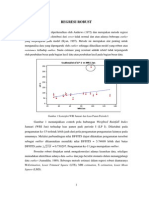
Anda mungkin juga menyukai
- Analisis Regresi Logistik MultinomialDokumen9 halamanAnalisis Regresi Logistik MultinomialHaidar Fahmi Riwa GiyantraBelum ada peringkat
- INFERENSI VEKTOR MEANDokumen38 halamanINFERENSI VEKTOR MEANYohani DSBelum ada peringkat
- 62 Modul Uts d4-StDokumen290 halaman62 Modul Uts d4-Stlooloo duaBelum ada peringkat
- Teori Regresi Logistik MultinomialDokumen12 halamanTeori Regresi Logistik Multinomialulya tsaniyaBelum ada peringkat
- Regresi Logistik BinerDokumen29 halamanRegresi Logistik BinerDalizanolo HuluBelum ada peringkat
- MODUL 1 Monte CarloDokumen20 halamanMODUL 1 Monte CarloREG.B/0516104008/MIZWAR TANJUNGBelum ada peringkat
- Laporan 6Dokumen27 halamanLaporan 6Vendri AsrinyBelum ada peringkat
- REGRESI ROBUSTDokumen21 halamanREGRESI ROBUSTPratama Yuly NugrahaBelum ada peringkat
- Analisis Regresi Peubah DummyDokumen23 halamanAnalisis Regresi Peubah DummyWomsiwor JosuaBelum ada peringkat
- Two Way Anova (Anova 2 Faktor)Dokumen3 halamanTwo Way Anova (Anova 2 Faktor)cahyowidodoBelum ada peringkat
- SMK_SMA_PapuaDokumen7 halamanSMK_SMA_PapuaFauziah MunifaBelum ada peringkat
- REGRESI SPASIALDokumen9 halamanREGRESI SPASIALRisnanda NaufalBelum ada peringkat
- VektorNilaiTengahDokumen26 halamanVektorNilaiTengahnur suhartinaBelum ada peringkat
- REGRESI ROBUST METODEDokumen9 halamanREGRESI ROBUST METODEfienkamaretaBelum ada peringkat
- Manual Mutu Ile BolengDokumen23 halamanManual Mutu Ile BolengMaryam MakingBelum ada peringkat
- Analisis SpasialDokumen35 halamanAnalisis SpasialFarisca Susiani100% (3)
- TK1 2 UJI MEDIAN - Rizky - RevisiDokumen17 halamanTK1 2 UJI MEDIAN - Rizky - RevisiAmira RanaBelum ada peringkat
- Buku Analisis Data Longitudinal PDFDokumen123 halamanBuku Analisis Data Longitudinal PDFFrima RggBelum ada peringkat
- Fungsi KontingensiDokumen16 halamanFungsi Kontingensiulya tsaniyaBelum ada peringkat
- INTERVAL KONFIDENSI UNTUK DUA PARAMETER DISTRIBUSI EKSPONENSIAL DI BAWAH SENSOR TIPE-II (Studi Kasus Data Waktu Tunggu Gempabumi Besar Di Indonesia)Dokumen12 halamanINTERVAL KONFIDENSI UNTUK DUA PARAMETER DISTRIBUSI EKSPONENSIAL DI BAWAH SENSOR TIPE-II (Studi Kasus Data Waktu Tunggu Gempabumi Besar Di Indonesia)Riswan Dwi RmdhantBelum ada peringkat
- Makalah Regresi Robust (Tiar Indarto G152144051)Dokumen10 halamanMakalah Regresi Robust (Tiar Indarto G152144051)Tiar IndartoBelum ada peringkat
- OPTIMIZED UJI PERMUTASI TITLEDokumen2 halamanOPTIMIZED UJI PERMUTASI TITLESitiJulaehhaBelum ada peringkat
- Analisis Asumpsi Distribusi Data dengan Q-Q PlotDokumen25 halamanAnalisis Asumpsi Distribusi Data dengan Q-Q PlotUzzi ZiqmaBelum ada peringkat
- Time Series - ARIMADokumen18 halamanTime Series - ARIMAarifBelum ada peringkat
- Mod Stat ContDokumen143 halamanMod Stat ContiwanBelum ada peringkat
- MODEL POISSON REGRESSIDokumen38 halamanMODEL POISSON REGRESSINusar HajarismanBelum ada peringkat
- Analisis Regresi Komponen UtamaDokumen16 halamanAnalisis Regresi Komponen UtamaLiya PermatasariBelum ada peringkat
- Resampling Dan Dalil Limit PusatDokumen6 halamanResampling Dan Dalil Limit PusatNurlita HalisyahBelum ada peringkat
- ARIMADokumen12 halamanARIMAMuhammad Arif DarmawanBelum ada peringkat
- Analisis Air MineralDokumen3 halamanAnalisis Air MineralMuhamad Alpin DwizahraBelum ada peringkat
- Pendugaan Parameter-Pertemuan Ke 3Dokumen21 halamanPendugaan Parameter-Pertemuan Ke 3FalasifaBelum ada peringkat
- Distribusi T2-Test Dan Aplikasi T2-TestDokumen15 halamanDistribusi T2-Test Dan Aplikasi T2-TestSusiBelum ada peringkat
- 10 Distribusi Probabilitas KontinyuDokumen11 halaman10 Distribusi Probabilitas KontinyuLukmanul ChakimBelum ada peringkat
- Manual Manova Dua Arah Tanpa Interaksi Kel 8Dokumen35 halamanManual Manova Dua Arah Tanpa Interaksi Kel 8nisrina puadBelum ada peringkat
- Estimasi Statistik dan Galat PendugaanDokumen1 halamanEstimasi Statistik dan Galat PendugaanAnnal FaizalBelum ada peringkat
- Nurwilda-Ringkasan Analisis Korelasi KanonikDokumen9 halamanNurwilda-Ringkasan Analisis Korelasi KanonikNur WildaBelum ada peringkat
- Uji Perbandingan BergandaDokumen12 halamanUji Perbandingan BergandaRizky Bagas ArdiansyahBelum ada peringkat
- Tugas 1 ADW ADokumen11 halamanTugas 1 ADW AAfifah Stat100% (1)
- UJI KRUSKAL-WALLISDokumen12 halamanUJI KRUSKAL-WALLISMuhammadsalBelum ada peringkat
- Revisi Uji Hipotesis 2 SampelDokumen26 halamanRevisi Uji Hipotesis 2 SampelFarisca SusianiBelum ada peringkat
- Estimator Parameter Model Regresi Linier Dengan Metode BootstrapDokumen14 halamanEstimator Parameter Model Regresi Linier Dengan Metode BootstrapFerra YanuarBelum ada peringkat
- HEBB ALGORITMADokumen11 halamanHEBB ALGORITMATaufik HidayatBelum ada peringkat
- Materi RBSLDokumen11 halamanMateri RBSLIrwan SaputraBelum ada peringkat
- Anreg Best SubsetDokumen14 halamanAnreg Best SubsetDwi Yanuar IlhamBelum ada peringkat
- Tugas Model LinierDokumen55 halamanTugas Model LinierNovi SetiaBelum ada peringkat
- Integral EksponensialDokumen4 halamanIntegral EksponensialArista WibowoBelum ada peringkat
- ANOVA SATU ARAHDokumen25 halamanANOVA SATU ARAHGloria Angelia TuelahBelum ada peringkat
- Materi 7 Desain Bujur Sangkar YoudenDokumen4 halamanMateri 7 Desain Bujur Sangkar YoudenGita NopitaBelum ada peringkat
- Grafik Pengendali Jumlah KumulatifDokumen13 halamanGrafik Pengendali Jumlah KumulatifESI SETYANIBelum ada peringkat
- Rantai Markov Waktu Diskrit (Elisabeth & Sari Yanti)Dokumen15 halamanRantai Markov Waktu Diskrit (Elisabeth & Sari Yanti)ida mariatiBelum ada peringkat
- MIDTERM STATISTIKADokumen2 halamanMIDTERM STATISTIKAMiftha huul jannahBelum ada peringkat
- Fungsi Turunan Tingkat TinggiDokumen3 halamanFungsi Turunan Tingkat TinggiAsapBelum ada peringkat
- REGRESI LOGIS BINERDokumen37 halamanREGRESI LOGIS BINEREdi Kurniawan50% (2)
- ppt3 RevDokumen11 halamanppt3 RevFozia ChannelBelum ada peringkat
- MANOVA Helm FootballDokumen12 halamanMANOVA Helm FootballMochammad NashihBelum ada peringkat
- REGRESILOGIT2CPROBIT2CTOBITDokumen7 halamanREGRESILOGIT2CPROBIT2CTOBITTri Anggita KuswardaniBelum ada peringkat
- REGLOGIDokumen20 halamanREGLOGIKyle WatersBelum ada peringkat
- Regresi Logistik OrdinalDokumen20 halamanRegresi Logistik OrdinalAbdullah Jabbar DaimuddinBelum ada peringkat
- ANALISIS PROBITDokumen21 halamanANALISIS PROBITDemitria Dini AriyaniBelum ada peringkat
- Ketentuan Penyusunan PPT Dan Presentasi PKLDokumen1 halamanKetentuan Penyusunan PPT Dan Presentasi PKLKyy AndiniBelum ada peringkat
- ST BPR BaruDokumen1 halamanST BPR BaruKyy AndiniBelum ada peringkat
- Matematika EkonomiDokumen225 halamanMatematika EkonomiIndy Novira74% (23)
- 6267 12149 1 SMDokumen15 halaman6267 12149 1 SMKyy AndiniBelum ada peringkat
- Skripsi PDFDokumen138 halamanSkripsi PDFakhmad ridhaniBelum ada peringkat
- Modul 14 Diagram Kontrol UnivariatDokumen15 halamanModul 14 Diagram Kontrol UnivariatKyy AndiniBelum ada peringkat
- 805 1522 1 SMDokumen18 halaman805 1522 1 SMKyy AndiniBelum ada peringkat
- Ketentuan Penyusunan PPT Dan Presentasi PKLDokumen1 halamanKetentuan Penyusunan PPT Dan Presentasi PKLKyy AndiniBelum ada peringkat
- FUNGSI NON LINEARDokumen20 halamanFUNGSI NON LINEARKyy Andini0% (2)
- Jurnal Bindo - Pak SukarnaDokumen10 halamanJurnal Bindo - Pak SukarnaKyy AndiniBelum ada peringkat
- 06 Barisan Dan LimitnyaDokumen8 halaman06 Barisan Dan LimitnyaKyy AndiniBelum ada peringkat
- Makalah IdeologiDokumen9 halamanMakalah IdeologiKyy AndiniBelum ada peringkat
- 06 Barisan Dan LimitnyaDokumen8 halaman06 Barisan Dan LimitnyaKyy AndiniBelum ada peringkat
- 3 3 10 1 10 20180108 PDFDokumen142 halaman3 3 10 1 10 20180108 PDFMade Dwi JuniarthaBelum ada peringkat
- Aplikasi KekongruenanDokumen2 halamanAplikasi KekongruenanKyy AndiniBelum ada peringkat
- Distribusi PeluangDokumen50 halamanDistribusi PeluangKyy AndiniBelum ada peringkat
- Poin Rencana StudiDokumen10 halamanPoin Rencana StudiKyy AndiniBelum ada peringkat
- EJAAN BAKUDokumen37 halamanEJAAN BAKUKyy AndiniBelum ada peringkat
- Presentation 3Dokumen6 halamanPresentation 3Kyy AndiniBelum ada peringkat
- Poin Rencana StudiDokumen10 halamanPoin Rencana StudiKyy AndiniBelum ada peringkat
- SejarahhpptDokumen7 halamanSejarahhpptKyy AndiniBelum ada peringkat
- PEMBAHASANDokumen17 halamanPEMBAHASANmuhammad lutfihBelum ada peringkat
- Daftar IsiplhDokumen1 halamanDaftar IsiplhKyy AndiniBelum ada peringkat