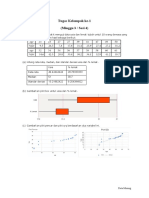
Anda mungkin juga menyukai
- TP2 W7 S11 R0 TsabitDokumen4 halamanTP2 W7 S11 R0 TsabitTsabitAlaykRidhollah50% (2)
- Tugas Kelompok Ke-4 Week 9, Session 14: A. Human Resource ManagementDokumen6 halamanTugas Kelompok Ke-4 Week 9, Session 14: A. Human Resource ManagementTsabitAlaykRidhollah100% (1)
- Tugas Personal Ke-2 (Minggu 8 / Sesi 13) : Gambar 1. ContohDokumen8 halamanTugas Personal Ke-2 (Minggu 8 / Sesi 13) : Gambar 1. ContohSalesaBelum ada peringkat
- Final Exam Big Data - 220721Dokumen3 halamanFinal Exam Big Data - 220721MUJIJATBelum ada peringkat
- 2112 Isys6523036 Thca TK1-W3-S4-R0 Team4Dokumen2 halaman2112 Isys6523036 Thca TK1-W3-S4-R0 Team4Muhamad NurfaiziBelum ada peringkat
- Mfloic K9 DZZ CG E3 T BL9 I VGHLJ 6 KP VIPRxjy WHqioDokumen16 halamanMfloic K9 DZZ CG E3 T BL9 I VGHLJ 6 KP VIPRxjy WHqioMuhammad Ibrahim WahyudiBelum ada peringkat
- Tugas Kelompok Ke-3 Week 8/ Sesi 12: Soal 1Dokumen1 halamanTugas Kelompok Ke-3 Week 8/ Sesi 12: Soal 1TsabitAlaykRidhollahBelum ada peringkat
- Tugas Personal Ke-1 Week 2/ Sesi 3: Soal 1Dokumen3 halamanTugas Personal Ke-1 Week 2/ Sesi 3: Soal 1TsabitAlaykRidhollah0% (1)
- Tugas Kelompok Ke-2 Week 4: COMP6725 - Big Data TechnologiesDokumen1 halamanTugas Kelompok Ke-2 Week 4: COMP6725 - Big Data TechnologiesTsabitAlaykRidhollahBelum ada peringkat
- HDFS & Map ReduceDokumen10 halamanHDFS & Map ReduceAriij Bangkit NaufalBelum ada peringkat
- Tools Untuk Arsitektur Hadoop: Dfs Dan HdfsDokumen4 halamanTools Untuk Arsitektur Hadoop: Dfs Dan HdfsMuhammad FathirBelum ada peringkat
- LN10-Big Data Case StudyDokumen36 halamanLN10-Big Data Case StudyTsabitAlaykRidhollahBelum ada peringkat
- COMP6725036 - Big Data Technologies-2401995924Dokumen5 halamanCOMP6725036 - Big Data Technologies-2401995924aditya rizqi pratamaBelum ada peringkat
- LN02-Big Data ArchitectureDokumen21 halamanLN02-Big Data ArchitectureTsabitAlaykRidhollahBelum ada peringkat
- Tugas Personal Ke-1 Week 2: Nama Fikran Ahmadi NIM 2401987701Dokumen4 halamanTugas Personal Ke-1 Week 2: Nama Fikran Ahmadi NIM 2401987701Fikran AhmadiBelum ada peringkat
- LN08-Big Data Analytics (Apache Spark & SparkML)Dokumen26 halamanLN08-Big Data Analytics (Apache Spark & SparkML)TsabitAlaykRidhollahBelum ada peringkat
- Tugas Kelompok Ke-2 Week 4Dokumen4 halamanTugas Kelompok Ke-2 Week 4ridwanBelum ada peringkat
- Layer Yg Menjelaskan Spesifikasi Dimana Aplikasi Jaringan Berkomunikasi Dengan Layanan Jaringan Merupakan Pengertian DariDokumen3 halamanLayer Yg Menjelaskan Spesifikasi Dimana Aplikasi Jaringan Berkomunikasi Dengan Layanan Jaringan Merupakan Pengertian DariAnonymous L1ePxsJmWBelum ada peringkat
- IPTraf and TCPdumpDokumen13 halamanIPTraf and TCPdumpDuney WardaniBelum ada peringkat
- Worksheets 3 - Big Data Analytics and TechnologiesDokumen3 halamanWorksheets 3 - Big Data Analytics and TechnologiesPutri Nur ainiBelum ada peringkat
- Tugas Uas Sistem Informasi Data Warehouse Dan Business Inteligence CompressDokumen45 halamanTugas Uas Sistem Informasi Data Warehouse Dan Business Inteligence Compress11220752 M Ainul YaqinBelum ada peringkat
- TP3 - Dian Rahmad DermawanDokumen6 halamanTP3 - Dian Rahmad DermawanDian RahmadBelum ada peringkat
- Panduan Penjadwalan Ujian ICAEWDokumen6 halamanPanduan Penjadwalan Ujian ICAEWOcym LaBelum ada peringkat
- Proposal Riset Teknologi InformasiDokumen12 halamanProposal Riset Teknologi InformasiWahyu Harimas Anstura100% (1)
- Penerapan Naive Bayes Untuk Klasifikasi Kelayakan Calo KaryawanDokumen21 halamanPenerapan Naive Bayes Untuk Klasifikasi Kelayakan Calo KaryawanErdo Waka SeptyanoBelum ada peringkat
- ListViewDokumen38 halamanListViewAlexander Onny100% (1)
- Desy Milbina BR Bangun - 187038064Dokumen15 halamanDesy Milbina BR Bangun - 187038064Indra SinagaBelum ada peringkat
- 3.20211012160932 - TP2 W7 S11 R0 - RevisionDokumen12 halaman3.20211012160932 - TP2 W7 S11 R0 - Revisionivan zuhriivanBelum ada peringkat
- SAP - Enterprise Resource PlanningDokumen8 halamanSAP - Enterprise Resource PlanningYuda Ba RyBelum ada peringkat
- Assignment: GroupDokumen2 halamanAssignment: Groupshofyan skyBelum ada peringkat
- Sistem PakarDokumen148 halamanSistem PakarWidhi Byl50% (2)
- Tugas Personal 4Dokumen3 halamanTugas Personal 4Rifqi FadhillaBelum ada peringkat
- Prediksi Harga Jual Emas Dengan Algoritma Linear Regresi SederhanaDokumen6 halamanPrediksi Harga Jual Emas Dengan Algoritma Linear Regresi SederhanaSatrio Yudho PangestuBelum ada peringkat
- 04 Penerapan Algoritma C4.5 Dalam Prediksi Penyewa SepedaDokumen4 halaman04 Penerapan Algoritma C4.5 Dalam Prediksi Penyewa SepedaAPMMI - Asosiasi Profesi Multimedia IndonesiaBelum ada peringkat
- Terjemahan Chapter 1 - 3Dokumen21 halamanTerjemahan Chapter 1 - 3Anonymous 8lOL5pCqzBelum ada peringkat
- Soal Ets Cloud Computing IjalDokumen7 halamanSoal Ets Cloud Computing IjalIjal FerdiBelum ada peringkat
- Laporan Akhir Magang (Nico Ardian Nugroho - 2201827780)Dokumen38 halamanLaporan Akhir Magang (Nico Ardian Nugroho - 2201827780)Nico Ardian NugrohoBelum ada peringkat
- MIBE COMP6725036 BigDataTechnologies-AnswerDokumen5 halamanMIBE COMP6725036 BigDataTechnologies-Answerchris marpaungBelum ada peringkat
- TP2 Dian Rahmad DermawanDokumen6 halamanTP2 Dian Rahmad DermawanDian RahmadBelum ada peringkat
- LN07-Big Data AnalyticsDokumen21 halamanLN07-Big Data AnalyticsTsabitAlaykRidhollahBelum ada peringkat
- ERP - Pertemuan 6Dokumen21 halamanERP - Pertemuan 6akusitohangBelum ada peringkat
- MHBE COMP6725036 BigDataTechnologies-QuestionDokumen10 halamanMHBE COMP6725036 BigDataTechnologies-Questionivan zuhriivanBelum ada peringkat
- Arsitektur Data WarehouseDokumen3 halamanArsitektur Data WarehouseKen DedesBelum ada peringkat
- Paper Kecerdasan BisnisDokumen8 halamanPaper Kecerdasan BisnisAndrian Ersa MaulanaBelum ada peringkat
- SPK Seleksi Karyawan UMHDokumen77 halamanSPK Seleksi Karyawan UMHsadarwibowo71Belum ada peringkat
- Sonya Legis - UTS Perancangan Basis Data - 3 BSDokumen6 halamanSonya Legis - UTS Perancangan Basis Data - 3 BSsonyaBelum ada peringkat
- Database ServerDokumen9 halamanDatabase ServerSintaKusumaWBelum ada peringkat
- RPS Pengantar Jaringan KomputerDokumen6 halamanRPS Pengantar Jaringan KomputerMuhammad JunaidiBelum ada peringkat
- Laporan User PersonaDokumen13 halamanLaporan User PersonaMarcello Rasel100% (1)
- 1922 Isys6299 Jcba TP2-W7-S11-R3Dokumen3 halaman1922 Isys6299 Jcba TP2-W7-S11-R3Annisa RachmadiyantiBelum ada peringkat
- Dbms and Web SecurityDokumen7 halamanDbms and Web SecurityDonay X SmallBelum ada peringkat
- Jawaban - TP1 W2 S3 R0Dokumen4 halamanJawaban - TP1 W2 S3 R0Paramita DaniswariBelum ada peringkat
- TOGAFDokumen18 halamanTOGAF1708kyungsooBelum ada peringkat
- Pengujian White Box TestingDokumen11 halamanPengujian White Box TestingRafi KadafiBelum ada peringkat
- Materi 4 Keamanan Komputer Keamanan Sistem OperasiDokumen32 halamanMateri 4 Keamanan Komputer Keamanan Sistem OperasiMukhlas UcasBelum ada peringkat
- Laporan PKL 201753057 Sistem Informasi Rekrutmen Karyawan Pada CV. Yuk Coding Media Berbasis WebsiteDokumen167 halamanLaporan PKL 201753057 Sistem Informasi Rekrutmen Karyawan Pada CV. Yuk Coding Media Berbasis WebsitezoeztaBelum ada peringkat
- Modul 13 OLAPDokumen15 halamanModul 13 OLAPAnisa Dwi DestyariBelum ada peringkat
- Jurnal CRMDokumen12 halamanJurnal CRMlailaBelum ada peringkat
- Tugas Kelompok 2 System Analysis and Design - Team 2Dokumen4 halamanTugas Kelompok 2 System Analysis and Design - Team 2Tutut A. CahyaniBelum ada peringkat
- Oracle Dan PL SQLDokumen80 halamanOracle Dan PL SQLRicky Reza Pahlevi100% (1)
- TP4-Dian Rahmad DermawanDokumen6 halamanTP4-Dian Rahmad DermawanDian RahmadBelum ada peringkat
- Makalah Data WarehouseDokumen16 halamanMakalah Data Warehouseintan maharaniBelum ada peringkat
- Big Data Storage Per 15Dokumen9 halamanBig Data Storage Per 15Erni AriyantiBelum ada peringkat
- Jobsheet ReplikasiPadaHadoopDokumen10 halamanJobsheet ReplikasiPadaHadoopLulu Yulianti PangestuBelum ada peringkat
- MAYANGDokumen8 halamanMAYANGwilda sembiringBelum ada peringkat
- Ln6-Ifa 1Dokumen10 halamanLn6-Ifa 1TsabitAlaykRidhollahBelum ada peringkat
- Ln9-Ifa 1Dokumen12 halamanLn9-Ifa 1TsabitAlaykRidhollahBelum ada peringkat
- LN07-Big Data AnalyticsDokumen21 halamanLN07-Big Data AnalyticsTsabitAlaykRidhollahBelum ada peringkat
- LN08-Big Data Analytics (Apache Spark & SparkML)Dokumen26 halamanLN08-Big Data Analytics (Apache Spark & SparkML)TsabitAlaykRidhollahBelum ada peringkat