Anda mungkin juga menyukai
- Teori KetidakpastianDokumen26 halamanTeori Ketidakpastianjijay110694Belum ada peringkat
- Contoh Perhitungan C4.5Dokumen7 halamanContoh Perhitungan C4.5Yana TriBelum ada peringkat
- Tugas 1 - C4.5 - Zulfahmi Ramadhani PDFDokumen7 halamanTugas 1 - C4.5 - Zulfahmi Ramadhani PDFAllen BakerBelum ada peringkat
- Data Mining-III 2019-1Dokumen33 halamanData Mining-III 2019-1Parman Dogless TangerangBelum ada peringkat
- Decision TreeDokumen5 halamanDecision TreeNur ImansyahBelum ada peringkat
- Tugas 4 Data MiningDokumen36 halamanTugas 4 Data MiningGufran Ghozian RizkyBelum ada peringkat
- Algoritma C4.5 - Nor Hafiz - TI 6B PDFDokumen15 halamanAlgoritma C4.5 - Nor Hafiz - TI 6B PDFnur hafizBelum ada peringkat
- Pertemuan 7 Part 2Dokumen51 halamanPertemuan 7 Part 2Fransisca NataliaBelum ada peringkat
- Algoritma ID3Dokumen18 halamanAlgoritma ID3Yoshua BryantBelum ada peringkat
- Algoritma C.45Dokumen41 halamanAlgoritma C.45Farhan AuliaBelum ada peringkat
- ALGORITMA C4.5 (Chek Again Dude)Dokumen21 halamanALGORITMA C4.5 (Chek Again Dude)arisnurba100% (1)
- Laporan Pola Decision TreeDokumen13 halamanLaporan Pola Decision TreeTacha100% (1)
- DATA MINING Materi 2Dokumen6 halamanDATA MINING Materi 2FlamboyanBelum ada peringkat
- JWGP Intro To ML Chap6 SecuredDokumen8 halamanJWGP Intro To ML Chap6 SecuredAl HaisBelum ada peringkat
- Belajar Pohon Keputusan ID3Dokumen39 halamanBelajar Pohon Keputusan ID3Allvy Noer67% (3)
- Klasifikasi. Data MiningDokumen67 halamanKlasifikasi. Data MiningAwi 29Belum ada peringkat
- Tugas Mandiri 2Dokumen8 halamanTugas Mandiri 22113034 TANRI ABENGBelum ada peringkat
- Algoritma ID3Dokumen21 halamanAlgoritma ID3bayuBelum ada peringkat
- Hincasting WordDokumen2 halamanHincasting WordWaskito DwiwicaksoputroBelum ada peringkat
- 02 - Decision TreeDokumen39 halaman02 - Decision TreeAvin Unggul Wijaya XI-MIPA-2Belum ada peringkat
- Tugas 2. Data MiningDokumen31 halamanTugas 2. Data MiningsuryawinantaraBelum ada peringkat
- Amelia Winursetia - 3KA25 - 17119138 - TugasM7 - DataMiningDokumen5 halamanAmelia Winursetia - 3KA25 - 17119138 - TugasM7 - DataMiningAmelia WinursetiaBelum ada peringkat
- Nama: Afifah Kurnia Lestari NPM: 2013030050 Prodi: SI/3BDokumen12 halamanNama: Afifah Kurnia Lestari NPM: 2013030050 Prodi: SI/3BDestria Septy Dara FpgBelum ada peringkat
- Soal Ujian Matematika Kelas 11Dokumen2 halamanSoal Ujian Matematika Kelas 11sherinda syafa ardhanaBelum ada peringkat
- Agoritma c4.5Dokumen21 halamanAgoritma c4.5habibBelum ada peringkat
- Rumus Perhitungan Curah HujanDokumen6 halamanRumus Perhitungan Curah Hujanmuhardijaya100% (2)
- Tugas 3 - Muhammad Latif Makarim - 04311940000023Dokumen5 halamanTugas 3 - Muhammad Latif Makarim - 04311940000023Muhammad AlthafBelum ada peringkat
- DM BI 03 PeranDataMiningDokumen38 halamanDM BI 03 PeranDataMiningMaulana Yusuf AhmadBelum ada peringkat
- LA - ANP5 - Rutherford Scattering - Ahmad Basyir NajwanDokumen8 halamanLA - ANP5 - Rutherford Scattering - Ahmad Basyir NajwanFisika dalam Kehidupan Olimpiade FisikaBelum ada peringkat
- Laporan 13Dokumen3 halamanLaporan 13Julius GunawanBelum ada peringkat
- Menera Termometer (Firgin) - 1Dokumen15 halamanMenera Termometer (Firgin) - 1ridho blustakBelum ada peringkat
- Tugas Algoritma ID3Dokumen16 halamanTugas Algoritma ID3Riyan SanjayaBelum ada peringkat
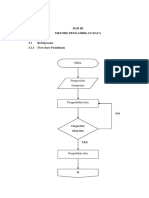
- BAB III - Dendi Fitra - AccDokumen27 halamanBAB III - Dendi Fitra - AccRendyBelum ada peringkat
- Pengertian MeanDokumen8 halamanPengertian MeanAbdul Haarys Al-kahtaniBelum ada peringkat
- Mesin PembelajaranDokumen21 halamanMesin Pembelajaranapi-19773958Belum ada peringkat
- Kalkulus Integral Lipat Kelompok 3Dokumen19 halamanKalkulus Integral Lipat Kelompok 3luhagustyaniBelum ada peringkat
- 6-Naive Bayes (Klasifikasi)Dokumen23 halaman6-Naive Bayes (Klasifikasi)sabrina waelBelum ada peringkat
- C12200042 - Yutaka - UTS SKEDokumen8 halamanC12200042 - Yutaka - UTS SKEIVAN CHRISTIANBelum ada peringkat
- Aqshal Nur Ikhsan - Tugas Teknologi Lapisan TipisDokumen4 halamanAqshal Nur Ikhsan - Tugas Teknologi Lapisan TipisAqshal Nur IkhsanBelum ada peringkat
- Laporan 12Dokumen4 halamanLaporan 12Julius GunawanBelum ada peringkat
- Laporan 1Dokumen4 halamanLaporan 1Julius GunawanBelum ada peringkat
- Laprak IDokumen17 halamanLaprak INophya Angela PurbaBelum ada peringkat
- Kunci - Fisika - SMA - TO UN 2Dokumen34 halamanKunci - Fisika - SMA - TO UN 2Firman Satria SasmitaBelum ada peringkat
- 11 MomenDokumen4 halaman11 MomenAnnaBelum ada peringkat
- 3.7 Pengecekan Ketidakberaturan TorsiDokumen3 halaman3.7 Pengecekan Ketidakberaturan TorsiEKABelum ada peringkat
- Soal Aliran Berubah Beraturan Lambat Kasus TrapezoidalDokumen4 halamanSoal Aliran Berubah Beraturan Lambat Kasus TrapezoidalAw WaBelum ada peringkat
- L3 LJKDokumen5 halamanL3 LJKSenandung LembayungBelum ada peringkat
- Achmad Fahri 1210701002 UTS Data MiningDokumen23 halamanAchmad Fahri 1210701002 UTS Data MiningAchmad FahriBelum ada peringkat
- Ukuran Pemusatan DataDokumen12 halamanUkuran Pemusatan Datalaili azizahBelum ada peringkat
- Uji ZDokumen16 halamanUji ZSebastian HavisBelum ada peringkat
- Merge SortDokumen13 halamanMerge SortAsma Una PacifistaBelum ada peringkat
- Laporan KTDokumen14 halamanLaporan KTWenney Samuel BoenBelum ada peringkat
- REKTIFIKASIDokumen15 halamanREKTIFIKASIVania ParamithaBelum ada peringkat
- TM-3144-Persamaan Non Linear (2) #3Dokumen20 halamanTM-3144-Persamaan Non Linear (2) #3dhany hambaliBelum ada peringkat
- Tugas 1 Perpindahan Panas II - Kelompok 2Dokumen4 halamanTugas 1 Perpindahan Panas II - Kelompok 2Aldian G RahmanBelum ada peringkat
- Laporan Resmi Praktikum Ayunan MatematisDokumen58 halamanLaporan Resmi Praktikum Ayunan MatematisMutiara Elok SilvanaBelum ada peringkat
- Metode Klasifikasi Algoritma.C45: Pertemuan Ke-6 (SI-RM53) 10-12-2020Dokumen28 halamanMetode Klasifikasi Algoritma.C45: Pertemuan Ke-6 (SI-RM53) 10-12-2020medy manzoomBelum ada peringkat
- Proposal Re - 6 Juli 2022 (Okk)Dokumen31 halamanProposal Re - 6 Juli 2022 (Okk)MADANI PELITA TVBelum ada peringkat
- Daftar Nilai Xi RPL PPLDokumen60 halamanDaftar Nilai Xi RPL PPLMADANI PELITA TVBelum ada peringkat
- Multiclass ClassificationDokumen2 halamanMulticlass ClassificationMADANI PELITA TVBelum ada peringkat
- Daftar Nilai Xi MM 2 AnimasiDokumen60 halamanDaftar Nilai Xi MM 2 AnimasiMADANI PELITA TVBelum ada peringkat
- Tugas Kewirausahaan Pilgan Kelas 2Dokumen3 halamanTugas Kewirausahaan Pilgan Kelas 2MADANI PELITA TVBelum ada peringkat
- CONTOH - PROPOSAL - 17 - AGUSTUS 2020tanjung MuliaDokumen4 halamanCONTOH - PROPOSAL - 17 - AGUSTUS 2020tanjung MuliaMADANI PELITA TVBelum ada peringkat
- Tugas Perceptron Dan Back Propogation Desi - IrfanDokumen12 halamanTugas Perceptron Dan Back Propogation Desi - IrfanMADANI PELITA TVBelum ada peringkat
- KB S 2 Ilkom 1 - Jaka Tirta SamudraDokumen3 halamanKB S 2 Ilkom 1 - Jaka Tirta SamudraMADANI PELITA TVBelum ada peringkat
- SUSUNAN ACARA SIMANTAP 2021 FixDokumen3 halamanSUSUNAN ACARA SIMANTAP 2021 FixMADANI PELITA TVBelum ada peringkat
- Ramadani - 2117000025 - Tugas Review Jurnal Algoritma K-MeansDokumen7 halamanRamadani - 2117000025 - Tugas Review Jurnal Algoritma K-MeansMADANI PELITA TVBelum ada peringkat
- Review Makalah - Pengenalan Pola LVQDokumen9 halamanReview Makalah - Pengenalan Pola LVQMADANI PELITA TVBelum ada peringkat