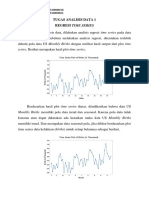
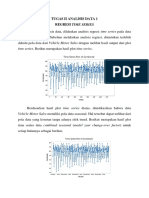
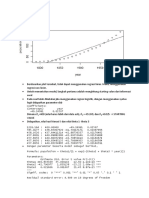
Anda mungkin juga menyukai
- 1 PBDokumen8 halaman1 PBrefina mutiaBelum ada peringkat
- ARTIKEL Sesi 3Dokumen9 halamanARTIKEL Sesi 3Stepanus PasaribuBelum ada peringkat
- 2603-Article Text-4176-1-10-20221206Dokumen7 halaman2603-Article Text-4176-1-10-20221206mbotaaBelum ada peringkat
- Analisis Cluster Menggunakan K-MeansDokumen18 halamanAnalisis Cluster Menggunakan K-MeansNur RahmatBelum ada peringkat
- Analisis Cluster Terhadap Kecamatan-Kecamatan Di Kabupaten Jepara, Jawa TengahDokumen17 halamanAnalisis Cluster Terhadap Kecamatan-Kecamatan Di Kabupaten Jepara, Jawa TengahIzzah KhusnaBelum ada peringkat
- 4782-Research Instrument-10866-1-10-20180502Dokumen9 halaman4782-Research Instrument-10866-1-10-20180502Dini AgustiwiBelum ada peringkat
- Replikasi Jurnal Metode K MeansDokumen25 halamanReplikasi Jurnal Metode K MeansajengfiryalhBelum ada peringkat
- Analisis Cluster, Analisis Diskriminan & Analisis Komponen UtamaDokumen7 halamanAnalisis Cluster, Analisis Diskriminan & Analisis Komponen UtamaFerry Oloan NadeakBelum ada peringkat
- 659 1907 1 PBDokumen7 halaman659 1907 1 PBIni Namanya IqbalBelum ada peringkat
- Analisis Cluster Studi Kasus - Kabupaten Jepara Jawa TengahDokumen17 halamanAnalisis Cluster Studi Kasus - Kabupaten Jepara Jawa TengahTaufiq HidayatBelum ada peringkat
- Paper TPDMDokumen6 halamanPaper TPDMwulanfasaBelum ada peringkat
- Analisis ClusterDokumen21 halamanAnalisis Clustermeliawww27Belum ada peringkat
- KLUSTER KESEJAHTERAANDokumen29 halamanKLUSTER KESEJAHTERAANAsmaida ShalehBelum ada peringkat
- MAKALAH Analisis ClusterDokumen12 halamanMAKALAH Analisis ClusterAnita SarmilaBelum ada peringkat
- Tugas Minggu 6 Analisis Diskriminan - Hafid Gisen Parastra (22081019)Dokumen4 halamanTugas Minggu 6 Analisis Diskriminan - Hafid Gisen Parastra (22081019)Hafid Gisen ParastraBelum ada peringkat
- MAP ClusterDokumen2 halamanMAP ClusterBagusBudiPrabowoBelum ada peringkat
- K-MEANS CLUSTERING UNTUK MENGELOMPOKKAN KABUPATEN BERDASARKAN JUMLAH BALITA BERMASALAHDokumen8 halamanK-MEANS CLUSTERING UNTUK MENGELOMPOKKAN KABUPATEN BERDASARKAN JUMLAH BALITA BERMASALAHNUR AINUNGBelum ada peringkat
- ANALISIS PENGELOMPOKAN DESA TERTINGGAL DI KABUPATEN KUTAI TIMUR DENGAN PENDEKATAN METODE K-MEANS DAN CENTROID LINKAGE (Minkowski Distance Measure)Dokumen12 halamanANALISIS PENGELOMPOKAN DESA TERTINGGAL DI KABUPATEN KUTAI TIMUR DENGAN PENDEKATAN METODE K-MEANS DAN CENTROID LINKAGE (Minkowski Distance Measure)Adi WijayaBelum ada peringkat
- Data Mining Untuk Klasifikasi Status Giz bf7b7f9cDokumen7 halamanData Mining Untuk Klasifikasi Status Giz bf7b7f9cEnda DwikiBelum ada peringkat
- Laporan Praktikum 2 Analisis ClusterDokumen13 halamanLaporan Praktikum 2 Analisis ClusterEster ParmanesBelum ada peringkat
- Analisis Cluster - Aditya Purnomo AjiDokumen3 halamanAnalisis Cluster - Aditya Purnomo AjiAdit AjiBelum ada peringkat
- Ujian Tengah SemesterDokumen4 halamanUjian Tengah SemesterAnnisa HumairaBelum ada peringkat
- Analisis ClusterDokumen16 halamanAnalisis ClusterkisnaBelum ada peringkat
- Bab I PDFDokumen16 halamanBab I PDFDiana AndriyaniBelum ada peringkat
- Analisis Faktor Dan Analisis ClusterDokumen36 halamanAnalisis Faktor Dan Analisis Clusterannisaromadhani75% (4)
- Laporan Klasterisasi Kasus Penyakit Malaria Di Indonesia Pada Tahun 2013 - 2015Dokumen10 halamanLaporan Klasterisasi Kasus Penyakit Malaria Di Indonesia Pada Tahun 2013 - 2015Ez AloneBelum ada peringkat
- Perbandingan Kualitas Hasil Klaster Algoritme K-Means Dan Isodata Pada Data Komposisi Bahan MakananDokumen9 halamanPerbandingan Kualitas Hasil Klaster Algoritme K-Means Dan Isodata Pada Data Komposisi Bahan MakananFabil AlbarruBelum ada peringkat
- K-MEANS CLUSTERDokumen37 halamanK-MEANS CLUSTERDian PratiwiBelum ada peringkat
- Bab IDokumen17 halamanBab IDiana AndriyaniBelum ada peringkat
- Jurnal - Sarjum Bao - F1A118018-1Dokumen11 halamanJurnal - Sarjum Bao - F1A118018-1Sarjum BaoBelum ada peringkat
- ANALISISDokumen18 halamanANALISISBETRAND FINSEN LENGKONGBelum ada peringkat
- Analisis Cluster FixxxDokumen22 halamanAnalisis Cluster Fixxxelvingky agustaniBelum ada peringkat
- Implementasi Data Mining Untuk Penentuan Penerima Beasiswa Santri Pada Pondok Pesantren Tarbiyatut Thullab Soko Tuban Menggunakan Algoritma K-Means ClusteringDokumen7 halamanImplementasi Data Mining Untuk Penentuan Penerima Beasiswa Santri Pada Pondok Pesantren Tarbiyatut Thullab Soko Tuban Menggunakan Algoritma K-Means ClusteringKhoirul AnwarBelum ada peringkat
- Makalah Statistika Multivariat .Dokumen14 halamanMakalah Statistika Multivariat .fadhuli norma wantiBelum ada peringkat
- Sistem Pengolahan Data PendudukDokumen10 halamanSistem Pengolahan Data Penduduksella anitaBelum ada peringkat
- 3237-Article Text-12670-1-10-20211014Dokumen8 halaman3237-Article Text-12670-1-10-20211014Hamim ArsyBelum ada peringkat
- TR StatistikDokumen2 halamanTR StatistikRindy Endry YaniBelum ada peringkat
- Analisis ClusterDokumen6 halamanAnalisis ClusterJerzi DjaisBelum ada peringkat
- Jurnal GedenDokumen7 halamanJurnal GedenBoyBelum ada peringkat
- Garuda 906408Dokumen4 halamanGaruda 906408Wisnu JatiBelum ada peringkat
- K Means ArdiansyahDokumen12 halamanK Means ArdiansyahArdiansyahBelum ada peringkat
- Muhammad Mustaghfirin - 24050117130058Dokumen10 halamanMuhammad Mustaghfirin - 24050117130058Hananta TriatmajaBelum ada peringkat
- (ZUlfikar, & Amidi 2022) MultikolinearitasDokumen9 halaman(ZUlfikar, & Amidi 2022) MultikolinearitasIlmi NazilaBelum ada peringkat
- OPTIMALKAN_STATUS_GIZIDokumen20 halamanOPTIMALKAN_STATUS_GIZIIndra GunawanBelum ada peringkat
- Analisis K-MeansDokumen5 halamanAnalisis K-MeansFAZLY QAIS FEBRIYANTO mhsD3KL2020RBelum ada peringkat
- Analisis Regresi Multivariat Untuk Mengetahui Derajat Kesehatan di Provinsi Kalimantan SelatanDokumen25 halamanAnalisis Regresi Multivariat Untuk Mengetahui Derajat Kesehatan di Provinsi Kalimantan SelatanAlfin Dratama maulanaBelum ada peringkat
- Analisis Multivariat Dengan Menggunakan Cluster HierarkiDokumen12 halamanAnalisis Multivariat Dengan Menggunakan Cluster Hierarkiluthfi misrawiBelum ada peringkat
- Cluster Non HirarkiDokumen24 halamanCluster Non HirarkiAldila Sakinah Putri100% (3)
- Modul Uji DeskriptifDokumen22 halamanModul Uji DeskriptifDadang SomantriBelum ada peringkat
- Algoritma K-Means Untuk Klasifikasi Provinsi Di Indonesia Berdasarkan Paket Pelayanan StuntingDokumen6 halamanAlgoritma K-Means Untuk Klasifikasi Provinsi Di Indonesia Berdasarkan Paket Pelayanan StuntingRahmat CpohanBelum ada peringkat
- Putri Alya Maharani Millenia_220210072_T.informatikaDokumen12 halamanPutri Alya Maharani Millenia_220210072_T.informatikaputrialyamaharanimilleniaBelum ada peringkat
- Skrip SiDokumen17 halamanSkrip SiAtina FaizahBelum ada peringkat
- 45035-Article Text-123555-1-10-20210319Dokumen9 halaman45035-Article Text-123555-1-10-20210319Harukainata DriveBelum ada peringkat
- Analisis Cluster dan Analisis DiskriminanDokumen5 halamanAnalisis Cluster dan Analisis DiskriminanHanifah Cindy PratiwiBelum ada peringkat
- ClusteringDokumen6 halamanClusteringDesy SandraBelum ada peringkat
- PengklasifikasianDokumen13 halamanPengklasifikasianHabib HamdzaniBelum ada peringkat
- Analisis Cluster (Pengelompokan) : Praktikum 2 Mata Kuliah Metode Analisis Perencanaan IiDokumen9 halamanAnalisis Cluster (Pengelompokan) : Praktikum 2 Mata Kuliah Metode Analisis Perencanaan Iinabilah.120220127Belum ada peringkat
- 2.2 Tinjauan Pustaka 2.1.1 Pengertian Clustring Menurut Widodo (2013) Tentang Clustring Yang Dikutip Dari JurnalDokumen3 halaman2.2 Tinjauan Pustaka 2.1.1 Pengertian Clustring Menurut Widodo (2013) Tentang Clustring Yang Dikutip Dari Jurnalagil sujatmikoBelum ada peringkat
- Uji Beda DLM Statistik SosialDokumen9 halamanUji Beda DLM Statistik Sosialdiva salsaBelum ada peringkat
- Practice Exercises of Survival AnalysisDokumen6 halamanPractice Exercises of Survival AnalysisanshfBelum ada peringkat
- Revolusi Industri di IndonesiaDokumen3 halamanRevolusi Industri di IndonesiaanshfBelum ada peringkat
- Chi-Square Test For Association: Ras Worksheet ColumnsDokumen4 halamanChi-Square Test For Association: Ras Worksheet ColumnsanshfBelum ada peringkat
- Analisis SurvivalDokumen9 halamanAnalisis SurvivalanshfBelum ada peringkat
- In A Vuca WorldDokumen11 halamanIn A Vuca WorldanshfBelum ada peringkat
- AbbreviationDokumen52 halamanAbbreviationanshfBelum ada peringkat
- BCGDokumen70 halamanBCGanshfBelum ada peringkat
- Regresi Time SeriesDokumen4 halamanRegresi Time SeriesanshfBelum ada peringkat
- Peta KendaliDokumen30 halamanPeta KendalianshfBelum ada peringkat
- ManovaDokumen8 halamanManovaanshfBelum ada peringkat
- Analisis Keputusan BisnisDokumen124 halamanAnalisis Keputusan BisnisanshfBelum ada peringkat
- Faktor Pada Cakupan Imunisasi TT (Tetanus Toxoid) Ibu Hamil Di Provinsi Jambi Tahun 2007Dokumen6 halamanFaktor Pada Cakupan Imunisasi TT (Tetanus Toxoid) Ibu Hamil Di Provinsi Jambi Tahun 2007anshfBelum ada peringkat
- Timeseries RegDokumen5 halamanTimeseries ReganshfBelum ada peringkat
- 19april ADDokumen2 halaman19april ADanshfBelum ada peringkat
- EKONDokumen10 halamanEKONanshfBelum ada peringkat
- EwmaDokumen31 halamanEwmaanshfBelum ada peringkat
- Ringkasan Teori Pengantar MakroekonomiDokumen84 halamanRingkasan Teori Pengantar MakroekonomiFarida Kofa72% (18)
- Temporal Basis FunctionsDokumen6 halamanTemporal Basis FunctionsanshfBelum ada peringkat
- Vlog Trend Baru BersosialisasiDokumen1 halamanVlog Trend Baru BersosialisasianshfBelum ada peringkat
- OPTIMALISASI PENGGANTIAN ASETDokumen17 halamanOPTIMALISASI PENGGANTIAN ASETNina ZaydaBelum ada peringkat
- Job Preparation TrainingDokumen2 halamanJob Preparation TraininganshfBelum ada peringkat
- Report 2 ADDokumen4 halamanReport 2 ADanshfBelum ada peringkat
- Peta KendaliDokumen30 halamanPeta KendalianshfBelum ada peringkat
- Temporal Basis FunctionsDokumen6 halamanTemporal Basis FunctionsanshfBelum ada peringkat
- Report 2 ADDokumen4 halamanReport 2 ADanshfBelum ada peringkat
- Analisis Data (Report)Dokumen6 halamanAnalisis Data (Report)anshfBelum ada peringkat
- Data AnalysisDokumen6 halamanData AnalysisanshfBelum ada peringkat
- Kebijakan Tax AmnestyDokumen1 halamanKebijakan Tax AmnestyanshfBelum ada peringkat
- Deneb PinkDokumen10 halamanDeneb PinkanshfBelum ada peringkat