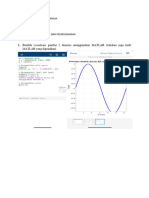
Anda mungkin juga menyukai
- Pemrograman Berorientasi Objek dengan Visual C#Dari EverandPemrograman Berorientasi Objek dengan Visual C#Penilaian: 3.5 dari 5 bintang3.5/5 (6)
- Arima EviewsDokumen20 halamanArima EviewsWidodo PurwantoBelum ada peringkat
- Tutorial PowersimDokumen11 halamanTutorial PowersimYayan Surohman100% (2)
- Black Box Testing Dan Contoh Pengujian Black BoxDokumen10 halamanBlack Box Testing Dan Contoh Pengujian Black Boxthommy_adiBelum ada peringkat
- Fadhlur Rahman Aulia Abdullah - IT-45-02 - SISCERDokumen24 halamanFadhlur Rahman Aulia Abdullah - IT-45-02 - SISCERRoberto SunjayaBelum ada peringkat
- Klasifikasi in Spark (Regresi Logistik)Dokumen5 halamanKlasifikasi in Spark (Regresi Logistik)falahrohmawanBelum ada peringkat
- Regresi in SparkDokumen4 halamanRegresi in SparkfalahrohmawanBelum ada peringkat
- Bahiyah Keiko R - 21218343 - 4EB01 (LAM2)Dokumen7 halamanBahiyah Keiko R - 21218343 - 4EB01 (LAM2)Bahiyah KeikoBelum ada peringkat
- Sagita Amaria ChristieDokumen5 halamanSagita Amaria ChristieYulianti RepatiBelum ada peringkat
- Logistic RegressionDokumen3 halamanLogistic RegressionTheresia Dimpu HutasoitBelum ada peringkat
- Machine Learning Dengan Menggunakan Bahasa PythonDokumen11 halamanMachine Learning Dengan Menggunakan Bahasa Pythondea.andini.andriatiBelum ada peringkat
- Backward EstimationDokumen24 halamanBackward Estimationalimulyanto psubBelum ada peringkat
- Kamila Khairunisa - 23319216 - Tugas PraktikumDokumen6 halamanKamila Khairunisa - 23319216 - Tugas Praktikumvgcmgh gtBelum ada peringkat
- Citra Maulida Permata Mauni - 10220366 - 4EA07 - LA (M3)Dokumen13 halamanCitra Maulida Permata Mauni - 10220366 - 4EA07 - LA (M3)Citra MaulidaBelum ada peringkat
- Laporan 4 - Hafidzurrohman Saifullah (10120486) - 4ka04 - Laporan Praktikum Robotika Cerdas M4Dokumen13 halamanLaporan 4 - Hafidzurrohman Saifullah (10120486) - 4ka04 - Laporan Praktikum Robotika Cerdas M4f.empat444Belum ada peringkat
- Bab 4 Analisa Hasil Dan PembahasanDokumen19 halamanBab 4 Analisa Hasil Dan PembahasanDaniel ErgawantoBelum ada peringkat
- Materi PKBDokumen17 halamanMateri PKBStefanus Dapa LokaBelum ada peringkat
- Bahiyah Keiko R - 21218343 - 4EB01 (LAM3)Dokumen10 halamanBahiyah Keiko R - 21218343 - 4EB01 (LAM3)Bahiyah KeikoBelum ada peringkat
- Hasil Dan PembahasanDokumen13 halamanHasil Dan PembahasanDaniel ErgawantoBelum ada peringkat
- Neural Network Time-Series Prediction and Modeling - MATLAB & SimulinkDokumen19 halamanNeural Network Time-Series Prediction and Modeling - MATLAB & SimulinkFeby Tri NBelum ada peringkat
- Modul 6Dokumen6 halamanModul 6Victor Imannuel KartikaBelum ada peringkat
- Mutiara Damayanti - UTS MLDokumen8 halamanMutiara Damayanti - UTS MLmutiaradamayanti41Belum ada peringkat
- Kode Program Ini Adalah Sebuah Fungsi Python Yang Disusun Untuk Memeriksa Apakah Simbol Saham Yang Dimasukkan Oleh Pengguna Terdapat Dalam File CSV Yang DisediakanDokumen8 halamanKode Program Ini Adalah Sebuah Fungsi Python Yang Disusun Untuk Memeriksa Apakah Simbol Saham Yang Dimasukkan Oleh Pengguna Terdapat Dalam File CSV Yang DisediakanIndhiro Elsaday Nainggolan 28Belum ada peringkat
- Eksplorasi ANN Dan Mini-Batch Gradient Descent Dengan Menggunakan KerasDokumen4 halamanEksplorasi ANN Dan Mini-Batch Gradient Descent Dengan Menggunakan KerasAndreas HalimBelum ada peringkat
- Soal Soal PTS Pemdas Kelas 10 Semester 1Dokumen8 halamanSoal Soal PTS Pemdas Kelas 10 Semester 1Davidson RafaelBelum ada peringkat
- Task10 - Bagus Arimanu - Ipynb - ColaboratoryDokumen6 halamanTask10 - Bagus Arimanu - Ipynb - Colaboratorybagus arimanuBelum ada peringkat
- Combinational Logic SequenceDokumen9 halamanCombinational Logic SequenceYogi Salomo Mangontang PratamaBelum ada peringkat
- Bahiyah Keiko R - 21218343 - 4EB01 (LAM4)Dokumen6 halamanBahiyah Keiko R - 21218343 - 4EB01 (LAM4)Bahiyah KeikoBelum ada peringkat
- TUGAS KELOMPOK CODING-dikonversiDokumen16 halamanTUGAS KELOMPOK CODING-dikonversiDita Aulia BudiarthaBelum ada peringkat
- MPMLDokumen33 halamanMPMLVIKA RANI -Belum ada peringkat
- Manual Book - Tiara Fatehana AuliaDokumen31 halamanManual Book - Tiara Fatehana AuliaDian WidyaBelum ada peringkat
- Definisi2 Dalam ADPDokumen9 halamanDefinisi2 Dalam ADPHalfuniBelum ada peringkat
- UntitledDokumen11 halamanUntitledTidak PentingBelum ada peringkat
- Darren Mazinzan - 10120285 - 4KA13 - M6Dokumen11 halamanDarren Mazinzan - 10120285 - 4KA13 - M6mazinzan rusmantoBelum ada peringkat
- Praktikum Sistem KendaliDokumen16 halamanPraktikum Sistem KendaliBalaputradewa 002Belum ada peringkat
- Kelompok 4 Machine LearningDokumen14 halamanKelompok 4 Machine LearningsudirmanBelum ada peringkat
- Hands On 5 FYSDokumen23 halamanHands On 5 FYSqwertyBelum ada peringkat
- Pengenalan Program MatlabDokumen10 halamanPengenalan Program MatlabViaren MichaelBelum ada peringkat
- UAS - Sistem Cerdas - Aditri Seftian - 41417320065Dokumen26 halamanUAS - Sistem Cerdas - Aditri Seftian - 41417320065Aditri SeftianBelum ada peringkat
- Laporan Summary Modul 5Dokumen17 halamanLaporan Summary Modul 5DIMAS RIZAL SURYA SETIAWANBelum ada peringkat
- Cara Membuat Kalkulator Java Di Netbeans - SMK BINA KERJADokumen10 halamanCara Membuat Kalkulator Java Di Netbeans - SMK BINA KERJAIkaBelum ada peringkat
- Laporan Neural NetworkDokumen6 halamanLaporan Neural NetworkMuhammad Dzikrullah SBelum ada peringkat
- Sistem Cerdas (SVM Classifier)Dokumen13 halamanSistem Cerdas (SVM Classifier)Riska Candra DewiBelum ada peringkat
- Memahami Dampak Dari Memvariasikan Loss OptimizerDokumen11 halamanMemahami Dampak Dari Memvariasikan Loss Optimizerkhodimul istiqlalBelum ada peringkat
- Scaling A Dataset To Improve Model Accuracy IdDokumen13 halamanScaling A Dataset To Improve Model Accuracy Idkhodimul istiqlalBelum ada peringkat
- Yoga Swista Mochtar - 4EA04 - 11220729 - Praktikum Kecerdasan Artifisial Dan Masyarakat - Tugas M-4Dokumen13 halamanYoga Swista Mochtar - 4EA04 - 11220729 - Praktikum Kecerdasan Artifisial Dan Masyarakat - Tugas M-4bilaBelum ada peringkat
- Algoritma Dan Pemrograman-Pertemuan 6Dokumen11 halamanAlgoritma Dan Pemrograman-Pertemuan 6فردوس سليمانBelum ada peringkat
- DWDM-7 D L200180193-DikonversiDokumen11 halamanDWDM-7 D L200180193-DikonversiRizki HanifBelum ada peringkat
- 6.3. Pelajaran: Analisis Jaringanÿ: Ikuti Bersama: Alat Dan Dataÿ 6.3.1Dokumen14 halaman6.3. Pelajaran: Analisis Jaringanÿ: Ikuti Bersama: Alat Dan Dataÿ 6.3.1Nanda MahaBelum ada peringkat
- MODUL 3 Regresi LinierDokumen7 halamanMODUL 3 Regresi LinierMuhamad Zidan HusainiBelum ada peringkat
- Novani Jumisa - 18065018 - Exp6Dokumen31 halamanNovani Jumisa - 18065018 - Exp6Novani JumisaBelum ada peringkat
- Uas AnalisisDokumen3 halamanUas Analisisnurrohmat61Belum ada peringkat
- 1.mengimplementasikan Pemrograman TerstrukturDokumen9 halaman1.mengimplementasikan Pemrograman Terstruktursilvimaulidia627Belum ada peringkat
- FuzzyDgnMatlab TutorialDokumen10 halamanFuzzyDgnMatlab Tutorial1r4oneBelum ada peringkat
- Machine Learning Using R ProgrammingDokumen6 halamanMachine Learning Using R ProgrammingBayu Ade KrisnaBelum ada peringkat
- BAB 1 - Pengenalan Simulink Dan Matlab SIKON PDFDokumen7 halamanBAB 1 - Pengenalan Simulink Dan Matlab SIKON PDFNurhakim SunandaBelum ada peringkat
- Tanagra Dan c45Dokumen16 halamanTanagra Dan c45Jonni Adi PutraBelum ada peringkat
- Machine Learning With Python For BeginnerDokumen64 halamanMachine Learning With Python For BeginnereugeneBelum ada peringkat
- Plotting Pada MatlabDokumen45 halamanPlotting Pada MatlabYujinn Janngka100% (7)
- Tugas Nb-Playtennis DataMiningDokumen9 halamanTugas Nb-Playtennis DataMiningsudirmanBelum ada peringkat
- Validitas Dan Reliabilitas InstrumenDokumen18 halamanValiditas Dan Reliabilitas InstrumenRiska Candra DewiBelum ada peringkat
- Psikologi Pendidikan Sebagai Dasar PembelajaranDokumen18 halamanPsikologi Pendidikan Sebagai Dasar PembelajaranRiska Candra DewiBelum ada peringkat
- Draft Rancangan Kegiatan Studio PodcastDokumen4 halamanDraft Rancangan Kegiatan Studio PodcastRiska Candra DewiBelum ada peringkat
- 4 Dunia UsahaDokumen25 halaman4 Dunia UsahaRiska Candra DewiBelum ada peringkat
- Format BunyiDokumen9 halamanFormat BunyiRiska Candra DewiBelum ada peringkat
- Materi Organisasi Dan Arsitektur KomputerDokumen11 halamanMateri Organisasi Dan Arsitektur KomputerRiska Candra DewiBelum ada peringkat
- 3a KAK-TORDokumen6 halaman3a KAK-TORRiska Candra DewiBelum ada peringkat
- Kisi2 Us Pai 2021Dokumen6 halamanKisi2 Us Pai 2021Riska Candra DewiBelum ada peringkat
- Sistem Cerdas (SVM Classifier)Dokumen13 halamanSistem Cerdas (SVM Classifier)Riska Candra DewiBelum ada peringkat
- CoverDokumen15 halamanCoverRiska Candra DewiBelum ada peringkat
- Soal Mid MptiDokumen2 halamanSoal Mid MptiRiska Candra DewiBelum ada peringkat
- Hipotesis PenelitianDokumen15 halamanHipotesis PenelitianRiska Candra DewiBelum ada peringkat