Anda mungkin juga menyukai
- Time Series AnalysisDokumen3 halamanTime Series AnalysisLahul RespectBelum ada peringkat
- Rangkuman AutokorelasiDokumen7 halamanRangkuman AutokorelasiNur Alfi SyahriBelum ada peringkat
- Kointegrasi Dan Estimasi Ecm Pada Data Time Series: Y X Y XDokumen13 halamanKointegrasi Dan Estimasi Ecm Pada Data Time Series: Y X Y XMuhammad Ikhsan ZABelum ada peringkat
- Multikolinearitas PDFDokumen11 halamanMultikolinearitas PDFSonya Eki Santoso67% (3)
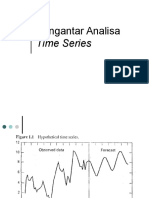
- 5 - Pengantar Analisa Time SeriesDokumen25 halaman5 - Pengantar Analisa Time SerieskukuhBelum ada peringkat
- 5 - Pengantar Analisa Time SeriesDokumen25 halaman5 - Pengantar Analisa Time SerieskukuhBelum ada peringkat
- Dasar Analisis BerkalaDokumen27 halamanDasar Analisis Berkalakurnia millati100% (1)
- Diskusi 4 Ekonomi ManajerialDokumen3 halamanDiskusi 4 Ekonomi Manajerialabdul rikiBelum ada peringkat
- Rangkuman Sinyal SistemDokumen19 halamanRangkuman Sinyal SistemNanda FinalisBelum ada peringkat
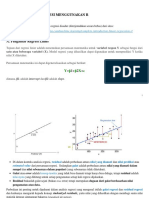
- Pemodelan RegresiDokumen31 halamanPemodelan RegresiAl ElBelum ada peringkat
- StatistikDokumen10 halamanStatistikRudiyanto RudiBelum ada peringkat
- Data PanelDokumen19 halamanData PanelAndreaz PanjaitanBelum ada peringkat
- UAS Ekonometrika - Ld. Muh. Yusuf Marsal - D1A118133Dokumen7 halamanUAS Ekonometrika - Ld. Muh. Yusuf Marsal - D1A118133DhembuBelum ada peringkat
- Model StasioneritasDokumen8 halamanModel StasioneritasKezia GabrielleBelum ada peringkat
- Minggu 6 Peramalan Time Series Metode ARIMADokumen25 halamanMinggu 6 Peramalan Time Series Metode ARIMAIsya NafiaBelum ada peringkat
- AUTOKORELASIDokumen5 halamanAUTOKORELASIYusnandaMadridtistaBelum ada peringkat
- ArtikelDokumen10 halamanArtikelArfiyansyah RizkiBelum ada peringkat
- Time SeriesDokumen25 halamanTime SeriesKaka Ramdhan Oli'iBelum ada peringkat
- Asumsi KlasikDokumen35 halamanAsumsi KlasikHuzi Mahdi AttamimiBelum ada peringkat
- Persistensi Inflasi Di IndonesiaDokumen7 halamanPersistensi Inflasi Di Indonesiafajarakatsuki86Belum ada peringkat
- Panel Data Regression ModelDokumen14 halamanPanel Data Regression ModelNurhidayati SeptianBelum ada peringkat
- Analisis Regresi SpasialDokumen5 halamanAnalisis Regresi SpasialPolycarpusBelum ada peringkat
- 11 AutocorrelationDokumen12 halaman11 AutocorrelationmbunlalalaBelum ada peringkat
- Makalah Regresi LinearDokumen23 halamanMakalah Regresi LinearSri Wahyuni Sumadi83% (6)
- LA MODUL1 TGD 120120067 Ahmad Dhany ErlanggaDokumen79 halamanLA MODUL1 TGD 120120067 Ahmad Dhany ErlanggaVivinBelum ada peringkat
- 02 Pengantar Proses Stasioner NewDokumen28 halaman02 Pengantar Proses Stasioner Newrio tisnaBelum ada peringkat
- Robust RegressionDokumen15 halamanRobust RegressionCahaya NingsihBelum ada peringkat
- Modul 4. Model-Model Nonstasioner KomplitDokumen13 halamanModul 4. Model-Model Nonstasioner KomplitOktavianus Eko AdiNugrohoBelum ada peringkat
- Kul 2 Random Walk GaussionDokumen32 halamanKul 2 Random Walk GaussionFanesa Prousvaliza100% (1)
- Time SeriesDokumen2 halamanTime SeriesCin AaisahBelum ada peringkat
- Tugas Fungsi TransferDokumen6 halamanTugas Fungsi TransferSoraya YulianaBelum ada peringkat
- Analisis Regresi (Presentasi)Dokumen9 halamanAnalisis Regresi (Presentasi)RiSky SukMa W. MangaHolic100% (1)
- Lag TerdistribusikanDokumen10 halamanLag Terdistribusikanwahyu griyaBelum ada peringkat
- Distribusi Lag Dan Distribusi AutoregressiveDokumen15 halamanDistribusi Lag Dan Distribusi AutoregressiveAgungHndokoBelum ada peringkat
- ID Pemodelan Markov Switching AutoregressivDokumen10 halamanID Pemodelan Markov Switching AutoregressivMR ARIFINBelum ada peringkat
- Pencilan DLM RegresiDokumen30 halamanPencilan DLM Regresiikin sodikinBelum ada peringkat
- Endogenitas PDFDokumen15 halamanEndogenitas PDF12_7185Belum ada peringkat
- Analisis Regresi Menggunakan RDokumen45 halamanAnalisis Regresi Menggunakan RHamim SudarsonoBelum ada peringkat
- Metode PeramalanDokumen12 halamanMetode Peramalandelvica salsabilaBelum ada peringkat
- Ekonometrika StasioneritasDokumen47 halamanEkonometrika StasioneritasFadli SeptiantoBelum ada peringkat
- Lampiran Model Analisis Peramalan PenumpangDokumen35 halamanLampiran Model Analisis Peramalan PenumpangDodhy Akbar Angga FitrianBelum ada peringkat
- Markov Chains - Kelompok 6Dokumen16 halamanMarkov Chains - Kelompok 6ZulehaBelum ada peringkat
- Analisis Pada Sistem1Dokumen24 halamanAnalisis Pada Sistem1jujuBelum ada peringkat
- Statmat Materi TFDokumen42 halamanStatmat Materi TFISL MMBelum ada peringkat
- 2021B-Modul ARMA Dan ARIMA-PurwantoDokumen54 halaman2021B-Modul ARMA Dan ARIMA-Purwantopurwantowidodo3884Belum ada peringkat
- Statistical ModelDokumen21 halamanStatistical ModelTeguh MahardikaBelum ada peringkat
- Bab IiDokumen38 halamanBab IiUci Marlina PasaribuBelum ada peringkat
- Makalah Sistem LinierDokumen12 halamanMakalah Sistem LinierSayyid HibbanBelum ada peringkat
- Makalah Proses StokastikDokumen9 halamanMakalah Proses StokastikNinin50% (2)
- Prak SinyalSistem 2Dokumen22 halamanPrak SinyalSistem 2Meilody IndreswariBelum ada peringkat
- MODUL 2 - Pengolahan SinyalDokumen22 halamanMODUL 2 - Pengolahan SinyalShafwah AnugrahBelum ada peringkat
- Bab2-06305149010 (1) SDokumen20 halamanBab2-06305149010 (1) Sditha'08Belum ada peringkat
- Analisis Time Series Terhadap Saham Bank BNI (Ok)Dokumen22 halamanAnalisis Time Series Terhadap Saham Bank BNI (Ok)icha_ismailBelum ada peringkat
- Penelitian Operasi MiliterDokumen32 halamanPenelitian Operasi MiliterKianAlvaroSachioRajendraBelum ada peringkat
- Analisis Regresi Linear SederhanaDokumen19 halamanAnalisis Regresi Linear Sederhanabeni_rezpector100% (2)
- Sinyal Dan Sistem Waktu DiskritDokumen28 halamanSinyal Dan Sistem Waktu DiskritYosep TaraBelum ada peringkat
- Sinyal Waktu KontinyuDokumen22 halamanSinyal Waktu KontinyuRachel FirchellBelum ada peringkat
- Garuda Indonesia Merupakan Perusahaan Go Public Yang Melaporkan Kinerja Keuangan Tahun Buku 2018 Kepada Bursa Efek IndonesiaDokumen6 halamanGaruda Indonesia Merupakan Perusahaan Go Public Yang Melaporkan Kinerja Keuangan Tahun Buku 2018 Kepada Bursa Efek IndonesiaffunnyfriendsBelum ada peringkat
- Sia Bab 3Dokumen3 halamanSia Bab 3ffunnyfriendsBelum ada peringkat
- 13 SiaDokumen3 halaman13 SiaffunnyfriendsBelum ada peringkat
- Penuntut Umum Dan WewenangnyaDokumen4 halamanPenuntut Umum Dan WewenangnyaffunnyfriendsBelum ada peringkat
- Programme, UNDP, 1990)Dokumen2 halamanProgramme, UNDP, 1990)ffunnyfriendsBelum ada peringkat
- Pengujian Substantif Atas Saldo KasDokumen2 halamanPengujian Substantif Atas Saldo KasffunnyfriendsBelum ada peringkat
- 01 - Migration Ability and Audit Quality - En.idDokumen63 halaman01 - Migration Ability and Audit Quality - En.idffunnyfriendsBelum ada peringkat
- Simbis VinylDokumen10 halamanSimbis VinylffunnyfriendsBelum ada peringkat
- Etbis HB FullerDokumen4 halamanEtbis HB FullerffunnyfriendsBelum ada peringkat
- Sistem Peradilan Pidana ViiiDokumen10 halamanSistem Peradilan Pidana ViiiffunnyfriendsBelum ada peringkat
- Etbis HB FullerDokumen4 halamanEtbis HB FullerffunnyfriendsBelum ada peringkat
- Tugas BonsDokumen1 halamanTugas BonsffunnyfriendsBelum ada peringkat
- Corporate Governance Sap 1Dokumen4 halamanCorporate Governance Sap 1ffunnyfriendsBelum ada peringkat
- Utang PajakDokumen13 halamanUtang PajakffunnyfriendsBelum ada peringkat
- Upaya Paksa Dalam Hukum Acara PidanaDokumen16 halamanUpaya Paksa Dalam Hukum Acara Pidanaffunnyfriends100% (1)
- Bab 12.2Dokumen1 halamanBab 12.2ffunnyfriendsBelum ada peringkat
- Poyok Dan DodikDokumen7 halamanPoyok Dan DodikffunnyfriendsBelum ada peringkat
- Aspek Keperilakuan Pada Pengakumulasian Dan Pengendalian BiayaDokumen7 halamanAspek Keperilakuan Pada Pengakumulasian Dan Pengendalian Biayakevinlikekrisus100% (1)
- Akpri Bab 2Dokumen6 halamanAkpri Bab 2ffunnyfriendsBelum ada peringkat
- Binter BaruDokumen8 halamanBinter BaruffunnyfriendsBelum ada peringkat
- Bab 12.1Dokumen1 halamanBab 12.1ffunnyfriendsBelum ada peringkat
- Audit 11Dokumen4 halamanAudit 11ffunnyfriendsBelum ada peringkat
- Bahan Kuliah 13-14Dokumen20 halamanBahan Kuliah 13-14ffunnyfriendsBelum ada peringkat
- Akpri Bab 1Dokumen7 halamanAkpri Bab 1ffunnyfriendsBelum ada peringkat
- Sistem Peradilan Pidana ViiDokumen2 halamanSistem Peradilan Pidana ViiffunnyfriendsBelum ada peringkat
- Ida Komang Angga D.Dokumen1 halamanIda Komang Angga D.ffunnyfriendsBelum ada peringkat
- Simbis VinylDokumen10 halamanSimbis VinylffunnyfriendsBelum ada peringkat
- Aak Kelompok 6Dokumen17 halamanAak Kelompok 6ffunnyfriendsBelum ada peringkat
- Ida Komang Angga D.Dokumen1 halamanIda Komang Angga D.ffunnyfriendsBelum ada peringkat