Anda mungkin juga menyukai
- Parameter Interpretation in Logistic Regression Models For Dicotomus Independent VariableDokumen6 halamanParameter Interpretation in Logistic Regression Models For Dicotomus Independent Variablemuha antoBelum ada peringkat
- Tugas ANMUL1-Cylvia Nissa Steffani-NIM 466511Dokumen19 halamanTugas ANMUL1-Cylvia Nissa Steffani-NIM 466511Cylvia NissaBelum ada peringkat
- Turunan Integral MatriksDokumen35 halamanTurunan Integral Matriksirfina sari100% (1)
- Teknik Analisis DataDokumen8 halamanTeknik Analisis Datakikirak27Belum ada peringkat
- Model Regresi PoissonDokumen38 halamanModel Regresi PoissonNusar Hajarisman100% (1)
- Regresi Logistik Ordina1Dokumen2 halamanRegresi Logistik Ordina1ahmad haryadiBelum ada peringkat
- Pertemuan Ke Xiv StatmatDokumen7 halamanPertemuan Ke Xiv StatmatAKR. ChdriBelum ada peringkat
- BAB 5 F.Distribusi Diskrit PDFDokumen8 halamanBAB 5 F.Distribusi Diskrit PDFIntan FebriyanBelum ada peringkat
- Nurazizah MahdinDokumen5 halamanNurazizah Mahdincici safitriBelum ada peringkat
- Faktor AnalisisDokumen15 halamanFaktor AnalisisRazor Pandawa2Belum ada peringkat
- LikelihoodDokumen10 halamanLikelihoodErika FitriaBelum ada peringkat
- Variabel AcakDokumen20 halamanVariabel AcakrayndirydhoBelum ada peringkat
- Materi Pokok 12 Sebaran Peubah Acak Diskrit Khusus 2Dokumen9 halamanMateri Pokok 12 Sebaran Peubah Acak Diskrit Khusus 2IKA SORVIANTIBelum ada peringkat
- 3.iwa - Ipvol18 1 2009Dokumen9 halaman3.iwa - Ipvol18 1 2009Afysha DiadaraBelum ada peringkat
- 978 1963 1 PBDokumen5 halaman978 1963 1 PBHerlin FransiskaBelum ada peringkat
- Regresi Logistik BinerDokumen36 halamanRegresi Logistik BinerDeden IstiawanBelum ada peringkat
- Peubah AcakDokumen14 halamanPeubah AcakErika Kristina NainggolanBelum ada peringkat
- Teori KlasifikasiDokumen24 halamanTeori KlasifikasiDenandika PutriBelum ada peringkat
- Ringkasan Kelompok 2 FIXDokumen16 halamanRingkasan Kelompok 2 FIXJose Carlos TahituBelum ada peringkat
- Toaz - Info Turunan Integral Matriks PRDokumen35 halamanToaz - Info Turunan Integral Matriks PRred 16Belum ada peringkat
- Estimasi Titik 2023Dokumen35 halamanEstimasi Titik 2023Aditya Faizal AchmadBelum ada peringkat
- Materi Komstat Minggu Ke-13 2020Dokumen9 halamanMateri Komstat Minggu Ke-13 2020Muhammad Fikri A SBelum ada peringkat
- Pemeriksaan Metodologi RisikoDokumen4 halamanPemeriksaan Metodologi RisikoScribdTranslationsBelum ada peringkat
- Cheb YshevDokumen12 halamanCheb Yshevsussy.rebab19787Belum ada peringkat
- Tugas Terstruktur 2Dokumen7 halamanTugas Terstruktur 2Khairul JawadBelum ada peringkat
- Distribusi Satu Peubah AcakDokumen5 halamanDistribusi Satu Peubah AcakDanuTahtaWicaksanaBelum ada peringkat
- Linear Quadratic Regulator PDFDokumen30 halamanLinear Quadratic Regulator PDFReyhan RBelum ada peringkat
- Bahan Kuliah Minggu 7Dokumen11 halamanBahan Kuliah Minggu 7Annas HanifBelum ada peringkat
- Metode Firth (PML) PDFDokumen7 halamanMetode Firth (PML) PDFFrisca UlinaBelum ada peringkat
- 2.persamaan Diferensial Ordiner OrdeDokumen49 halaman2.persamaan Diferensial Ordiner OrdeNurchalisBelum ada peringkat
- LKM 1Dokumen24 halamanLKM 1Sinaga SinagaBelum ada peringkat
- 3325-Article Text-6615-1-10-20180130Dokumen11 halaman3325-Article Text-6615-1-10-20180130NalaratihBelum ada peringkat
- Iwan 5Dokumen18 halamanIwan 5Rini RestinaBelum ada peringkat
- Kelompok 3 - Mekanika LagrangianDokumen20 halamanKelompok 3 - Mekanika LagrangianindahBelum ada peringkat
- Statmat 1Dokumen20 halamanStatmat 1NurichaBelum ada peringkat
- Pembahasan UTS 2022Dokumen15 halamanPembahasan UTS 2022Grace Lucyana KoesnadiBelum ada peringkat
- Muhammad HafizhDokumen8 halamanMuhammad Hafizhmtri22.polbanBelum ada peringkat
- Materi 7-Analisis FaktorDokumen35 halamanMateri 7-Analisis FaktorsofhiaputriBelum ada peringkat
- Kuliah4 - Peubah AcakDokumen50 halamanKuliah4 - Peubah AcakDilla DilagaBelum ada peringkat
- Bag II - BAB 1 - RalatDokumen6 halamanBag II - BAB 1 - RalatCaseyBelum ada peringkat
- Statistika Pertemuan 3 66235 - Sebaran Peubah Acak 1Dokumen25 halamanStatistika Pertemuan 3 66235 - Sebaran Peubah Acak 1Linda FebrianiBelum ada peringkat
- Ketaksamaan Chebyshev1Dokumen16 halamanKetaksamaan Chebyshev1Chusna AmaliaBelum ada peringkat
- PraktikumIX - Sebaran Peluang KhususDokumen3 halamanPraktikumIX - Sebaran Peluang KhususShofy Afafiah Dzaki MuflihahBelum ada peringkat
- Distribusi Variabel Acak DiskritDokumen11 halamanDistribusi Variabel Acak DiskritChristo LembangBelum ada peringkat
- Karya IlmiahDokumen10 halamanKarya IlmiahAllis WetBelum ada peringkat
- Analisis Regresi Logistik OrdinalDokumen4 halamanAnalisis Regresi Logistik Ordinalluluanata sanurBelum ada peringkat
- Distribusi Variabel AcakDokumen19 halamanDistribusi Variabel AcakPrimawan Satrio Bindono100% (1)
- Peubah Acak Sesi 9Dokumen4 halamanPeubah Acak Sesi 9SESA PUTRIBelum ada peringkat
- Dasar Dasar Teori Peluang3Dokumen9 halamanDasar Dasar Teori Peluang3Annisa Putri UtamiBelum ada peringkat
- Proses StokastikDokumen20 halamanProses StokastikNursiah Manggasa StatBelum ada peringkat
- Modul 8 Peubah Acak KontinuDokumen9 halamanModul 8 Peubah Acak KontinuAkhmad FauzanBelum ada peringkat
- StatMat 2 Kelompok 5Dokumen6 halamanStatMat 2 Kelompok 5Mirandaa Sukma NBelum ada peringkat
- Makalah Mancova FixDokumen15 halamanMakalah Mancova FixRun Far PiscessBelum ada peringkat
- Model Marginal Logistik Biner Untuk Data LongitudinalDokumen11 halamanModel Marginal Logistik Biner Untuk Data LongitudinalIsmiBelum ada peringkat
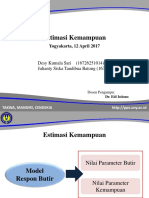
- Estimasi KemampuanDokumen25 halamanEstimasi KemampuanDesy Kumala100% (1)
- UTS UMK-Konsep Matematika DasarDokumen1 halamanUTS UMK-Konsep Matematika DasarDesy KumalaBelum ada peringkat
- Hukum NewtonDokumen12 halamanHukum NewtonDesy KumalaBelum ada peringkat
- UTS UMK-Konsep Matematika DasarDokumen1 halamanUTS UMK-Konsep Matematika DasarDesy KumalaBelum ada peringkat
- 2017 Modul Praktikum Komputasi Geofisika-1 PDFDokumen29 halaman2017 Modul Praktikum Komputasi Geofisika-1 PDFIcha Untari MeijiBelum ada peringkat
- Jadwal Uas Gasal 2017-2018 Pps UnyDokumen126 halamanJadwal Uas Gasal 2017-2018 Pps UnyDesy KumalaBelum ada peringkat
- Makalah Estimasi Kemampuan FDokumen20 halamanMakalah Estimasi Kemampuan FDesy KumalaBelum ada peringkat
- Angket Rasa Ingin Tahu (TRB)Dokumen4 halamanAngket Rasa Ingin Tahu (TRB)Desy Kumala100% (2)
- E PubDokumen16 halamanE PubDesy KumalaBelum ada peringkat