKTORI DAN FILE PADA WINDOWS DAN LINUXDokumen1 halamanSTRUKTUR DIREKTORI DAN FILE PADA WINDOWS DAN LINUXharyoBelum ada peringkat