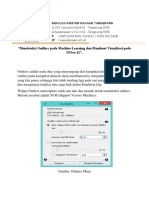
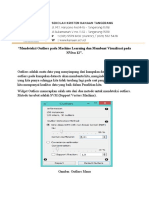
Anda mungkin juga menyukai
- Pemrograman Berorientasi Objek dengan Visual C#Dari EverandPemrograman Berorientasi Objek dengan Visual C#Penilaian: 3.5 dari 5 bintang3.5/5 (6)
- KeselamatanDokumen41 halamanKeselamatanqwertyBelum ada peringkat
- Sistem Cerdas (SVM Classifier)Dokumen13 halamanSistem Cerdas (SVM Classifier)Riska Candra DewiBelum ada peringkat
- ML-SVMDokumen10 halamanML-SVMdanielBelum ada peringkat
- SVM untuk Klasifikasi DataDokumen11 halamanSVM untuk Klasifikasi DataAbdul RahmanBelum ada peringkat
- Algoritma Klasifikasi IrisDokumen9 halamanAlgoritma Klasifikasi IrisAbdul Hadi EfendiBelum ada peringkat
- Modul Praktikum Machine Learning - SVMDokumen6 halamanModul Praktikum Machine Learning - SVMIwanBelum ada peringkat
- SVM PENDETEKSIANDokumen28 halamanSVM PENDETEKSIANShel Vina50% (2)
- Menghitung Hyperplane pada SVMDokumen4 halamanMenghitung Hyperplane pada SVMRian BudimanBelum ada peringkat
- SVM-Praktikum6Dokumen6 halamanSVM-Praktikum6Victor Imannuel KartikaBelum ada peringkat
- OPTIMIZED_SVM_TITLEDokumen8 halamanOPTIMIZED_SVM_TITLEImeldaAbdulmuisBelum ada peringkat
- 2301899_M Arya Anggara Gustiana_RPL 2B (1)Dokumen10 halaman2301899_M Arya Anggara Gustiana_RPL 2B (1)riskiytta.1Belum ada peringkat
- Kuliah KPM210522Dokumen81 halamanKuliah KPM210522abednego wicaksonoBelum ada peringkat
- Pemrograman GrafikDokumen47 halamanPemrograman GrafikWinda YanuartiBelum ada peringkat
- 2301899_M Arya Anggara Gustiana_RPL 2B (1) (1)Dokumen11 halaman2301899_M Arya Anggara Gustiana_RPL 2B (1) (1)riskiytta.1Belum ada peringkat
- Mendukung mesin vektor untuk deteksi serangan DDoS lapisan aplikasiDokumen6 halamanMendukung mesin vektor untuk deteksi serangan DDoS lapisan aplikasiEdi SuwandiBelum ada peringkat
- Matlab 1 HariDokumen58 halamanMatlab 1 HariWulandari Tri Maharani100% (1)
- Makalah SVM Ra Toyyibatul F 070411100132Dokumen21 halamanMakalah SVM Ra Toyyibatul F 070411100132Guestov LeoBelum ada peringkat
- OPERASI MATRIKS (Tugas Praktikum)Dokumen9 halamanOPERASI MATRIKS (Tugas Praktikum)Nadya KhairunnisaBelum ada peringkat
- Tutorial SCILABDokumen7 halamanTutorial SCILABArya KumaraBelum ada peringkat
- Laporan Praktikum Iii Metode Statistika Zeti Zarlina - 60600123033Dokumen10 halamanLaporan Praktikum Iii Metode Statistika Zeti Zarlina - 60600123033Xo.xoBelum ada peringkat
- SVM Nonlinier: Similarity Features dan Kernel Gaussian RBFDokumen18 halamanSVM Nonlinier: Similarity Features dan Kernel Gaussian RBFqwertyBelum ada peringkat
- Darren Mazinzan - 10120285 - 4KA13 - M2Dokumen10 halamanDarren Mazinzan - 10120285 - 4KA13 - M2mazinzan rusmantoBelum ada peringkat
- Algoritma K MeansDokumen16 halamanAlgoritma K MeansGandhix BhamakertiBelum ada peringkat
- Support Vector MachineDokumen15 halamanSupport Vector MachineJojor yeanesy SinagaBelum ada peringkat
- Plotting Pada MatlabDokumen45 halamanPlotting Pada MatlabYujinn Janngka100% (7)
- Laprak Metnum Pencocokan KurvaDokumen11 halamanLaprak Metnum Pencocokan KurvaFalenciana ChristieBelum ada peringkat
- Pengolahan Sinyal Digital 1Dokumen15 halamanPengolahan Sinyal Digital 1Muhamad TaufikBelum ada peringkat
- Algoritma GarisDokumen2 halamanAlgoritma GarisWulan CeceBelum ada peringkat
- Eksplorasi ANN Dan Mini-Batch Gradient Descent Dengan Menggunakan KerasDokumen4 halamanEksplorasi ANN Dan Mini-Batch Gradient Descent Dengan Menggunakan KerasAndreas HalimBelum ada peringkat
- BAB IV Hasil AnalisisDokumen9 halamanBAB IV Hasil AnalisisHeny DwiBelum ada peringkat
- Deteksi Outliers Dan Visualisasi Chart Pada NVivoDokumen5 halamanDeteksi Outliers Dan Visualisasi Chart Pada NVivowilliam yohanesBelum ada peringkat
- Deteksi Outliers Dan Visualisasi Chart Pada NVivoDokumen5 halamanDeteksi Outliers Dan Visualisasi Chart Pada NVivowilliam yohanesBelum ada peringkat
- Curve FittingDokumen15 halamanCurve Fittingrantiana27Belum ada peringkat
- 2986 6086 1 SMDokumen10 halaman2986 6086 1 SMapandansari2005Belum ada peringkat
- 03 Codelab Dan RegresiDokumen15 halaman03 Codelab Dan RegresiWilliam OktafianBelum ada peringkat
- Berny Pebo Tomasouw-Berny Pebo Tomasouw Makalah LengkapDokumen10 halamanBerny Pebo Tomasouw-Berny Pebo Tomasouw Makalah LengkapImeldaAbdulmuisBelum ada peringkat
- Bab 19Dokumen7 halamanBab 19Syifa Rifda SayyidahBelum ada peringkat
- Modul 2 - Vektor Dan Komputasi VektorDokumen11 halamanModul 2 - Vektor Dan Komputasi VektorZhie Yozai Khenza ZnadBelum ada peringkat
- Laporan Praktikum Komputasi ProsesDokumen15 halamanLaporan Praktikum Komputasi ProsesInternational KpopersBelum ada peringkat
- Modul 3 - SSD - Regresi LogistikDokumen23 halamanModul 3 - SSD - Regresi Logistik01NATASYA EGA LINA MARBUNBelum ada peringkat
- Eliminasi GaussDokumen13 halamanEliminasi GaussIkhsan AriansyahBelum ada peringkat
- 203 208 Snsi07 036 Klasifikasi Citra Dengan Support Vector Machine Pada Sistem Temu Kembali CitraDokumen6 halaman203 208 Snsi07 036 Klasifikasi Citra Dengan Support Vector Machine Pada Sistem Temu Kembali CitraArry AgustianiBelum ada peringkat
- LN 5-Buss Intel AnalyticDokumen12 halamanLN 5-Buss Intel AnalyticWahyu wardhanaBelum ada peringkat
- MMD2203 GrafikaKomputerDokumen45 halamanMMD2203 GrafikaKomputerHany RomantiningsihBelum ada peringkat
- Tutorial Vox LerDokumen7 halamanTutorial Vox LerFajar SukmayaBelum ada peringkat
- ANALISIS DAN VISUALISASI DATA CUACA DENGAN RDokumen16 halamanANALISIS DAN VISUALISASI DATA CUACA DENGAN RRahmad Auliya Tri PutraBelum ada peringkat
- MATRIKS-TEKNIK-KIMIADokumen24 halamanMATRIKS-TEKNIK-KIMIAikhwanul musliminBelum ada peringkat
- Pemodelan SemDokumen13 halamanPemodelan SemIndra DiputraBelum ada peringkat
- Modul Praktikum SQA Pages 10 16Dokumen7 halamanModul Praktikum SQA Pages 10 16Novendra DotIDBelum ada peringkat
- Matlab Dasar Untuk Matriks & Transformasi LinearDokumen23 halamanMatlab Dasar Untuk Matriks & Transformasi LinearErrissyaRasywir0% (3)
- Penerapan Algoritma DDA Dan Bresenham Dalam Bahasa Pemrograman JavaDokumen13 halamanPenerapan Algoritma DDA Dan Bresenham Dalam Bahasa Pemrograman JavaAprilia Zahrotul LutfiahBelum ada peringkat
- Lintang Puspita - Responsi Komstat BDokumen9 halamanLintang Puspita - Responsi Komstat BlintangBelum ada peringkat
- Amin Padmo Azam Masa, S.kom., M.cs. Pertemuan 6Dokumen4 halamanAmin Padmo Azam Masa, S.kom., M.cs. Pertemuan 6Afrizaldi AsrofiBelum ada peringkat
- DOKUMENDokumen50 halamanDOKUMENAsmawatifitrye Junaidi SorengganaBelum ada peringkat
- LPR - Week 8 - PandasDokumen64 halamanLPR - Week 8 - PandasRama DhaniBelum ada peringkat
- Eliminasi GaussDokumen7 halamanEliminasi GaussEiva RantikaBelum ada peringkat
- Review Jurnal Kelompok 7Dokumen6 halamanReview Jurnal Kelompok 7HusairiBelum ada peringkat
- Chapter0 VeryBasicDokumen27 halamanChapter0 VeryBasicqwertyBelum ada peringkat
- PLTPB PPTDokumen22 halamanPLTPB PPTqwertyBelum ada peringkat
- EKSPLOITASI GEOTERMALDokumen22 halamanEKSPLOITASI GEOTERMALqwertyBelum ada peringkat
- Modul Pembelajaran Pembangkit Tenaga Listrik - Upload PDFDokumen164 halamanModul Pembelajaran Pembangkit Tenaga Listrik - Upload PDFGideon SetiawanBelum ada peringkat
- Pertemuan 1 Intro FYSDokumen8 halamanPertemuan 1 Intro FYSqwertyBelum ada peringkat
- Kajian Potensi Tenaga Gelombang Laut Sebagai Pembangkit Tenaga Listrikdi Perairan Malang SelatanDokumen9 halamanKajian Potensi Tenaga Gelombang Laut Sebagai Pembangkit Tenaga Listrikdi Perairan Malang SelatanAlfinThariqBelum ada peringkat
- Tugas PencuplikanDokumen1 halamanTugas PencuplikanqwertyBelum ada peringkat
- Chapter0 Numpy FYSDokumen47 halamanChapter0 Numpy FYSqwertyBelum ada peringkat
- UU 30 Tahun 2007 Tentang EnergiDokumen27 halamanUU 30 Tahun 2007 Tentang EnergiEd FirdausBelum ada peringkat
- Tugas PencuplikanDokumen1 halamanTugas PencuplikanqwertyBelum ada peringkat
- GelombangLautDokumen9 halamanGelombangLautqwertyBelum ada peringkat
- Topic 10 Unsupervised Learning DBSCAN Dan Gaussian Mixtures-FYSDokumen16 halamanTopic 10 Unsupervised Learning DBSCAN Dan Gaussian Mixtures-FYSqwertyBelum ada peringkat
- sm6271 tp4 SitiRahmaU Jurnalp PDFDokumen7 halamansm6271 tp4 SitiRahmaU Jurnalp PDFSyarifah NuzulBelum ada peringkat
- Pembangkit Listrik Tenaga Gelombang Laut (Ombak)Dokumen23 halamanPembangkit Listrik Tenaga Gelombang Laut (Ombak)Nurul Azizah ZalmiBelum ada peringkat
- Pembangkit Listrik Tenaga Gelombang LautDokumen19 halamanPembangkit Listrik Tenaga Gelombang LautqwertyBelum ada peringkat
- PLTGL Energi Potensial Pada Gelombang AirDokumen10 halamanPLTGL Energi Potensial Pada Gelombang AirArief NurBelum ada peringkat
- 656 1676 1 PBDokumen8 halaman656 1676 1 PBrizky kurniawanBelum ada peringkat
- Hands On 6 FYSDokumen48 halamanHands On 6 FYSqwertyBelum ada peringkat
- Hands On 6 FYSDokumen48 halamanHands On 6 FYSqwertyBelum ada peringkat
- EKSPLOITASI GEOTERMALDokumen22 halamanEKSPLOITASI GEOTERMALqwertyBelum ada peringkat
- SVM Nonlinier: Similarity Features dan Kernel Gaussian RBFDokumen18 halamanSVM Nonlinier: Similarity Features dan Kernel Gaussian RBFqwertyBelum ada peringkat
- Topic 9 Unsupervised Learning - FYSDokumen20 halamanTopic 9 Unsupervised Learning - FYSqwertyBelum ada peringkat
- Isi Artikel 299496757397Dokumen9 halamanIsi Artikel 299496757397Nyi IteungBelum ada peringkat
- Topic 10 Unsupervised Learning DBSCAN Dan Gaussian Mixtures-FYSDokumen16 halamanTopic 10 Unsupervised Learning DBSCAN Dan Gaussian Mixtures-FYSqwertyBelum ada peringkat
- ManusiaDokumen27 halamanManusiaqwertyBelum ada peringkat
- DosaDokumen23 halamanDosaqwertyBelum ada peringkat
- PeluangStatistikaDokumen37 halamanPeluangStatistikaqwertyBelum ada peringkat
- Modul 4 REGDokumen10 halamanModul 4 REGqwertyBelum ada peringkat