Anda mungkin juga menyukai
- Vsen22.Kp SeptemberDokumen44 halamanVsen22.Kp SeptemberFaruq LQomariyahBelum ada peringkat
- Metode PercobaanDokumen3 halamanMetode PercobaanLusiana OliviaBelum ada peringkat
- 13.3-13.4 + Latihan Soal StatmatDokumen7 halaman13.3-13.4 + Latihan Soal StatmatAZZAHRA SHINTA BILQIS NURFATABelum ada peringkat
- Ukuran DispersiDokumen5 halamanUkuran Dispersi233402136Belum ada peringkat
- Multi Stage SampLingDokumen49 halamanMulti Stage SampLingempat september50% (2)
- Cluster 2 Tahap PDFDokumen35 halamanCluster 2 Tahap PDFDilaBelum ada peringkat
- Kelompok 9 - MakalahDokumen14 halamanKelompok 9 - MakalahLionel Fais100% (1)
- TSS S1 - M7 - 2020 - Materi Kuliah TSS - S1 Kelas A, C Dan D - Sampling SistematikDokumen5 halamanTSS S1 - M7 - 2020 - Materi Kuliah TSS - S1 Kelas A, C Dan D - Sampling SistematikIlmaf 313Belum ada peringkat
- Metode Kuadrat TerkecilDokumen35 halamanMetode Kuadrat TerkecilSalsabila Hana100% (1)
- Statistik Bose EinsteinDokumen6 halamanStatistik Bose EinsteinAoi Chiisai HoshiBelum ada peringkat
- Tugas BiostatistikDokumen13 halamanTugas BiostatistikNurfaidahBelum ada peringkat
- KesetimbanganDokumen10 halamanKesetimbanganLirihBelum ada peringkat
- Kisi Difraksi (Revisi)Dokumen2 halamanKisi Difraksi (Revisi)lol zzBelum ada peringkat
- Kelompok 2 - Analisis Kuantitatif BiofisikDokumen26 halamanKelompok 2 - Analisis Kuantitatif BiofisikANMABelum ada peringkat
- 3-PCAB RevDokumen17 halaman3-PCAB RevKhairun NisaBelum ada peringkat
- Distribusi SamplingDokumen10 halamanDistribusi Samplinglidia rosaBelum ada peringkat
- Kelompok 7 - MATEMATIKA II - Teknik SipilDokumen6 halamanKelompok 7 - MATEMATIKA II - Teknik SipilRangga YudhaBelum ada peringkat
- Merangkum Jurnal Metode Kuantitatif.Dokumen9 halamanMerangkum Jurnal Metode Kuantitatif.sonly nendiarieBelum ada peringkat
- Regresi Parametrik Dan Non-ParametrikDokumen16 halamanRegresi Parametrik Dan Non-Parametrikberto windi100% (3)
- Buku Panduan Praktikum Acara 3Dokumen5 halamanBuku Panduan Praktikum Acara 3desitaputriBelum ada peringkat
- Dret GeometriDokumen38 halamanDret Geometriclaudia toding alloBelum ada peringkat
- Analisis RealDokumen20 halamanAnalisis Realelpianus zendratoppknBelum ada peringkat
- StatistikaDokumen6 halamanStatistikaAlfi Syahri SBelum ada peringkat
- Simple Random SamplingDokumen21 halamanSimple Random SamplingRidho Illahi100% (1)
- 92 182 2 PBDokumen9 halaman92 182 2 PBjahro haniBelum ada peringkat
- Kalkulus Lanjut Pertemuan 2 Dan 3Dokumen14 halamanKalkulus Lanjut Pertemuan 2 Dan 3Ermayuliani TanjungBelum ada peringkat
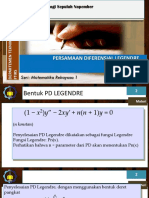
- M10.3 PD Legendre.Dokumen25 halamanM10.3 PD Legendre.Ilham FirmansyahBelum ada peringkat
- Teori Sampel - Perbandingan Perkiraan RasioDokumen6 halamanTeori Sampel - Perbandingan Perkiraan RasiohaedaeeBelum ada peringkat
- RegresiDokumen49 halamanRegresiAdriansyah WillyBelum ada peringkat
- Teori Principal Components Analysis (PCA)Dokumen12 halamanTeori Principal Components Analysis (PCA)Ayu PuriBelum ada peringkat
- Sats4210 M1 PDFDokumen44 halamanSats4210 M1 PDFErni D NadiahBelum ada peringkat
- Ratio, Regression, Dan Difference EstimationDokumen23 halamanRatio, Regression, Dan Difference Estimationbrond_chu651Belum ada peringkat
- Diskusi 1 Kalkulus 2 Adhistia 030485286Dokumen4 halamanDiskusi 1 Kalkulus 2 Adhistia 030485286Adhistia Lisharanova100% (1)
- TR 2 PDB Makalah Yosafat Pakpahan - 4182121009Dokumen17 halamanTR 2 PDB Makalah Yosafat Pakpahan - 4182121009SandikaBelum ada peringkat
- TR 2 PDB Makalah Yosafat Pakpahan - 4182121009Dokumen17 halamanTR 2 PDB Makalah Yosafat Pakpahan - 4182121009SandikaBelum ada peringkat
- Metode Kuadrat TerkecilDokumen7 halamanMetode Kuadrat TerkecilBoylesipahutar100% (2)
- RR Dengan FPBDokumen10 halamanRR Dengan FPBelaBelum ada peringkat
- Uji Manova Pada Data Kadar Bahan Pembuatan Asam SulfatDokumen14 halamanUji Manova Pada Data Kadar Bahan Pembuatan Asam SulfatMarinha Delboa100% (2)
- RagilSitanggang FisikaND 2018 TR-4 FisikaStatistikaDokumen2 halamanRagilSitanggang FisikaND 2018 TR-4 FisikaStatistikaRagil SitanggangBelum ada peringkat
- Maulina Putri Lestari - M0220052 - UTSPengolahSignalDigitalDokumen17 halamanMaulina Putri Lestari - M0220052 - UTSPengolahSignalDigitalMaulina Putri LestariBelum ada peringkat
- Soal StirlingDokumen5 halamanSoal StirlingMiss WandaBelum ada peringkat
- TK1 W3 S4 R1Dokumen1 halamanTK1 W3 S4 R1x47h2kBelum ada peringkat
- Makalah Deret PangkatDokumen11 halamanMakalah Deret PangkatMuhammadNanda0% (1)
- Statistik Maxwell BoltzmannDokumen10 halamanStatistik Maxwell BoltzmannnapisahBelum ada peringkat
- 8 - SVD DEcompositionDokumen27 halaman8 - SVD DEcompositionNa'ilah haninBelum ada peringkat
- Fungsi Invers TrigonometriDokumen20 halamanFungsi Invers TrigonometriSari setia NingrumBelum ada peringkat
- Soal Matematika SMA - Kaidah PencacahanDokumen65 halamanSoal Matematika SMA - Kaidah PencacahantrianaBelum ada peringkat
- Bab ViianovaDokumen55 halamanBab ViianovaRaudhatul JannahBelum ada peringkat
- Bahan Kasus Curve Fitting Dan Interpolasi Doc DyDokumen16 halamanBahan Kasus Curve Fitting Dan Interpolasi Doc Dydarnia anitaBelum ada peringkat
- Tipus Andes, Validitas, ReliabelDokumen6 halamanTipus Andes, Validitas, ReliabelMuhammad IhwalBelum ada peringkat
- ARTIKEL PENAKSIRAN TITIK Dan PERHITUNGAN RATA-RATADokumen10 halamanARTIKEL PENAKSIRAN TITIK Dan PERHITUNGAN RATA-RATAReny FebriyaniBelum ada peringkat
- Simple Random SamplingDokumen21 halamanSimple Random SamplingGary ChocolatosBelum ada peringkat
- MULTIVARIATDokumen5 halamanMULTIVARIATMutmainnah AzisBelum ada peringkat
- Jumlah Penumpang Pesawat Di Bandara UtamaDokumen3 halamanJumlah Penumpang Pesawat Di Bandara UtamaABDUL RASYID FAQIHBelum ada peringkat
- Jumlah Penumpang Pesawat Di Bandara UtamaDokumen3 halamanJumlah Penumpang Pesawat Di Bandara UtamaABDUL RASYID FAQIHBelum ada peringkat
- Jumlah Penumpang Pesawat Di Bandara UtamaDokumen3 halamanJumlah Penumpang Pesawat Di Bandara UtamaABDUL RASYID FAQIHBelum ada peringkat
- Jumlah Barang Yang Dimuat Di Bandara UtamaDokumen3 halamanJumlah Barang Yang Dimuat Di Bandara UtamaABDUL RASYID FAQIHBelum ada peringkat
- Jumlah Penumpang Pesawat Di Bandara UtamaDokumen3 halamanJumlah Penumpang Pesawat Di Bandara UtamaABDUL RASYID FAQIHBelum ada peringkat
- Desain SamplingDokumen43 halamanDesain SamplingABDUL RASYID FAQIHBelum ada peringkat
- Bab3 PDFDokumen7 halamanBab3 PDFResnaning Puji AstutiBelum ada peringkat
- PPS SamplingDokumen5 halamanPPS SamplingABDUL RASYID FAQIHBelum ada peringkat
- PPS SamplingDokumen3 halamanPPS SamplingABDUL RASYID FAQIHBelum ada peringkat
- Solusi OSK 2011Dokumen12 halamanSolusi OSK 2011Martin LoBelum ada peringkat
- Soal UAS Matematika II TPB Genap Tahun Ajaran 2017 2018Dokumen2 halamanSoal UAS Matematika II TPB Genap Tahun Ajaran 2017 2018ABDUL RASYID FAQIHBelum ada peringkat
- Solusi Osk Matematika Sma 2014 PDFDokumen8 halamanSolusi Osk Matematika Sma 2014 PDFCatherine Olivia SteintonBelum ada peringkat
- Solusi Osk Astro 2018Dokumen11 halamanSolusi Osk Astro 2018Melati Simamora100% (1)
- SoalDokumen6 halamanSoalABDUL RASYID FAQIHBelum ada peringkat
- Leaflet 6 PDFDokumen2 halamanLeaflet 6 PDFSariBelum ada peringkat
- Ktom AprilDokumen6 halamanKtom AprilLeon FoneBelum ada peringkat
- Bab2Dokumen21 halamanBab2Yung NugrohoBelum ada peringkat
- SoalDokumen6 halamanSoalMuhammad Alfaatih SalsabilaBelum ada peringkat
- Soal PDFDokumen5 halamanSoal PDFNayeolPcyBelum ada peringkat
- SoalDokumen7 halamanSoalABDUL RASYID FAQIHBelum ada peringkat
- Uji Goldfeld Dan BPGDokumen7 halamanUji Goldfeld Dan BPGABDUL RASYID FAQIHBelum ada peringkat
- Diktat KM IDokumen96 halamanDiktat KM IGhyta LIsna RahimBelum ada peringkat
- Fundamental Concept of HPDokumen28 halamanFundamental Concept of HPABDUL RASYID FAQIHBelum ada peringkat
- Uji White + GlejserDokumen3 halamanUji White + GlejserABDUL RASYID FAQIHBelum ada peringkat
- Pengujian Park Dan SpearmannDokumen3 halamanPengujian Park Dan SpearmannABDUL RASYID FAQIHBelum ada peringkat